Site Reliability Engineering (SRE) has evolved from a Google-originated concept into a mission-critical function for modern digital infrastructure. In 2026, reliability is directly tied to revenue, customer experience, and compliance making SRE one of the most strategic engineering roles for global enterprises.
Hire Site Reliability Engineers in India is now a top priority for GCCs and product companies building highly scalable, always-on systems. SREs bridge software engineering and operations by automating infrastructure, defining service level objectives (SLOs), and building observability systems that prevent downtime before it impacts users.
The urgency is backed by global data. According to Statista, the global public cloud market is projected to exceed $900 billion by 2026, significantly increasing the need for reliability engineering at scale:
As cloud adoption accelerates across GCCs in India, demand for skilled SRE talent continues to outpace supply, making it one of the most competitive hiring segments in the tech ecosystem.
What Site Reliability Engineering Actually Is
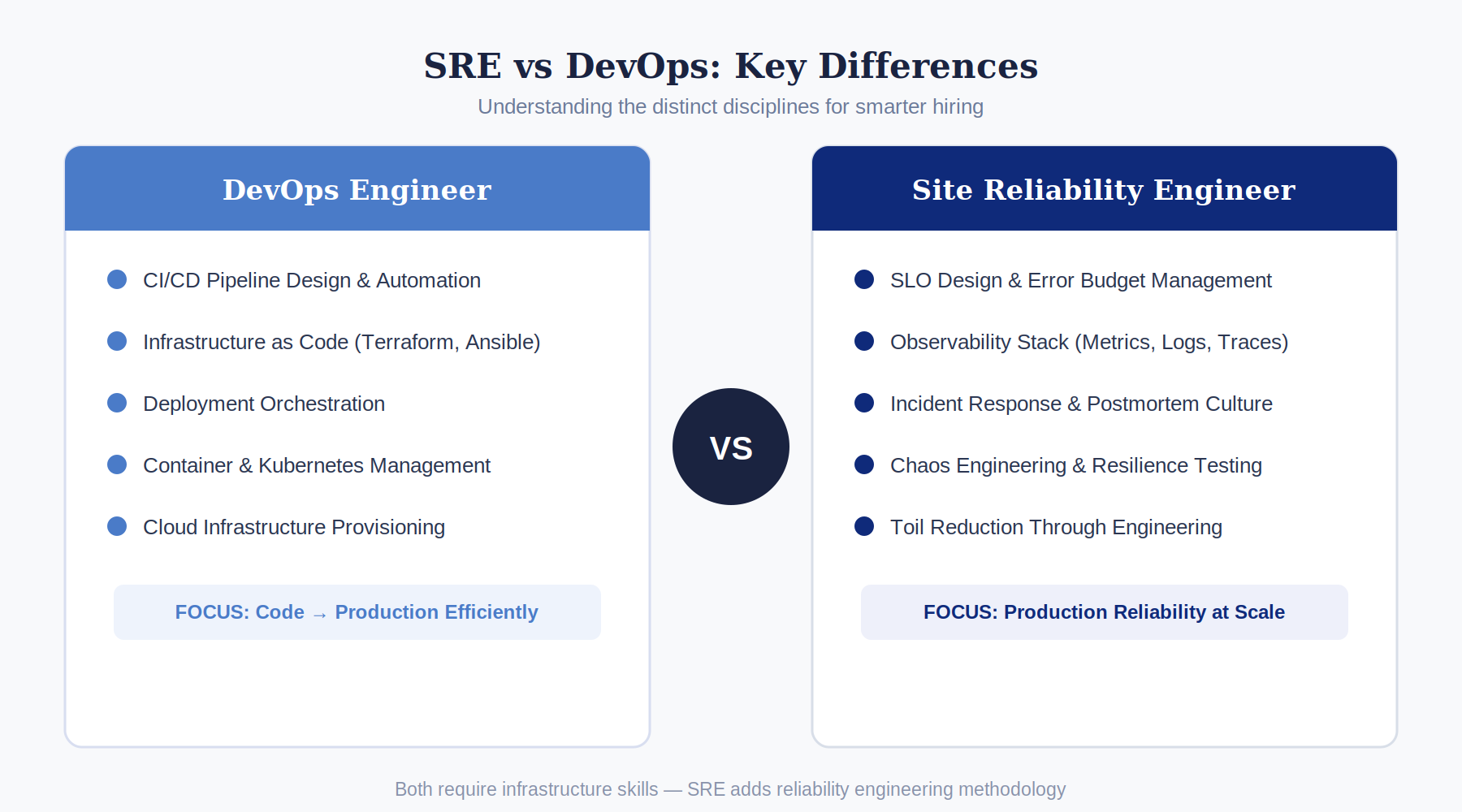
The most common hiring misconception about SRE is that it is senior DevOps with a different title. It is not. The distinction matters for hiring.
DevOps engineers focus on CI/CD pipeline design, infrastructure as code, and deployment automation, the process of getting code from a developer’s machine to production efficiently. SREs focus on the reliability of what is already in production, defining what reliability means (SLOs), measuring it (error budgets, SLIs), improving it (toil reduction, postmortem-driven engineering), and maintaining it under failure conditions (incident response, chaos engineering).
The overlap is real. Senior SREs need to understand infrastructure, CI/CD pipelines, and IaC. But the SRE-specific skills SLO design and error budget management, structured incident response and postmortem methodology, chaos engineering, and the reliability engineering mindset that drives automation of operational work are distinct from DevOps skills.
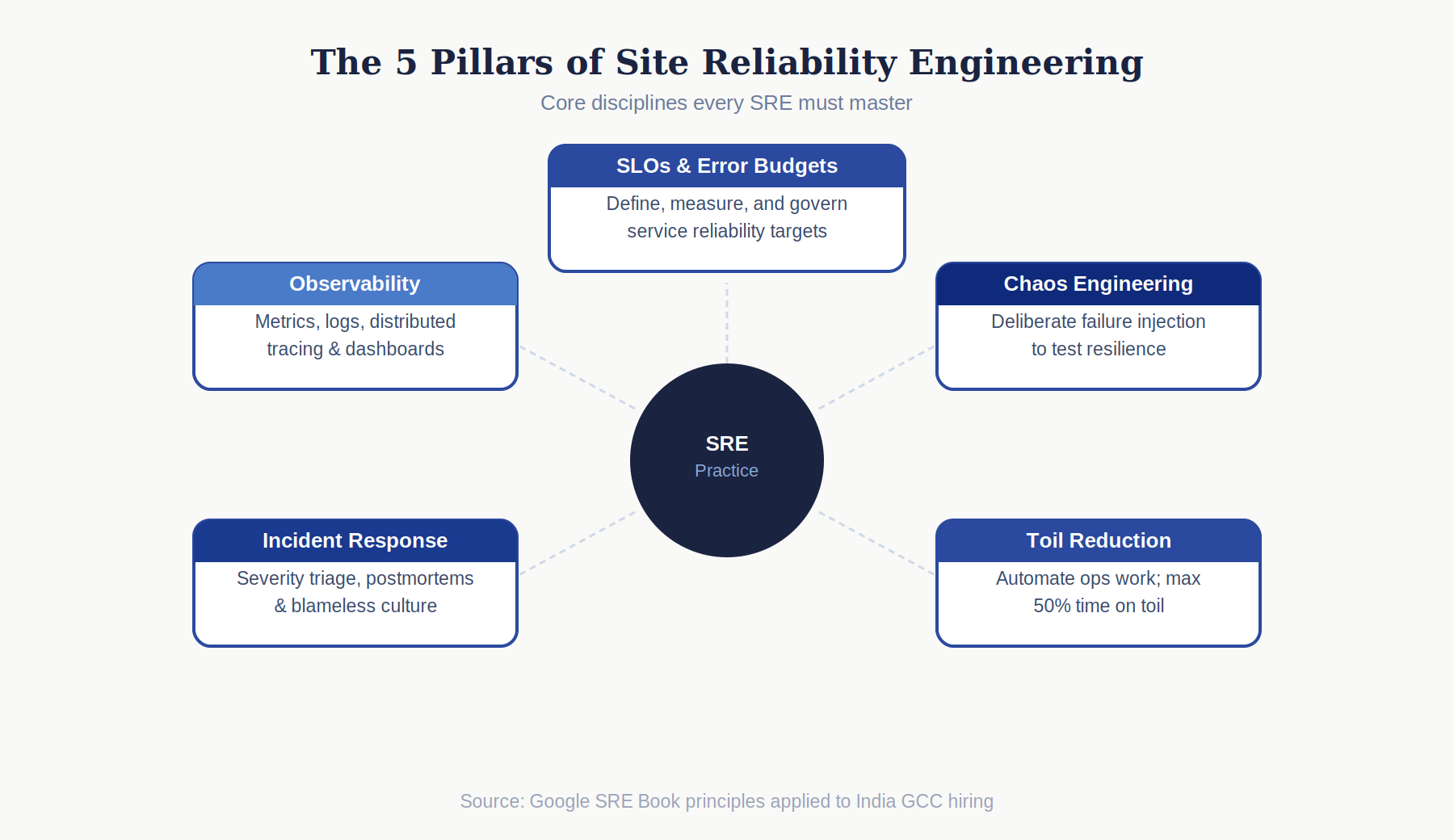
Service Level Objectives (SLOs) and Error Budgets are the foundational SRE concept. An SLO defines the target reliability for a service 99.9% availability, 100ms 95th percentile latency, 99.5% successful request rate. The error budget is the allowable unreliability difference between 100% and the SLO. Error budgets create a shared language between SREs and product teams: when the error budget is healthy, teams can move fast and take risks.
When it is nearly exhausted, reliability work takes priority over feature development. SREs who cannot design SLOs, calculate error budgets from SLIs (Service Level Indicators), and use error budget burn rate to drive engineering prioritization are not operating at the SRE discipline level.
Observability architecture the combination of metrics, structured logging, and distributed tracing that gives engineering teams visibility into production system behavior. Prometheus and Grafana for metrics. Elasticsearch, Loki, or Splunk for log aggregation and analysis. Jaeger, Zipkin, or AWS X-Ray for distributed tracing across microservices. OpenTelemetry for vendor-agnostic instrumentation.
An SRE who cannot design an observability stack for a microservices architecture defining what to instrument, what metrics matter for SLO monitoring, how to design meaningful dashboards, and how to configure alerting that pages the right team for the right severity cannot build the visibility infrastructure that SRE practice depends on.
Incident response and postmortem methodology. Structured incident response severity classification, incident commander role, communication cadence, mitigation versus root cause analysis, and the blameless postmortem culture that turns incidents into reliability improvements.
An SRE who has not run real production incidents, who has not been incident commander for a major outage, who has not written a postmortem that drove actionable reliability improvements lacks the operational experience that defines senior SRE practice.
Chaos engineering. Deliberately injecting failures into production or production-like environments to test system resilience using tools like Chaos Monkey (Netflix), Gremlin, AWS Fault Injection Simulator, or Chaos Mesh for Kubernetes. Chaos engineering requires both the technical skill to inject specific failure modes and the analytical skill to define the steady-state hypotheses that chaos experiments test.
Toil reduction through automation. Google defines toil as manual, repetitive operational work that could be automated runbook execution, manual deployments, capacity provisioning, routine incident response. SREs are expected to spend no more than 50% of their time on operational work and the remainder on engineering work that reduces toil.
An SRE who does not track their toil percentage, who does not have a backlog of toil reduction projects, and who cannot describe the operational work they have automated is not applying the SRE methodology they are doing systems administration with an SRE job title.
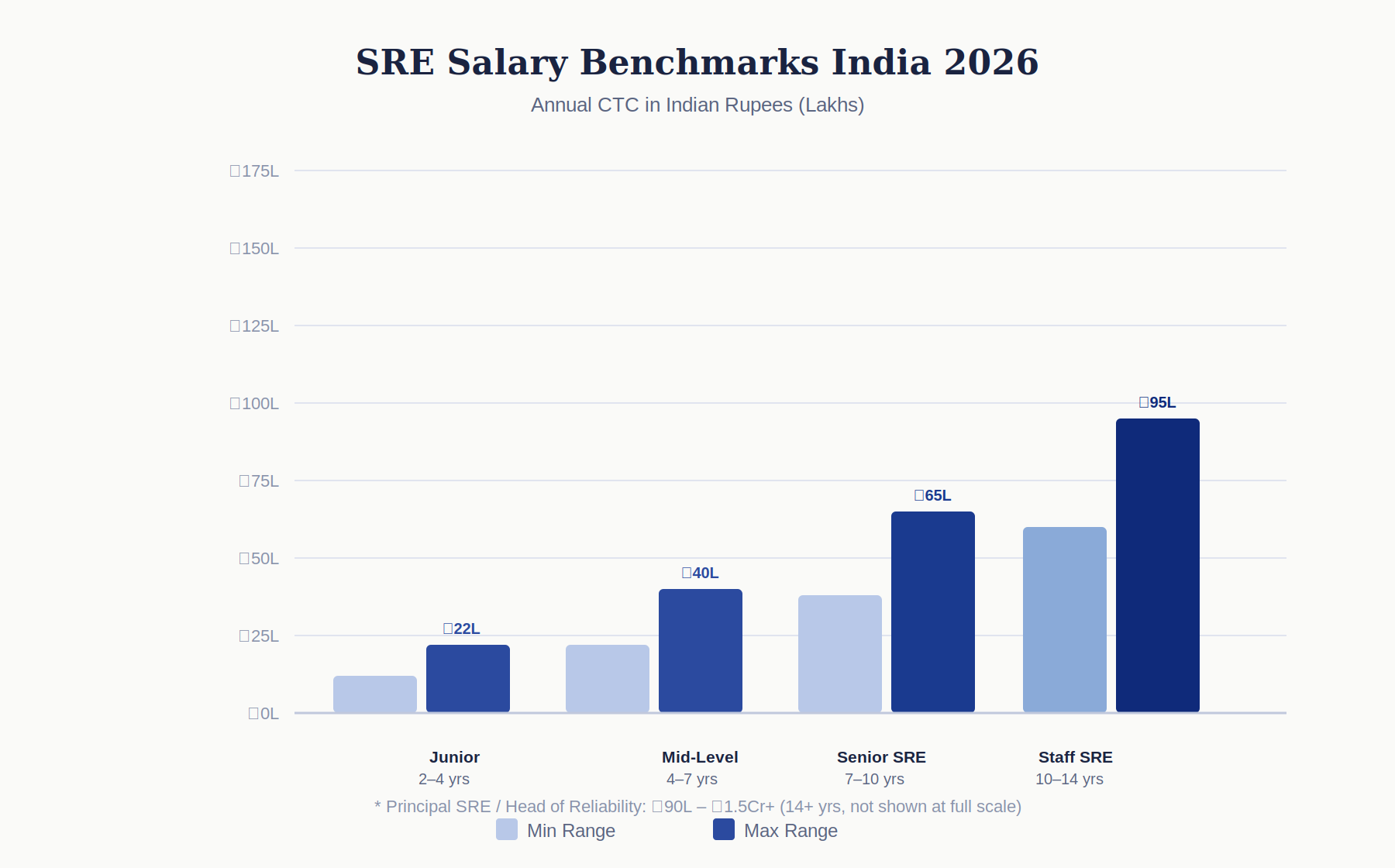
SRE Salary Benchmarks India 2026
| Level | Experience | Annual CTC (INR) |
| Junior SRE / Associate SRE | 2–4 years | ₹12L – ₹22L |
| SRE / Mid-Level | 4–7 years | ₹22L – ₹40L |
| Senior SRE | 7–10 years | ₹38L – ₹65L |
| Staff SRE / SRE Lead | 10–14 years | ₹60L – ₹95L |
| Principal SRE / Head of Reliability | 14+ years | ₹90L – ₹1.5Cr+ |
SRE is at the top of the engineering compensation bracket in India. Senior and staff SREs at Google, Amazon, and Microsoft GCCs command the upper end of these ranges. For GCCs competing against Big Tech for SRE talent, compensation benchmarking against the specific companies your target candidates are coming from is essential; the range is wide and location and company-tier significantly affect the market rate.
What to Actually Assess in an SRE Interview
SLO designed the foundational SRE assessment.
Ask the candidate to design SLOs for a specific service, a payment processing API that is called 10,000 times per day. What SLIs do they choose? Why availability and latency rather than just availability? How do they set the SLO target? What data would they look at to determine whether 99.9% or 99.95% is the right target? How do they calculate the error budget?
How do they design the error budget burn rate alert that warns the team before the budget is exhausted? Candidates who have designed real SLOs will walk through this with specific decisions and reasoning. Those who have only studied SRE will recite the Google SRE Book definition without the operational specificity.
Observability design for a microservices architecture.
Ask the candidate to design the observability stack for a new microservices application being deployed to Kubernetes. What metrics do they instrument at the service level? How do they instrument distributed traces across service boundaries? How do they design the log structure for efficient querying?
What dashboards do they build? How do they configure alerting, specifically the alerting philosophy that minimizes alert fatigue while ensuring genuine incidents are caught? Candidates with real observability experience will describe specific implementation decisions: Prometheus scrape interval configuration, OpenTelemetry SDK integration, structured logging with trace context injection.
Incident responses describe a real major incident.
Ask the candidate to walk through the most significant production incident they have been involved in, what the impact was, how it was detected (alert or user report), what their role was, how the incident was mitigated, what the root cause was, and what the postmortem produced.
Genuine SRE incident response experience produces specific, detailed narratives with specific technical decisions and specific postmortem actions. Candidates who have not been in real major incidents give vague narratives without the technical specificity.
Chaos engineering: have you actually run a chaos experiment?
Ask the candidate to describe a chaos engineering experiment they have designed and executed, the steady-state hypothesis, the specific failure mode injected, how they measured the system’s response against the hypothesis, and what the experiment revealed about system resilience.
Candidates who have run real chaos experiments describe specific failure modes and specific system behaviors. Those who have only read about chaos engineering describe the methodology abstractly.
Toil identification and reduction.
Ask the candidate to describe the most significant toil reduction project they have completed, what the toil was, how much time it was consuming per week, how they automated it, and what the reliability improvement was. The best SRE candidates have a mental catalogue of toil reduction wins specific operational tasks they have eliminated through automation.
Why GCCs Are Hiring SREs Before They Scale Engineering Teams
The pattern that plays out consistently across GCC engineering builds is this: an engineering team scales rapidly, deploys services to production, and then discovers that operational incidents are consuming significant engineering time on-call rotations, manual runbook execution, alert fatigue, and slow incident resolution that keeps engineers out of feature development.
The SRE hire at that point is a reactive response to reliability problems that have already developed. Forward-thinking GCC engineering leaders are hiring SRE capability earlier before the operational overhead accumulates to design the SLOs, build the observability infrastructure, and establish the incident response processes that prevent the reliability debt from developing in the first place.
For GCCs building from scratch, the recommended sequence is: platform/infrastructure engineering to build the foundation, then SRE to design reliability from the start, then scale the application engineering teams on top of a reliability-designed platform. This is the model that Google and Amazon’s GCC engineering organizations use and the reason SRE is one of the first senior engineering hires, not the last.
The 3 Most Common SRE Hiring Mistakes
Hiring senior DevOps engineers and calling them SREs.
The skills overlap is real but the discipline overlap is not. A senior DevOps engineer who has never designed an SLO, run a chaos engineering experiment, or led an incident response with structured postmortem analysis is not an SRE. The SRE-specific methodology error budgets, chaos engineering, toil quantification requires assessment distinct from DevOps assessment.
Hiring SREs before the engineering team has services in production.
SRE is a discipline for managing the reliability of production systems. Hiring SREs before you have production services creates a role without a mandate the SRE will either do DevOps work (because the real SRE work does not exist yet) or leave because the role is not what was described. Hire SRE capability when the first services are approaching production, not during the pre-production build phase.
Not assessing incident response experience.
Incident response is a real skill that develops through experience, not through study. An SRE who has not been incident commander for a major production incident who has not made real-time decisions about escalation, communication, and mitigation under pressure is not ready for senior SRE responsibility. Always ask for a specific major incident narrative in the interview.
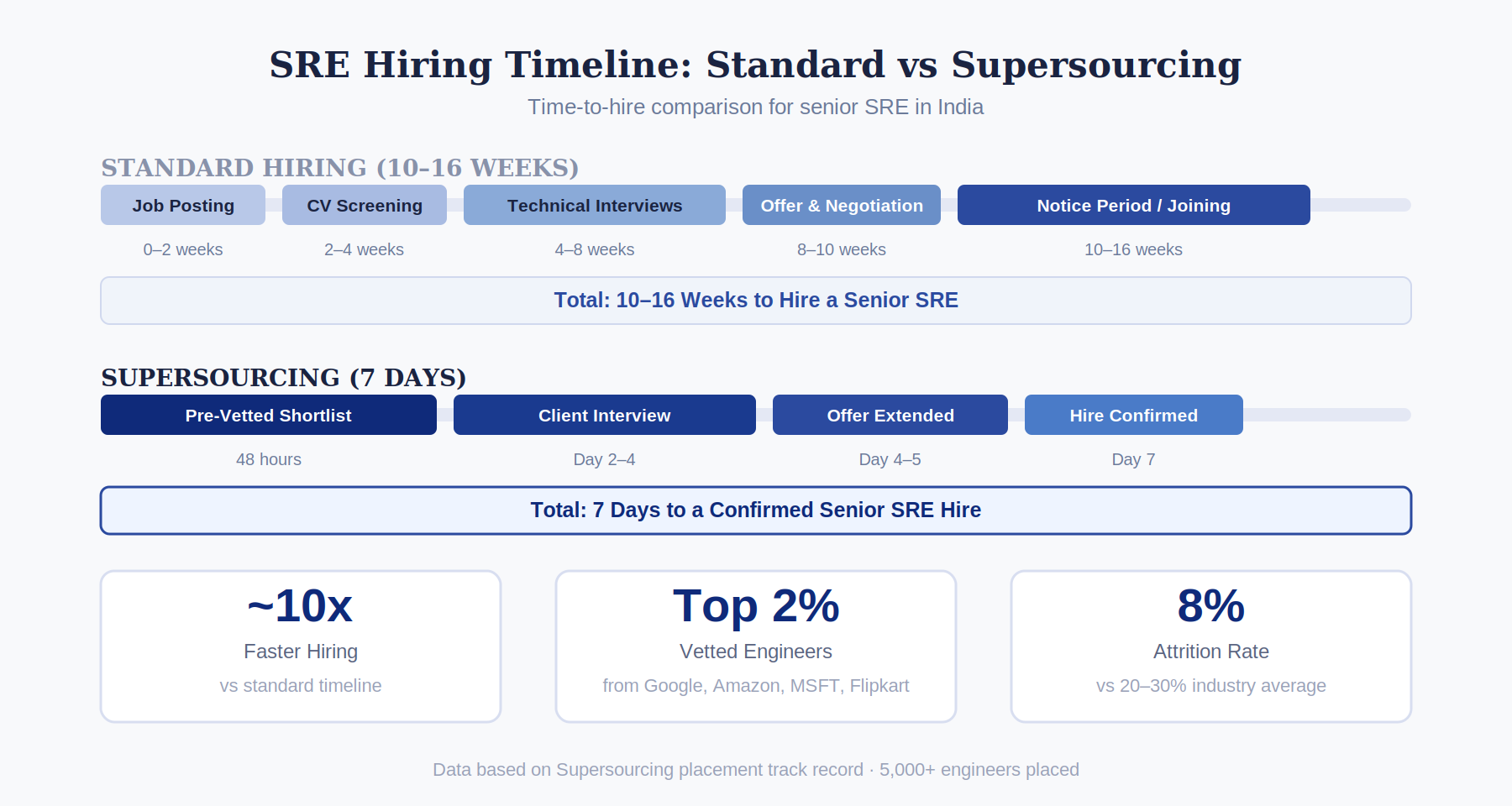
How Supersourcing Sources and Vets SREs
Our senior platform and reliability architects assess every SRE shortlist SLO and error budget design, observability stack architecture, incident response experience (specific major incident narrative required), chaos engineering methodology, toil reduction track record, and the software engineering skills that distinguish SRE from systems administration.
We maintain a continuously vetted bench of SRE engineers across all seniority levels from associate SREs through principal reliability engineers. We source from the Google, Amazon, Microsoft, Flipkart, and Swiggy SRE communities in India the talent pools where genuine SRE methodology is practiced. Shortlist in 48 hours.
Optional Barrister or interview.io technical interviews arranged by us. 5,000+ engineers placed. 8% attrition. 98% joining rate. 14-day free replacement.
FAQ
What is the difference between SRE and DevOps for hiring?
DevOps focuses on CI/CD pipelines, infrastructure as code, and deployment automation. SRE focuses on production reliability, SLO design, error budget management, observability, incident response, chaos engineering, and toil reduction. Both require infrastructure skills. SRE adds specific reliability engineering methodology error budgets, chaos experiments, structured postmortem culture that is distinct from DevOps practice.
What is an SLO and why is it important for SRE hiring?
A Service Level Objective (SLO) is the target reliability for a service for example, 99.9% availability or 100ms 95th percentile latency. SLOs create a measurable definition of reliability and drive the error budget that determines when teams prioritize reliability work versus feature development. An SRE who cannot design SLOs, calculate error budgets, and use error budget burn rate for prioritization is not applying the SRE methodology.
What is chaos engineering and why does it matter?
Chaos engineering deliberately injects failures into production or production-like systems to test resilience validating that the system behaves as expected under specific failure conditions before those conditions occur naturally. It requires both technical skill (failure injection tooling) and analytical skill (steady-state hypothesis design and measurement). SREs who have run real chaos experiments have a fundamentally different understanding of system resilience than those who have only read about it.
Can you place SREs with experience at Big Tech GCCs in India?
Yes. We source from the Google, Amazon, Microsoft, Flipkart, and Swiggy SRE communities in India specifically for clients who need engineers who have practiced SRE at production scale. This pool is smaller and commands higher compensation but the quality of SRE methodology experience is significantly higher than the broader market.
What is your replacement policy?
Free replacement within 14 days. No charge, no questions.
Do I need a legal entity in India?
No. We act as Employer of Record payroll, PF, ESIC, TDS, all statutory compliance handled by us.
What is the realistic hiring timeline for a senior SRE in India without Supersourcing?
10–16 weeks through standard job postings for a genuine SRE with SLO design, chaos engineering, and incident response experience. Through Supersourcing: 48-hour shortlist, hire within 7 days.
Talk to Us About Your SRE Requirement
If you are building reliability engineering capability in India with a single SRE to design your SLO framework, a reliability lead to build your observability infrastructure, or a full SRE team for a tech GCC reliability program I am usually the one on those calls.
Email: mayank@supersourcing.com Or book a meeting directly at supersourcing.com
Tell us your production stack, current reliability maturity, SLO program status, and what the SRE team composition looks like. Shortlist in 48 hours from there.
No retainer until you hire. Replacement clause on every engagement.
Mayank Pratap Singh · Co-founder, Supersourcing Google AI Accelerator · LinkedIn Top 20 Startups India · 5,000+ Engineers Placed · 1,000+ Companies · 17 Fortune 500s
