Data engineering is the most in-demand and hardest-to-fill engineering specialisation on Earth right now.
Not AI. Not machine learning. Not generative AI. Data engineering.
Here’s why. Every AI model needs clean data. Every machine learning pipeline needs reliable data infrastructure. Every business intelligence dashboard needs a data warehouse that actually works. Every real-time analytics system needs streaming data pipelines that don’t break at 3 AM on a Saturday.
AI gets the headlines. Data engineering does the work.
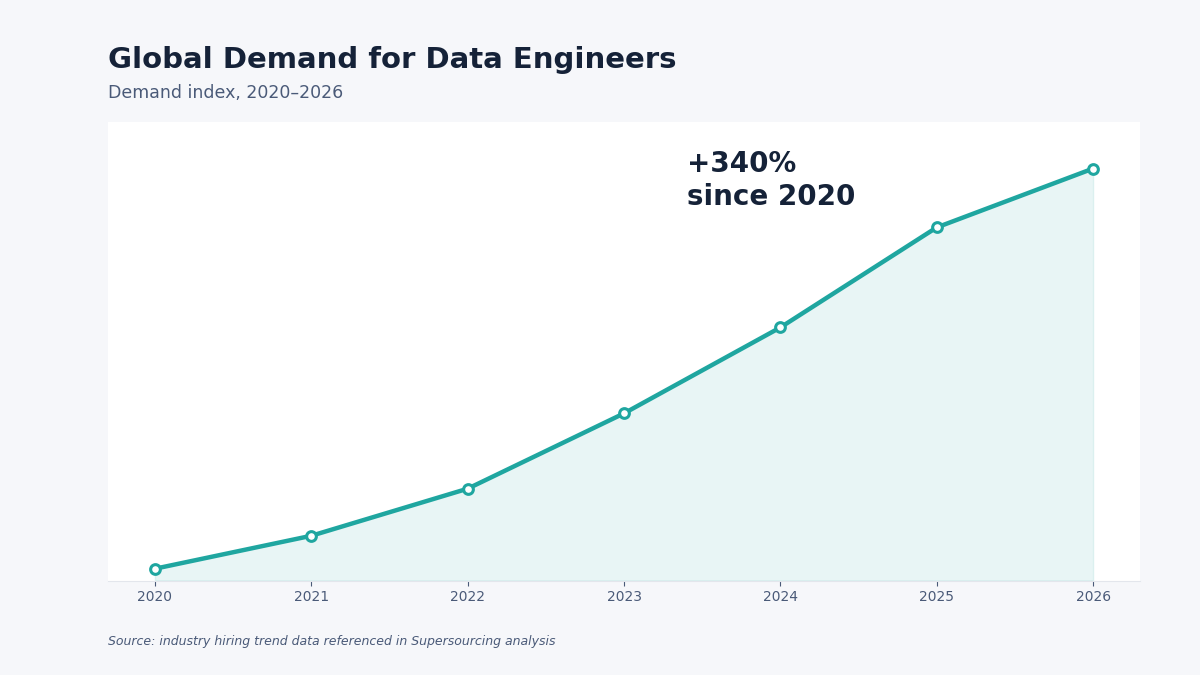
The global demand for how to hire data engineers has grown 340%. LinkedIn’s Jobs on the Rise report has listed data engineering in the top 5 fastest-growing roles for four consecutive years. Every company in fintech, healthcare, retail, logistics, SaaS, manufacturing now has data. Very few have the engineers who can make that data usable.
And the supply is brutally thin. The role barely existed as a distinct discipline 8 years ago. The talent pipeline hasn’t caught up. Globally, there are an estimated 300,000-400,000 qualified data engineers. Companies are competing for them with escalating salaries, signing bonuses, and remote work flexibility and still can’t fill roles fast enough.
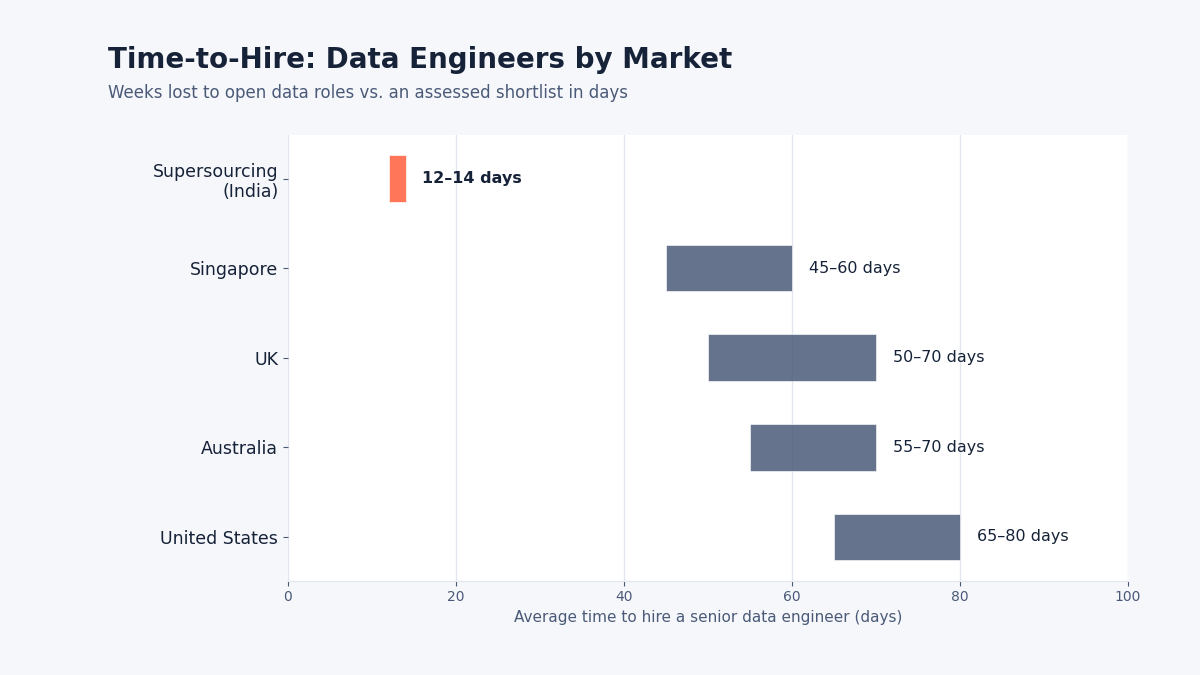
Average time to hire a senior data engineer in the US: 65-80 days. In the UK: 50-70 days. In Singapore: 45-60 days. In Australia: 55-70 days.
Months of vacancy. Months of data projects stalled. Months of AI initiatives blocked because the data foundation doesn’t exist.
India changes this equation. India has the deepest data engineering talent pool outside the United States. India’s IT services industry has been building data infrastructure for global enterprises for two decades. Companies like Impetus, our client partner, are specifically focused on data engineering. The IITs, IISc, and IIIT Hyderabad produce some of the world’s strongest distributed systems and data infrastructure talent.
But finding the right data engineer in India, one who knows your specific data stack, has built production pipelines at enterprise scale, and can communicate architecture decisions to global stakeholders requires a staffing partner with data-engineering-specific assessment depth.
That’s Supersourcing. My name is Mayank Pratap. I co-founded Supersourcing, an IT staffing company that places engineers across 80+ technology specialisations for global enterprises, with data engineering or data scientist being one of the fastest-growing verticals the team handles.
The team has placed Big Data Engineers, Big Data Leads, Data Modelling specialists,
Snowflake engineers, Databricks engineers, Apache Scala developers, Ab Initio developers, Airflow engineers, Power BI developers, QlikSense specialists, and SAS engineers. Not generic “data” roles. Specific data technologies, assessed in-house for production depth.
Our Talent Director, Vijay Kiran, built the engineering hiring operation at Flipkart India’s largest e-commerce company, $35 billion valuation, 10,000+ engineers. Flipkart processes millions of transactions daily. The data infrastructure that powers Flipkart’s recommendation engine, search ranking, pricing algorithms, and logistics optimization is one of the most sophisticated in Asia. Vijay built the hiring machine that sourced and assessed the data engineers who built that infrastructure.
Before Flipkart, he led engineering hiring at two other billion-dollar unicorn companies. Three unicorn-scale data operations. The assessment framework he built evaluates data engineers the way data engineers should be evaluated not on SQL syntax, but on pipeline architecture, data modelling decisions, and production reliability.
Google selected us for the AI Accelerator. CMMI certified us at Level 5. LinkedIn named us a Top Startup in India twice. Impetus a data engineering-focused company is a direct Client
partner, reflecting the team’s specific depth in this space. Wipro and Virtusa are also direct partners. Vijay Shekhar Sharma backs us personally.
Why Data Engineering Hiring Is Different From Software Engineering Hiring
A React developer and a Python developer are both software engineers. Their skills are different but the evaluation framework is similar to algorithmic thinking, code quality, and system design.
Data engineering is a different species entirely. And most staffing agencies and most internal TA teams evaluate data engineers like software engineers. The result: hires that can write code but can’t build data infrastructure.
The Stack Fragmentation Problem
Software engineering has a relatively stable technology landscape. React, Angular, Vue for frontend. Python, Java, Node.js for backend. PostgreSQL, MongoDB for databases. AWS, GCP for cloud. The major choices have been stable for years.
Data engineering’s landscape changes every 18 months. Five years ago, the standard stack was Hadoop, Hive, and batch ETL. Today, it’s Snowflake, Databricks, dbt, Apache Kafka, and streaming pipelines. The tools that were “modern” three years ago are already being replaced.
This fragmentation means a data engineer who mastered Hadoop may have limited relevance for a Snowflake-first architecture in 2026. An Ab Initio expert has deep ETL knowledge but may not know Spark. A Power BI developer has analytics expertise but may not understand data modelling at the warehouse level.
The specific combination of tools your company uses Snowflake + dbt + Airflow? Databricks + Spark + Kafka? Ab Initio + Informatica + Oracle? determines which data engineer is the right hire. A “data engineer” resume that doesn’t specify which stack they’ve built in production is almost useless.
The Supersourcing dedicated team assesses data engineers against the client’s specific stack. Not “do you know data engineering” but “have you built production Snowflake pipelines with SnowPipe ingestion, debt transformations, and Airflow orchestration serving 50+ downstream consumers?”
The Architecture vs Code Problem
A software engineer who writes clean code is valuable. A data engineer who writes clean code but designs bad pipelines is dangerous.
Data engineering is primarily an architecture discipline. The code matters. But the architecture matters 10x more. How do you model dimensions and facts in the warehouse? How do you handle late-arriving data? How do you manage schema evolution without breaking downstream consumers? How do you build pipelines that self-heal when an upstream source changes format unexpectedly? How do you balance batch and streaming for different use cases? How do you manage data quality at every stage of the pipeline?
These are architecture questions. They require years of production experience to answer well. A recently trained data engineer from a bootcamp can write a Spark job. They can’t design a reliable data mesh for an enterprise with 200 data sources, 50 consuming teams, and SLA requirements measured in minutes.
Vijay Kiran’s assessment framework evaluates architecture thinking, not just coding skill. The assessment presents real-world data engineering scenarios late-arriving data, schema changes, pipeline failures, data quality issues and evaluates how the candidate approaches them. This is what separates someone who’s taken a Databricks course from someone who’s kept a production Databricks lakehouse running for 200 internal consumers.
The Scale Problem
A data pipeline that processes 1 GB of data daily is a different engineering challenge from one that processes 1 TB daily. And 1 TB daily is different from 1 PB. Each order of magnitude changes the architecture fundamentally: storage strategy, partitioning approach, compute optimization, cost management, monitoring requirements.
Most data engineers have experience at one scale. The assessment needs to determine whether that scale matches the client’s reality. An enterprise GCC processing 500 TB of daily data from 100+ sources needs a data engineer with large-scale production experience. A startup building its first analytics pipeline needs someone who can move fast without over-engineering.
The team assesses for scale-fit, not just technical capability. A data engineer who’s brilliant at petabyte-scale Spark optimization might be wrong for a 50-person startup that needs a pragmatic Snowflake setup. And vice versa.
The Data Engineering Talent Landscape in India
India’s data engineering talent pool is the deepest outside the US. And it’s growing faster than any other country.
Three structural reasons.
India’s IT services industry trained them. Wipro, our direct vendor partner Infosys, TCS, Cognizant, HCL, and Tech Mahindra have been building data warehouses, ETL pipelines, and analytics platforms for Fortune 500 companies for 20+ years. Tens of thousands of data engineers started their careers building data infrastructure at these companies. Many have since moved to product companies, startups, or independent consulting creating a deep market of experienced data professionals.
India’s startups demand them. Flipkart, Razorpay, Swiggy, Zerodha, PhonePe, CRED India’s own unicorns process enormous data volumes. The data engineering teams at these companies are among the most skilled in the world. When these engineers become available through career transitions, startup exits, or freelance preferences they enter the talent market with production experience at genuine scale.
Our Talent Director Vijay Kiran built the engineering hiring operation at Flipkart, a company whose data infrastructure processes millions of transactions daily, powers real-time recommendation engines, and drives logistics optimization across thousands of cities. The data engineers he hired and evaluated there are the calibre that global enterprises need.
Impetus our client partner is data-engineering-focused. Impetus Technologies is an
Indian company that specialises in big data and data engineering. Their partnership with Supersourcing reflects our specific depth in data engineering staffing. When a client needs niche data talent Ab Initio specialists, Databricks architects, Kafka streaming engineers the combination of Impetus’s ecosystem knowledge and Supersourcing’s assessment framework produces candidates that generic agencies can’t find.
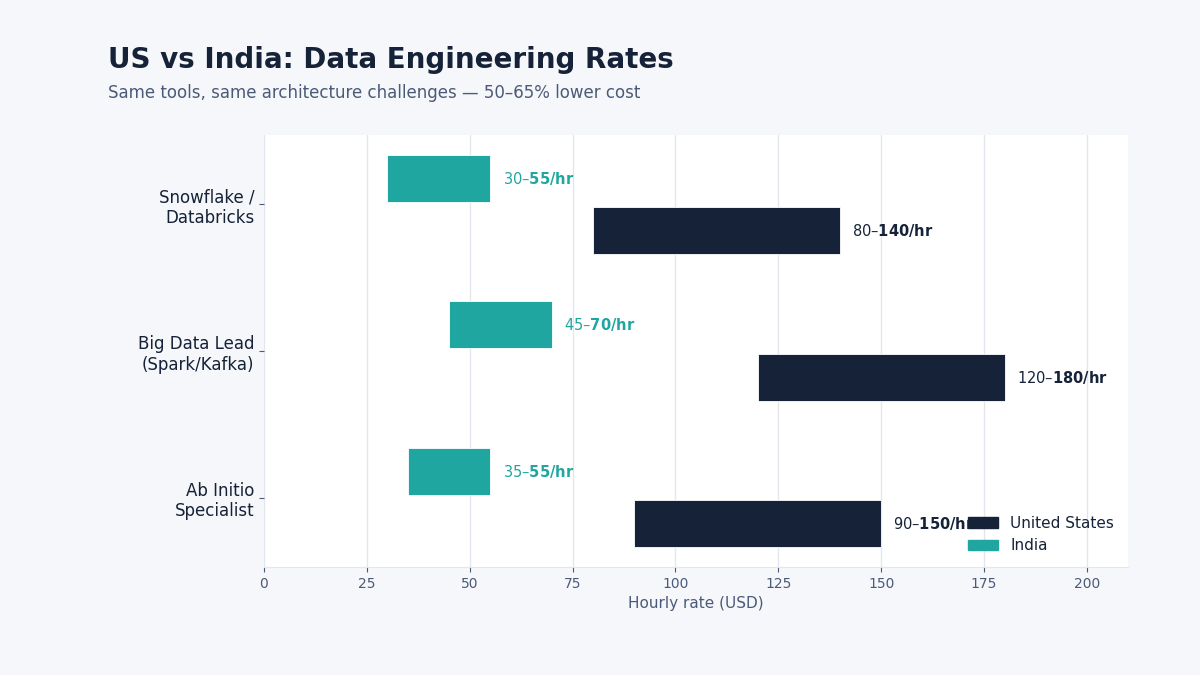
The cost advantage is significant. A senior data engineer with Snowflake and Databricks expertise in the US commands $80-$140/hour. In India: $30-$55/hour. A Big Data Lead with Spark and Kafka at enterprise scale in the US: $120-$180/hour. In India: $45-$70/hour. An Ab Initio specialist in the US: $90-$150/hour. In India: $35-$55/hour.
Same tools. Same platforms. Same architecture challenges. 50-65% lower cost. The quality isn’t discounted, the cost of living is.
The Specific Data Engineering Roles the Team Fills
Precision matters in data engineering hiring. Every technology has its own assessment. Here are the specific roles the team places.
Snowflake Engineers Snowflake architecture, warehouse design, SnowPipe for real-time ingestion, data sharing, time travel, access control, query optimization, Snowpark for code-based transformations. The assessment evaluates production Snowflake experience managing multi-terabyte warehouses with cost optimization, not just writing queries in a trial account.
Databricks Engineers Spark on Databricks, Delta Lake, Unity Catalog, Databricks Workflows, MLflow integration, lakehouse architecture. Assessment distinguishes between engineers who’ve run notebooks in Databricks Community Edition and those who’ve built production lakehouses serving 100+ downstream consumers with SLA requirements.
Apache Spark and Scala Developers Spark Core, Spark SQL, Spark Streaming, Structured Streaming, Spark MLlib. Scala-based Spark development for high-performance data processing. Assessment evaluates Spark optimization partition strategy, shuffle management, memory tuning because production Spark at scale is primarily an optimization problem.
Apache Airflow Engineers DAG design, custom operators, sensor patterns, XCom for task communication, connection management, scaling Airflow (Celery executor, Kubernetes executor). Airflow is the most common orchestration tool but the difference between a well-designed Airflow deployment and a tangled mess of interdependent DAGs is enormous.
Ab Initio Developers Ab Initio GDE, Express>It, metadata management. Ab Initio is used by the world’s largest financial institutions and telecom companies. Ab Initio talent is rare and specialized few agencies can assess it because few have ever encountered it. The Supersourcing team has placed Ab Initio developers for enterprises that run critical ETL on this platform.
Apache Kafka Engineers Kafka clusters, producers, consumers, Kafka Connect, ksqlDB, schema registry, Kafka Streams. Real-time streaming pipelines for event-driven architectures. Assessment evaluates production Kafka partition management, consumer group handling, exactly-once semantics, and cluster scaling.
Data Modelling Specialists dimensional modelling (Kimball), Data Vault 2.0, third normal form, conceptual/logical/physical modelling. Data modelling is the foundation that determines whether the warehouse is queryable or chaotic. Assessment evaluates modelling decisions star schema vs snowflake, slowly changing dimensions, bridge tables in the context of real business requirements.
Big Data Leads senior data engineers who combine technical depth with team leadership, architecture vision, and stakeholder management. They design the data platform strategy, choose the technology stack, mentor junior engineers, and communicate data capabilities to business stakeholders. Leadership assessment is Vijay Kiran’s specialty built across three unicorn hiring operations.
Power BI and QlikSense Developers dashboard design, DAX calculations, data source connections, row-level security, semantic models for Power BI. QlikSense load scripting, set analysis, mashup API for custom applications. BI developers are often grouped with data engineers but require distinct visual and analytical skills alongside data skills.
SAS Engineers SAS programming, SAS Enterprise Guide, SAS Viya, statistical analysis, regulatory reporting. Used heavily in banking, insurance, and pharmaceutical industries for risk analysis and regulatory compliance. SAS talent is niche and aging. Finding SAS engineers who also understand modern data platforms is particularly challenging.
Informatica / IICS Developers Informatica PowerCenter, IICS (Informatica Intelligent Cloud Services), IDMC, data quality, master data management. Legacy ETL expertise that remains critical for enterprises running Informatica-based data infrastructure. Assessment distinguishes between PowerCenter-only experience and cloud-native IICS experience.
SQL Code Reviewers senior data professionals who review SQL code quality, optimize queries, enforce coding standards, and ensure data pipeline reliability. Assessment evaluates query optimization, depth execution plan analysis, index strategy, partition pruning not just query syntax.
For every technology, the assessment matches the depth. A Snowflake evaluation asks about warehouse sizing strategies and cost optimization techniques. A Kafka evaluation asks about partition rebalancing and consumer lag management. An Ab Initio evaluation goes into GDE graph design and parallelism configuration. Generic coding tests don’t work for data engineering. The Supersourcing team builds technology-specific assessments because Vijay Kiran’s framework demands it.
How Supersourcing Hires Data Engineers The Process
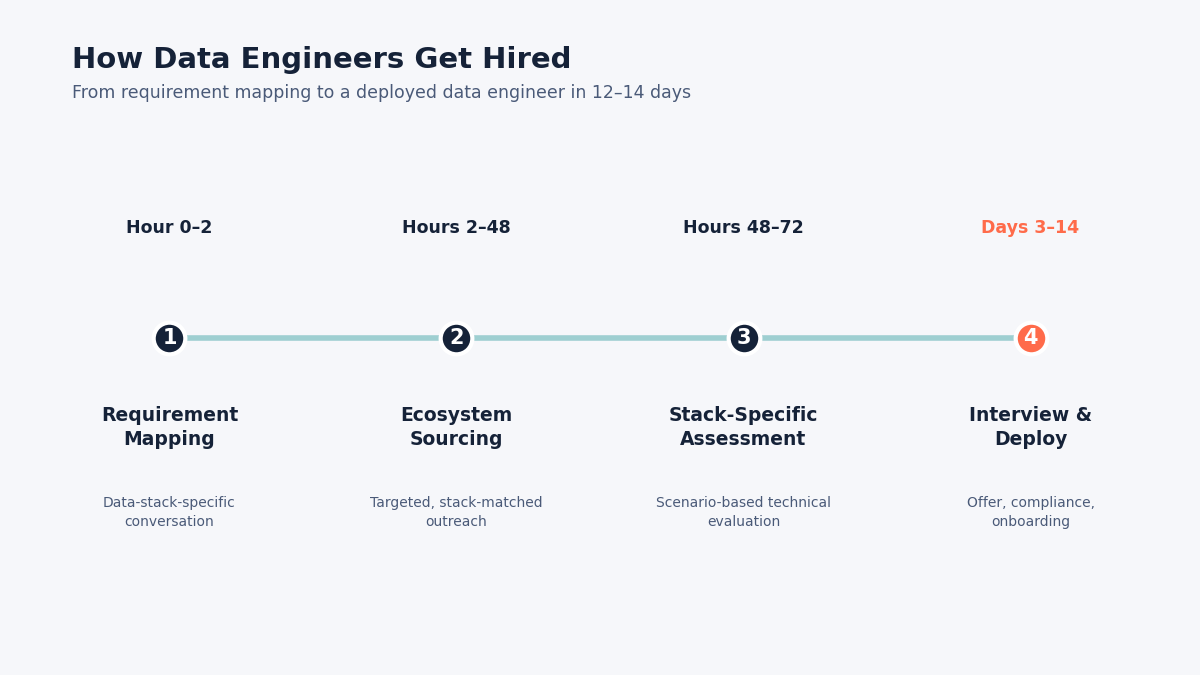
Hour 0-2: Data-stack-specific requirement mapping. A detailed conversation about the exact data technologies, the pipeline architecture (batch, streaming, hybrid), the data volumes, the downstream consumers (BI teams, ML teams, application teams), and the candidate profile the data engineering lead would consider ideal. Led by someone who understands data architecture not a recruiter who thinks Snowflake and Databricks are the same thing.
Hours 2-48: Data ecosystem sourcing. The team sources through data engineering community channels, Databricks and Snowflake user groups, Apache foundation contributor networks, and AI-powered matching. The Impetus client partnership provides additional depth into data engineering talent networks that generic agencies don’t access. Not a LinkedIn search for “data engineer.” Targeted outreach to professionals whose production experience matches the client’s specific stack.
Google AI Accelerator powers the matching layer identifying candidates whose technology profile matches the specific tools, scale, and seniority the client needs. AI handles pattern matching across profiles. Vijay Kiran’s framework handles quality validation through in-house assessment.
Hours 48-72: Stack-specific assessment. Certification verification where applicable (Snowflake SnowPro, Databricks Certified, AWS Data Analytics). Then the real assessment: scenario-based evaluation designed for the client’s specific data stack.
A Snowflake assessment presents real warehouse optimization challenges, query performance on billion-row tables, cost management across multiple warehouses, data sharing configuration for cross-organization access.
A Databricks assessment presents lakehouse architecture decisions Delta Lake table design, Unity Catalog governance, Spark job optimization for cost and performance.
An Ab Initio assessment evaluates GDE graph design, parallelism configuration, and performance tuning skills that only come from production Ab Initio experience.
Communication assessment happens in parallel. Data engineers work with analytics teams, ML engineers, product managers, and business stakeholders. The ability to explain pipeline architecture decisions, data quality trade-offs, and delivery timelines to non-technical stakeholders is assessed specifically.
Hours 48-72: Delivery of 3-5 stack-assessed profiles. Each profile includes technology-specific assessment notes. Not “this person knows data engineering.” Rather: “this person has built production Snowflake pipelines processing 2TB daily with Airflow orchestration and debt transformations, managed $15K/month Snowflake compute costs down to $8K through optimization, and can start in 2 weeks.” Specific. Verifiable. Interview-ready.
Days 3-14: Interviews, offer, deployment. Full coordination. Compliance handled for contract roles (PF, ESI, gratuity, professional tax). CMMI Level 5 processes ensure systematic, auditable operations.
Why Most Data Engineering Hiring Fails Three Patterns
Stack mismatch disguised by the “data engineer” title. The client needs a Snowflake engineer. The agency sends an Informatica developer. Both are “data engineers.” The Informatica developer has never written a Snowflake query. The client discovers this in the technical interview. Two weeks wasted. The cycle restarts.
Supersourcing’s stack-specific assessment prevents this. A Snowflake evaluation is a fundamentally different assessment from an Informatica evaluation. If the candidate’s real expertise is Informatica, the assessment catches it before the client sees the profile.
Scale mismatch. The client processes 500TB daily across 100+ sources. The agency sends a data engineer whose largest pipeline processed 5GB. The engineer is technically competent at a small scale. They’re overwhelmed by the architecture complexity, the performance requirements, and the operational challenges of enterprise-scale data infrastructure. The mismatch becomes apparent after 3-4 weeks once they’re already embedded in the team.
The team’s assessment evaluates for scale specifically. Scenario questions present enterprise-scale challenges, partition strategies for billion-row tables, cost management at $50K+/month cloud data spend, multi-team data governance. Candidates whose experience is small-scale can’t answer these convincingly. The assessment catches the mismatch.
Architecture blindness. The data engineer writes clean Spark code. The pipeline runs. But the data model is wrong denormalized where it should be dimensional, missing slowly changing dimension logic, no data quality checks, no lineage tracking. The pipeline produces data that’s technically correct but analytically useless. Fixing the architecture means rebuilding the pipeline from scratch.
Vijay Kiran’s assessment framework evaluates architecture thinking alongside code capability. The assessment asks candidates to design a data pipeline for a real business scenario, not just code a transformation. The design reveals whether they think in architecture or just in code. This distinction is what prevents costly rebuilds.
What Global Companies Get With Supersourcing for Data Engineering
Mayank Pratap leads the company personally. The enterprise client talks to the founder.
Vijay Kiran who built engineering hiring at Flipkart ($35B valuation, millions of daily transactions, one of Asia’s most sophisticated data infrastructures) and two other unicorn companies runs assessment. The data engineering quality bar is set by someone who hired the data engineers that built Flipkart’s data platform.
Impetus, a data engineering-focused company, is a direct client partner. This partnership reflects specific depth in data engineering talent that generic staffing agencies don’t have.
Stack-specific assessment across every data technology: Snowflake, Databricks, Spark, Airflow,
Ab Initio, Kafka, dbt, Informatica, Power BI, QlikSense, SAS, data modelling, and data leadership. Not generic “data engineer” screening. Evaluation designed for the exact technology and scale the client needs.
48-72 hours to assess shortlist. 12-14 days to deploy data engineer. 30-day replacement guarantee on permanent placements.
CMMI Level 5 for enterprise procurement compliance. Google AI Accelerator for AI-powered talent matching. LinkedIn Top Startup India twice. Wipro, Virtusa, Impetus as direct client partners. Backed by Vijay Shekhar Sharma.
Clients served include Paytm, Groww, KPMG, Adani, Porch Group (US), DataArt, Mishcon de Reya GCC, SpotDraft, NeST Digital, Immersify Education (UK), and Urban Science (US).
Transparent pricing. Stack-specific rates. No hidden margins.
Let’s Talk Data
If you have data engineering positions open Snowflake architects, Databricks engineers,
Spark developers, Airflow pipeline builders, Ab Initio specialists, Kafka streaming engineers, Big Data Leads, or Head of Data roles and your current staffing approach is sending generic “data engineer” resumes that don’t match your specific stack, email me.
mayank@supersourcing.com. The founder. Tell me the data stack, the pipeline architecture, the data volumes, and the timeline. The team will have 3-5 stack-assessed, interview-ready profiles in your inbox within 48-72 hours.
No commitment. No contract. Just assessed profiles for the exact data specialisation you need.
Mayank Pratap Co-founder, Supersourcing mayank@supersourcing.com | supersourcing.com
Google AI Accelerator 2024 · CMMI Level 5 · LinkedIn Top Startup India (Twice) · Talent Director: Ex-Flipkart, 3 Unicorn Hiring Ops · Impetus / Wipro / Virtusa client Partner · Backed by Vijay Shekhar Sharma
Frequently Asked Questions
How much does it cost to hire data engineers in India?
Data engineer rates in India range from $25-$65/hour depending on technology and seniority. Snowflake and Databricks specialists command $35-$65/hour. Spark/Scala engineers range $30-$50/hour. Ab Initio and legacy ETL specialists range $35-$55/hour. Power BI/QlikSense developers range $20-$35/hour. These represent 50-65% savings versus US rates. Supersourcing provides exact rates after understanding the specific data stack and engagement model.
How fast can Supersourcing provide data engineers?
3-5 assessed, interview-ready data engineering profiles within 48-72 hours. Full deployment averages 12-14 days. Each candidate is assessed for their specific data technology not through a generic coding test. Impetus vendor partnership provides additional depth in data engineering talent sourcing. Google AI Accelerator powers matching speed. Vijay Kiran’s framework ensures quality.
What data technologies can Supersourcing hire for?
All major data technologies: Snowflake (architecture, SnowPipe, data sharing, optimization), Databricks (Spark, Delta Lake, Unity Catalog), Apache Spark and Scala, Apache Airflow, Ab Initio (GDE, Express>It), Apache Kafka (streaming, Connect, ksqlDB), dbt, Informatica (IICS, PowerCenter), Power BI, QlikSense, SAS, data modelling (Kimball, Data Vault), SQL optimization, and data leadership roles (Head of Data, Data Engineering Director).
Why is it hard to hire data engineers?
Four reasons: the role barely existed 8 years ago so the talent pipeline hasn’t caught up, the technology landscape changes every 18 months creating constant skill gaps, data engineering requires a rare combination of software engineering plus distributed systems plus SQL plus domain tools, and global demand has grown 340%. India has the deepest data engineering talent pool outside the US, making it the most viable market for global enterprises.
Does Supersourcing have data engineering-specific expertise?
Yes. Impetus Technologies, a company specifically focused on big data and data engineering, is a direct Supersourcing client partner. The team has placed Big Data Engineers, Big Data Leads, Data Modelling specialists, Snowflake engineers, Databricks engineers, Ab Initio developers, Airflow engineers, Kafka engineers, and data analytics specialists. Vijay Kiran’s assessment framework includes data-engineering-specific evaluation criteria developed from hiring data engineers at Flipkart, one of Asia’s most data-intensive companies.
