Data engineers are the infrastructure layer that every data-driven product depends on. Without them, the data scientist cannot get clean data. The ML engineer cannot get training sets. The BI dashboard shows stale numbers. Learning how to hire data engineers in India well is one of the highest-leverage decisions an engineering leader can make in 2026 the role is consistently one of the top three hardest-to-hire in India’s engineering market, with high demand, relatively constrained supply, and a wide quality range that is difficult to assess from a resume alone.
Data engineers power the pipelines behind every modern data product from analytics dashboards to machine learning systems. Without strong data engineering, even the best AI or BI initiatives fail to deliver reliable outcomes.
If you’re figuring out how to hire data engineers India, the real challenge isn’t just sourcing candidates, it’s accurately assessing real-world data pipeline experience versus resume-level familiarity.
The demand for data talent continues to accelerate alongside the growth of the global data economy. According to Data Analyst Job Outlook – Skillify Solutions, the data analytics market is projected to grow significantly through 2026, driven by organizations increasing their reliance on data-driven decision-making across industries. This sustained demand is directly impacting hiring for adjacent roles like data engineering, making it one of the most competitive and critical tech hiring areas in India.
This guide breaks down what to test, what to pay, and where to find high-quality data engineers in India so you can hire faster, reduce risk, and build scalable data infrastructure.
Supersourcing has placed data engineers across fintech platforms, healthtech analytics systems, supply chain intelligence platforms, and SaaS analytics products. This guide is built on real hiring experience with real client requirements not generic advice recycled from a job board.
Why Hiring Data Engineers in India Looks Different in 2026
Three shifts have changed what “good” looks like this year, and any serious guide to how to hire data engineers in India needs to account for them.
AI workloads have merged with data engineering.
Retrieval-augmented generation pipelines, vector databases, and feature stores for ML models are now standard requests inside data engineering job descriptions. A candidate who has only ever built reporting pipelines may struggle with the ingestion and freshness demands of an AI application, even if their SQL and Spark fundamentals are solid. When you scope a role, decide upfront whether AI-adjacent pipeline work is in scope, because it changes both the skill bar and the salary band.
The supply-demand gap has widened at the senior end.
Junior and mid-level batch pipeline engineers are relatively easy to source across Bangalore, Hyderabad, and Pune. Engineers with 7+ years who have shipped streaming systems at scale, owned cost optimization on Snowflake or Databricks, or designed data platforms from zero are scarce and typically not actively job-hunting; they need to be sourced, not posted-and-waited-for.
Remote-first hiring has widened the map.
Companies that once hired only from Bangalore now routinely hire strong data engineers based in Indore, Jaipur, Coimbatore, and other emerging tech hubs, at meaningfully lower cost with no drop in quality. This has made location strategy a real cost lever, covered in the salary section below.
The Data Engineering Role Spectrum
Before writing a job description, get specific about which of these four profiles you actually need. “Data engineer” is not one job, it is a family of roles with different tools, different mental models, and different salary expectations.
Batch pipeline engineer:
Builds ETL/ELT pipelines that process data in scheduled batches hourly, daily, weekly. Tools: Apache Spark, Airflow, dbt, SQL. Strong SQL and data modelling skills are central. This is the most common data engineering profile in India.
Streaming/real-time engineer:
Builds pipelines that process data as it arrives event streams, IoT data, click streams. Tools: Apache Kafka, Apache Flink, Spark Streaming, AWS Kinesis. Requires understanding of event-driven architecture and stream processing semantics (exactly-once, watermarking, late arrivals).
Cloud data platform engineer:
Builds data infrastructure on cloud platforms Snowflake, Databricks, BigQuery, Redshift. Strong cloud platform knowledge plus data modelling. Increasingly common as companies move from on-premise Hadoop to cloud-native data platforms.
Analytics engineer:
Sits between data engineering and analytics builds data models in debt, creates clean semantic layers, works closely with analysts and data scientists. The dbt-first workflow has created this hybrid role, and it is one of the fastest-growing job titles in India’s data teams this year.

The Skill Assessment Framework
Once you know which profile you’re hiring for, assessment should be structured, not conversational. A resume tells you what tools someone has touched; it does not tell you whether they understand why those tools work the way they do. The framework below is designed to surface that difference.
Core skills every data engineer must have:
| Skill | Assessment | What Good Looks Like |
| SQL depth | Write a complex query window functions, CTEs, performance optimisation | Writes clean, performant SQL; understands query plans |
| Data modelling | Design a star schema for a given business domain | Understands fact/dimension tables, slowly changing dimensions |
| Python for data | Code review a data pipeline script | Clean code, error handling, idempotency |
| Pipeline design | Design a pipeline for a specific use case | Considers idempotency, backfill strategy, failure recovery |
| Data quality | Ask how they validate data in production | Has opinion on expectation frameworks (Great Expectations, debt tests) |
Stack-specific assessments, layered on top of the core skills based on the profile you’re hiring for:
| Tool | What to Assess |
| Apache Spark | Transformation optimisation (avoiding shuffles), understanding of execution plans, Spark vs Pandas decision criteria |
| Apache Airflow | DAG design, dependency management, retry strategies, monitoring |
| dbt | Model materialisation strategies, incremental models, testing approach |
| Snowflake/BigQuery | Cost optimisation (partitioning, clustering), Zero Copy Cloning, Time Travel |
| Kafka | Consumer group management, offset management, exactly-once semantics |
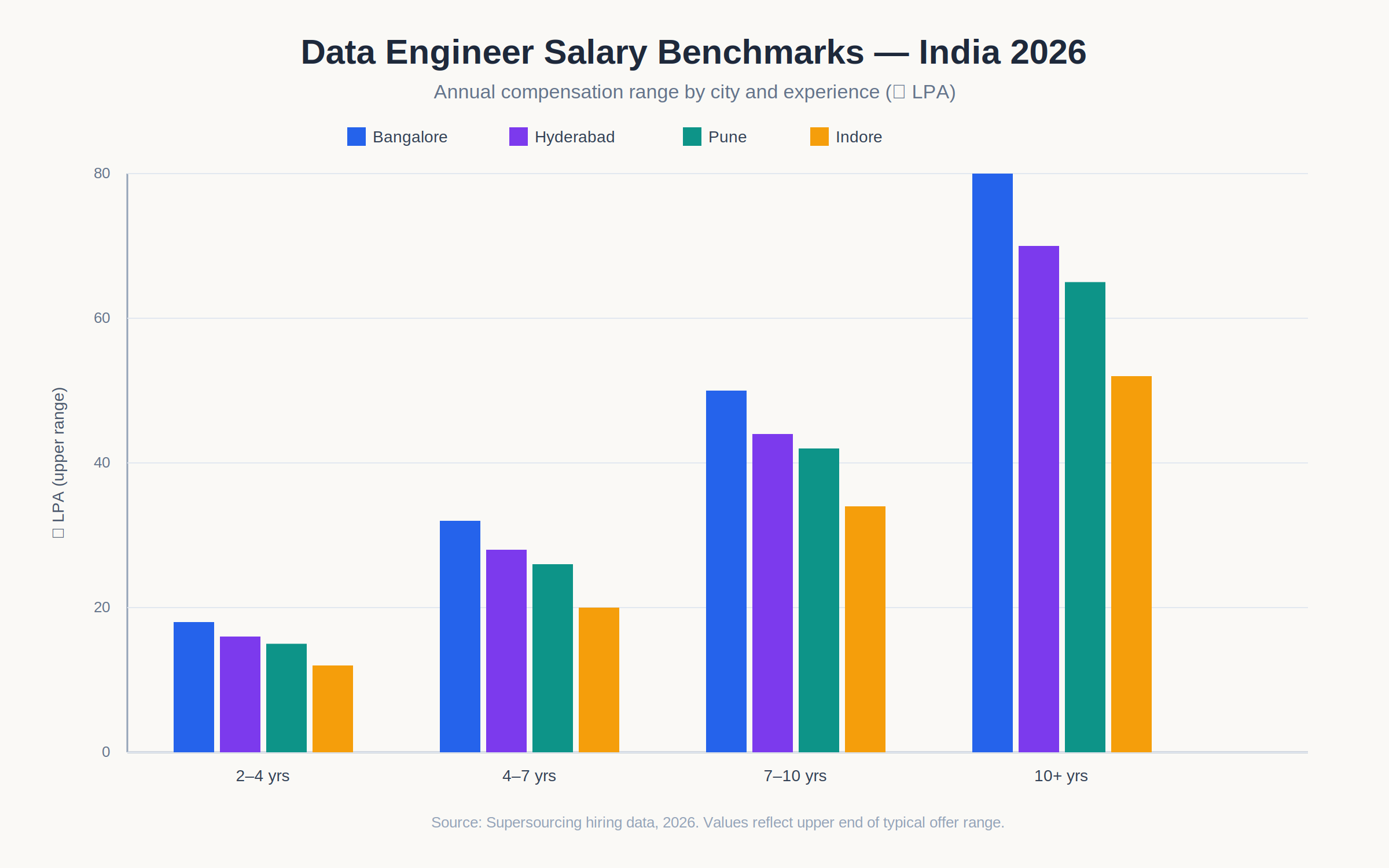
Salary Benchmarks India 2026
Compensation varies significantly by city and by profile. Real-time and streaming specialists sit above these ranges; batch and analytics engineering profiles sit within them.
| Experience | Bangalore (₹ LPA) | Hyderabad (₹ LPA) | Pune (₹ LPA) | Indore (₹ LPA) |
| 2–4 years | ₹10–18 | ₹9–16 | ₹8–15 | ₹7–12 |
| 4–7 years | ₹18–32 | ₹16–28 | ₹15–26 | ₹12–20 |
| 7–10 years | ₹30–50 | ₹26–44 | ₹24–42 | ₹20–34 |
| 10+ years | ₹45–80 | ₹40–70 | ₹38–65 | ₹30–52 |
Real-time/streaming engineers command a 15–20% premium over equivalent batch pipeline engineers, reflecting both scarcity and the operational complexity of running low-latency systems reliably.
Full-Time, Contract, or Staff Augmentation Which Hiring Model Fits?
Not every data engineering need justifies a full-time headcount, and part of learning how to hire data engineers in India well is matching the hiring model to the actual workload.
Full-time hire:
Right when data engineering is a permanent, growing function you have an ongoing pipeline of new data sources, dashboards, and models that need continuous ownership. Full-time hires also make sense when the role requires deep institutional knowledge of your data domain over years.
Contract or fixed-term:
Right for a defined project migrating from an on-premise warehouse to Snowflake, building a one-time analytics platform, or standing up a data pipeline ahead of a product launch. Contract engineers should still be assessed with the same rigor as full-time hires; a bad contract hire on a time-boxed migration can cost more in rework than the contract itself.
Staff augmentation / pre-vetted bench:
Right when speed matters more than building an in-house recruiting pipeline, or when you need a specific stack skill (say, Flink expertise) for a short but critical window. This is where a vetted talent partner shortens time-to-hire from weeks to days, because the technical screening has already happened.
Most data teams in India end up running a mix of a small full-time core with contract or augmented capacity absorbing project spikes.
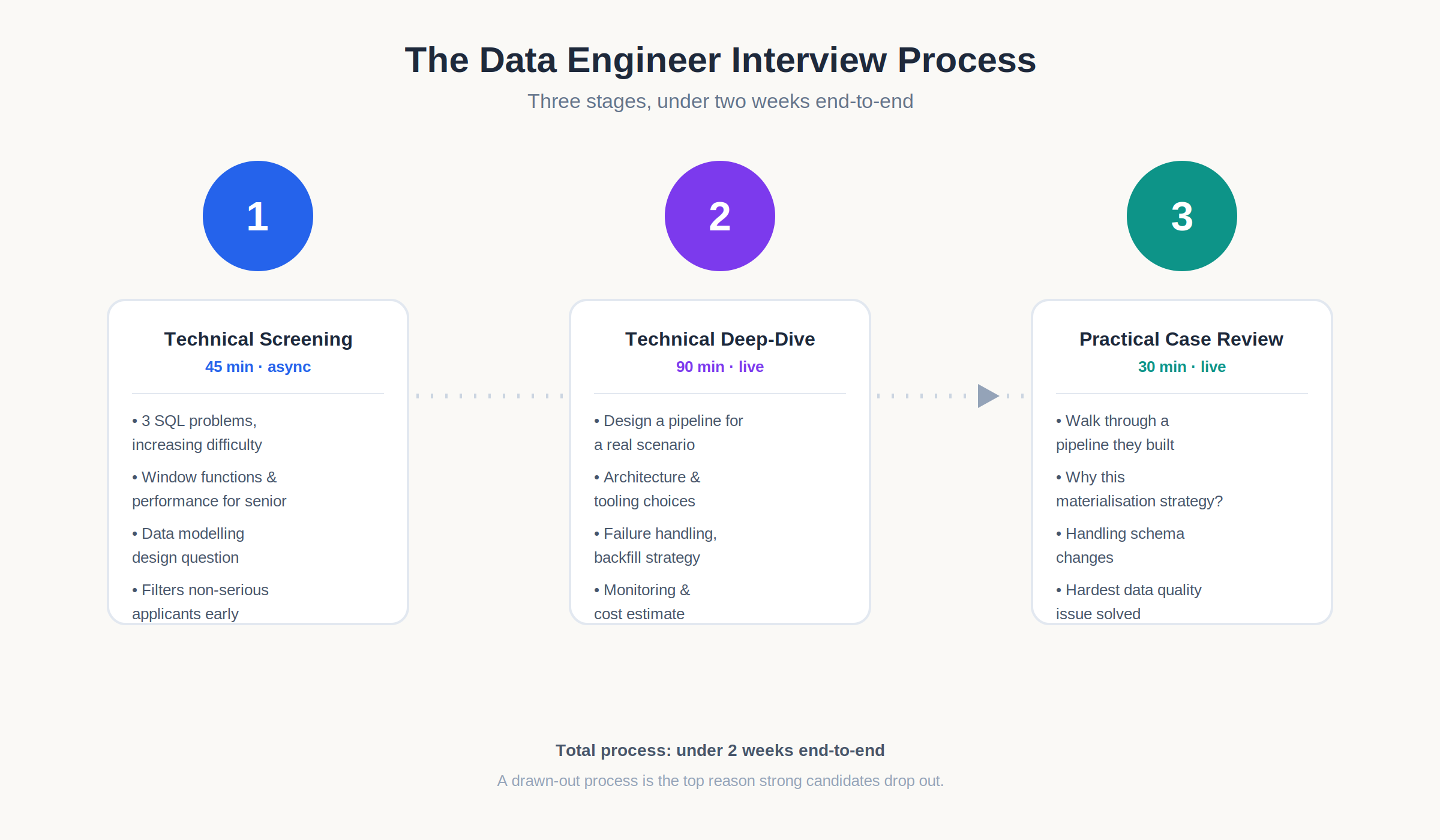
The Interview Process 3 Stages
Stage 1 Technical screening (45 minutes, async):
SQL assessment three problems of increasing complexity. Medium-level SQL is the threshold for junior roles; window functions and performance optimisation for seniors. Add a data modelling design question: “Given this business domain, design the dimensional model.”
Stage 2 Technical deep-dive (90 minutes, live):
Pipeline design for a specific scenario: “Design a pipeline that ingests clickstream data from three sources, deduplicates it, calculates daily user session metrics, and makes them available for BI dashboards with under four hours of latency.” Ask them to walk through architecture choice, tooling, failure handling, backfill strategy, monitoring, and cost estimate.
Stage 3 Practical case review (30 minutes):
Review a pipeline they have built. Ask specific questions about design decisions. Why did they choose this materialisation strategy? How do they handle schema changes? What was the hardest data quality issue they encountered and how did they solve it?
Keep the total process under two weeks end-to-end. Strong data engineers in India, especially at the 4–10 year mark, are typically weighing two or three offers at once, and a drawn-out process is the single most common reason good candidates drop out.
Red Flags in Data Engineer Profiles
| Red Flag | What It Signals |
| Only worked with toy datasets | No production experience |
| “Experience with Spark” but cannot explain why a shuffle is expensive | Superficial Spark knowledge |
| No data quality framework | Has never needed to validate data at scale |
| Cannot explain idempotency | Has never debugged a double-processing bug |
| “I use dbt” but cannot explain incremental materialisation | Used it without understanding it |
| No monitoring on their pipelines | Deployed and forgot |
Common Hiring Mistakes to Avoid
Writing a job description for a “unicorn.”
Requiring deep Spark, deep Kafka, deep debt, and deep cloud cost optimization in one junior-to-mid role filters out strong specialists who would otherwise be a great fit. Pick the two or three skills that matter most for your actual pipeline and weigh the interview accordingly.
Testing tool trivia instead of reasoning.
Asking someone to recite Airflow configuration flags from memory tells you less than asking them to design a DAG for a real scenario and defend their retry strategy. Reasoning under a realistic constraint is a far better predictor of on-the-job performance than trivia recall.
Skipping the practical case review.
Stage 3 above is the stage teams cut first when short on time, and it is the stage most likely to expose a candidate who has used a tool without understanding it. A pipeline they built and can walk through in detail is far more revealing than a whiteboard exercise.
Ignoring data quality ownership.
Many candidates can build a pipeline that works once. Fewer can explain how they would know if it silently broke six months later. Data quality and monitoring questions separate engineers who ship-and-move-on from engineers who own outcomes.
Onboarding a New Data Engineer
Hiring well is only half the outcome of a strong data engineer who spends their first month untangling undocumented pipelines and unclear ownership will ramp slower than one dropped into a clean handoff. Before day one, have ready: access to the data warehouse and orchestration tools, a documented map of existing pipelines and their owners, and a first project scoped to be shippable within two to three weeks so the new hire can build context while delivering something real. Pairing a new data engineer with a current pipeline owner for the first two weeks consistently shortens ramp time more than any onboarding document.
Where to Find Data Engineers in India
- Best cities: Bangalore (deepest pool), Hyderabad (strong data engineering community, lower cost), Pune (good pool, lower cost), Indore (growing, 30–35% lower cost for equivalent quality).
- Best background sources: Engineers from data-heavy product companies (Swiggy, Zomato, Flipkart, PhonePe), analytics consulting firms (ThoughtWorks, Sigmoid), and cloud service providers’ India teams.
- Avoid: Data engineers from generic IT services companies who have used ETL tools without ever designing a pipeline architecture themselves.
Why Supersourcing Finds Data Engineers Faster
Supersourcing’s pre-screened bench includes data engineers who have already been assessed on SQL depth, pipeline design, and stack-specific knowledge. For standard mid-level data engineering roles, first profiles arrive in 24 to 48 hours. The 3:1 submit-to-hire ratio means you interview three candidates and hire one not fifteen.
Frequently Asked Questions
What is the difference between a data engineer and a data scientist in India’s job market?
A data engineer builds and maintains the infrastructure that data flows through pipelines, warehouses, data models, and quality validation. They write production code that runs reliably at scale. A data scientist uses that infrastructure to extract insights through statistical modelling, experimentation, and prediction. Data engineers typically have stronger software engineering fundamentals and systems thinking, while data scientists typically have stronger statistical and mathematical foundations. In India’s job market, data engineers with 4 to 7 years of experience command 15 to 25% higher salaries than data scientists at equivalent experience levels, because the production systems responsibility commands a premium.
Should I hire a DBT-first analytics engineer or a traditional data engineer for a modern data stack in 2026?
For companies that have already adopted a cloud data warehouse (Snowflake, BigQuery, Databricks) and are building a modern data stack, the analytics engineer (dbt-first) profile often delivers more value than a traditional Spark-heavy data engineer. The analytics engineer builds clean, tested, documented data models in debt and works closely with analysts, reducing the translation layer between raw data and business insights. The traditional data engineer is still needed for the ingestion layer moving data from sources into the warehouse and for real-time use cases that require streaming pipelines. Most mature data teams have both profiles working alongside each other.
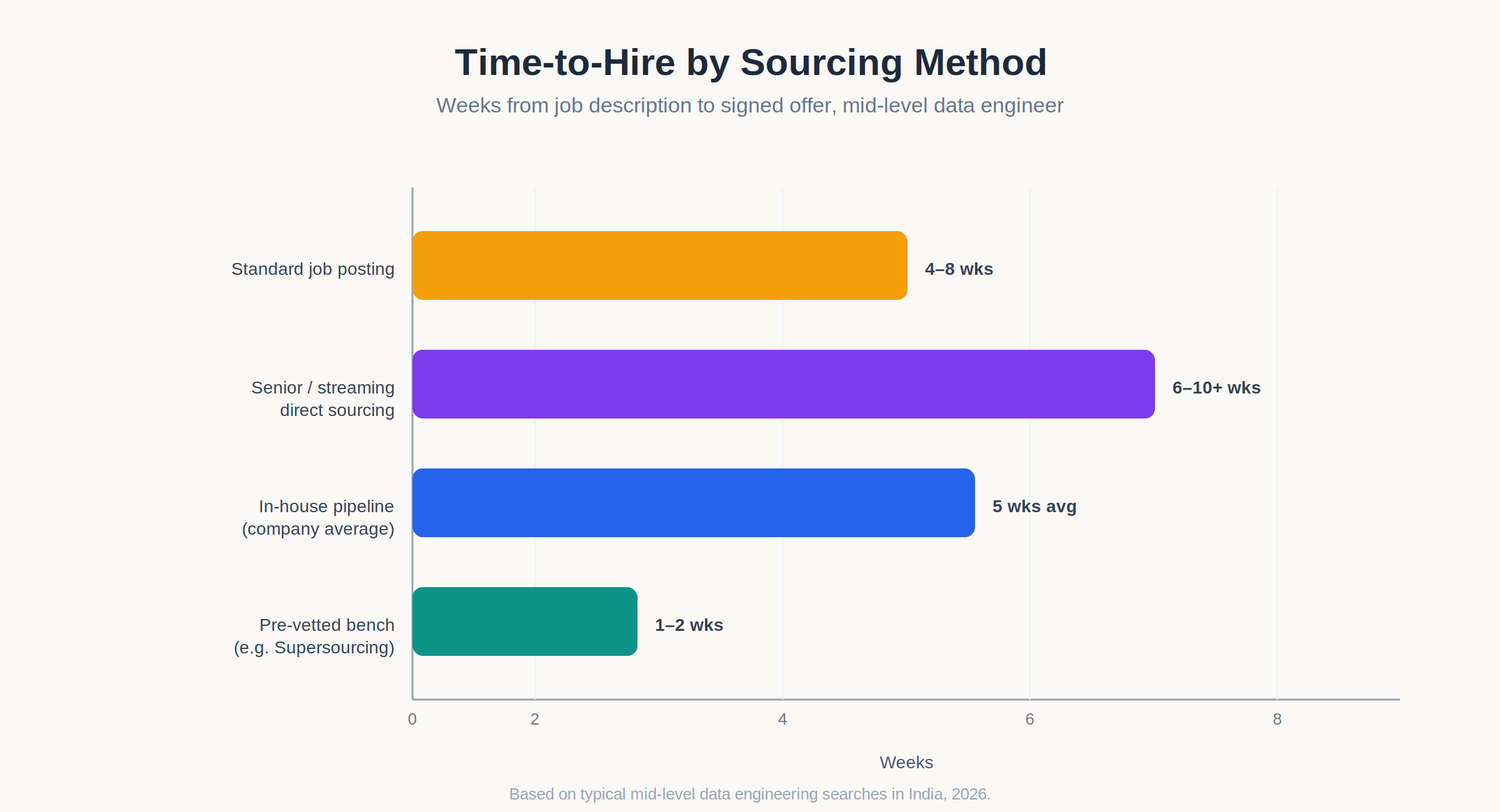
How long does it typically take to hire a data engineer in India?
For a mid-level batch pipeline or analytics engineer sourced through a standard job posting and internal recruiting pipeline, expect four to eight weeks from job description to signed offer. Senior or streaming specialists can take longer, since they are rarely actively looking and need to be sourced directly. Working with a pre-vetted bench, as opposed to starting a search from zero, typically compresses this to one to two weeks, since the technical screening stage is already complete before the first candidate is submitted.
