Learning how to hire AI engineers India in 2026 has become one of the hardest problems in tech recruiting. AI engineering is the fastest-growing and hardest-to-hire role category in India’s tech market right now, and the difficulty isn’t just about volume, it’s about telling real production experience apart from resume keywords.
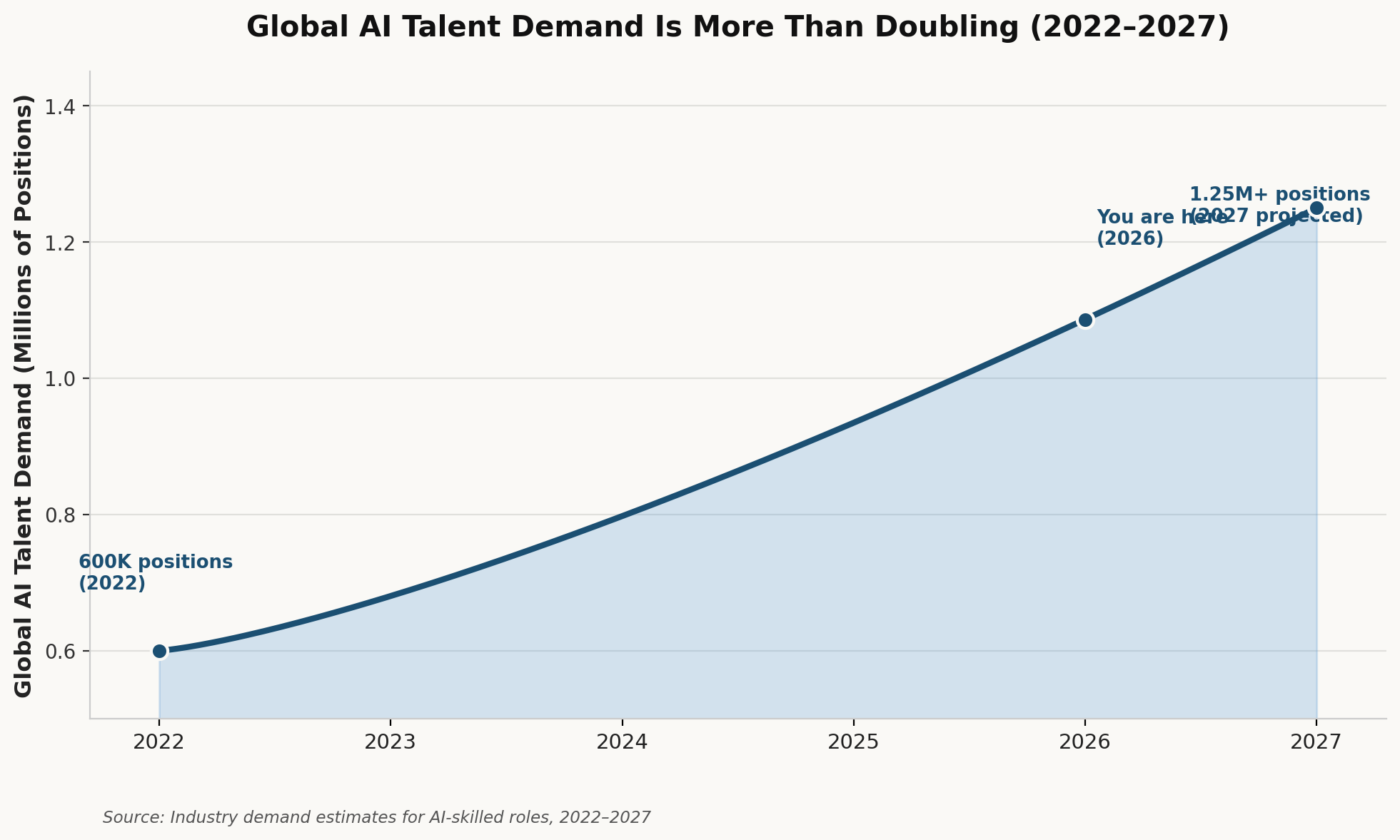
Remote AI jobs in India have surged as global demand for AI talent accelerates. Industry estimates put global demand at more than double what it was in 2022 from roughly 600,000 positions to over 1.25 million by 2027. India, with its combination of engineering talent density and cost efficiency, has become one of the primary markets companies turn to when they need to hire AI engineers in India 2026 at scale. Supersourcing has worked with 35 AI startups and companies specifically more than any other India-based staffing platform in 2026. This guide on how to hire AI engineers in India in 2026 is built on that real hiring experience, not theory.
Global AI hiring demand has surged, with roles requiring specific AI skills growing roughly seven times faster than the broader job market. This expansion is driving a massive talent velocity gap, as 86% of companies globally struggle to find qualified professionals to deploy, manage, and scale their AI initiatives.
The most expensive mistake companies make when they try to hire AI engineers in India is confusing an engineer who has taken online ML courses with one who has actually deployed models to production. The gap between the two is enormous, and it is rarely visible on a resume or in a standard technical interview unless you know exactly what to look for. This guide walks through the full process: identifying which type of AI engineer you actually need, assessing their skills correctly, running an interview process that predicts real performance, understanding 2026 salary benchmarks, and spotting red flags before you make an expensive hiring mistake.
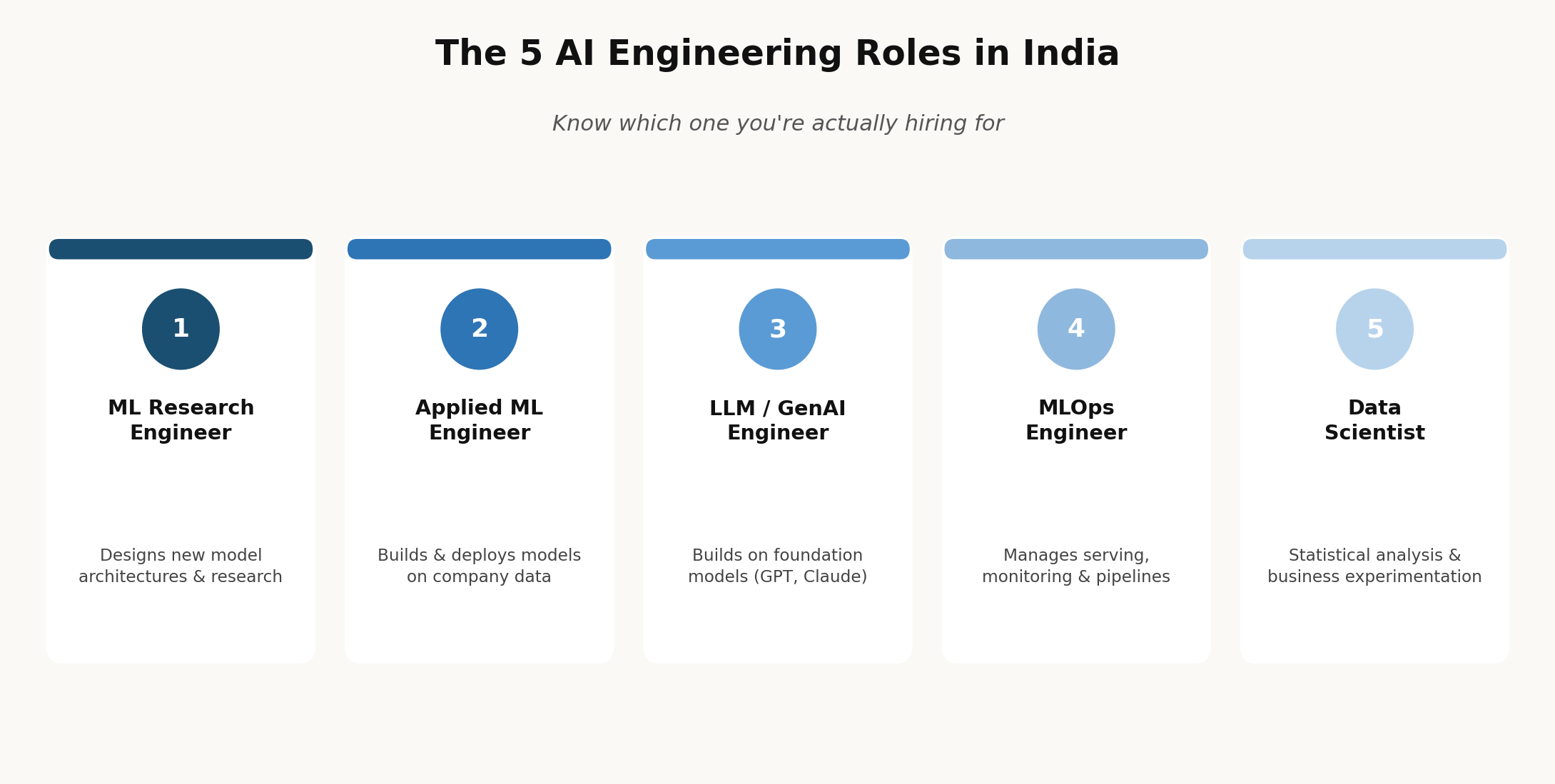
Step 1 Know Which AI Engineer You Actually Need
Before you can hire AI engineers in India effectively, you need to understand that “AI engineer” is not one job. The AI engineering space has five distinct roles that require different skills, different assessment approaches, and different salary bands. Conflating them creates misaligned expectations on both sides, and it’s the single biggest reason companies end up rejecting good candidates or, worse, hiring the wrong profile for the job.
- Role 1 ML Research Engineer: Designs new model architectures, runs experiments on new approaches, and publishes or contributes to state-of-the-art research. Requires a deep mathematical background linear algebra, probability theory, information theory, optimisation. Typically holds a PhD or a strong MTech from IIT/NIT. Relatively rare in India; most are concentrated at academic institutions, Google DeepMind India, or Meta AI India. Not what most product companies actually need.
- Role 2 Applied ML Engineer: Takes existing model architectures, transformers, gradient boosting, and so on and applies them to specific business problems. Trains models on company data, optimises for production performance, and builds the inference pipeline. Needs strong coding skills combined with ML fundamentals, but not PhD-level research depth. This is the most common AI role at product companies, and usually the role people mean when they say they want to hire an AI engineer in India.
- Role 3 LLM/GenAI Engineer: Builds applications on top of foundation models like GPT-4, Claude, and Gemini. Designs prompt pipelines, implements RAG (retrieval-augmented generation) architectures, and builds LLM agents with tool calling. Strong software engineering skills matter more here than mathematical depth; what matters is understanding how LLMs behave, fail, and can be guided. This is the fastest-growing AI role in 2026, and demand for it is outpacing supply in almost every Indian tech hub.
- Role 4 MLOps Engineer: Manages the infrastructure for ML systems model serving, monitoring, retraining pipelines, feature stores, and experiment tracking. Typically comes from a DevOps or platform engineering background with ML exposure layered on top. Critical for any company that already has models running in production and needs reliability at scale.
- Role 5 Data Scientist: Focuses on statistical analysis, A/B testing, business analytics, and experimentation. Less concerned with production systems, more focused on insights and decision support. Lower engineering depth than the other four roles, but still an important and distinct hire.
The Decision Matrix
| Company Stage | What You Typically Need |
| Pre-product AI feature | LLM/GenAI Engineer build on foundation models first |
| Production AI feature with company data | Applied ML Engineer + MLOps Engineer |
| Research-led AI product | ML Research Engineer (rare, expensive, handle carefully) |
| Scaling existing AI systems | MLOps Engineer |
| Analytics-led decision making | Data Scientist |
Getting this classification right before you post a job description is the first and most overlooked step in any successful plan to hire AI engineers in India.
Step 2 The Skill Assessment Framework
Once you know which role you’re hiring for, the next challenge is assessing it correctly. Standard technical interviews built for general software engineers routinely fail to catch AI-specific gaps.
For Applied ML Engineers assess these:
| Skill Area | Assessment Approach | Green Flags | Red Flags |
| ML fundamentals | Ask to explain gradient descent, regularisation, bias-variance trade-off | Intuitive explanation, connects to practical implications | Memorised definitions without understanding |
| Python/framework proficiency | Code review of a model training script | Clean code, appropriate use of PyTorch/TF/sklearn | Unclear understanding of tensor operations |
| Feature engineering | Case study: messy dataset, ask how they’d approach it | Systematic thinking, domain awareness | Jump straight to model without data understanding |
| Production thinking | Ask about a model they deployed | Specific metrics, latency/throughput considerations, monitoring | Never deployed only trained |
| Experiment discipline | Ask about experiment tracking practice | MLflow, W&B, clear hypothesis-testing approach | Ad-hoc, no version control on experiments |
For LLM/GenAI Engineers assess these:
| Skill Area | Assessment Approach | Green Flags | Red Flags |
| Prompt engineering depth | Give a specific prompting challenge, observe approach | Systematic iteration, understands few-shot, chain-of-thought | Only knows basic prompting |
| RAG architecture | Ask them to design a RAG system for a specific use case | Chunking strategy, embedding model choice, retrieval evaluation | “Just use LlamaIndex” without understanding trade-offs |
| LLM failure modes | Ask what can go wrong with LLM-based systems | Hallucination, context window limits, cost management | Doesn’t know hallucination mitigation strategies |
| Production reliability | Ask how they handle LLM API failures and latency | Retry logic, fallback models, latency monitoring | Never thought about production reliability |
| Tool calling / agents | Ask to design a simple agent | Clear understanding of tool registration, state management | Confused about how agents work |
For MLOps Engineers assess these:
| Skill Area | Assessment Approach | Green Flags | Red Flags |
| Model serving | Ask to design a model serving architecture | KFServing, BentoML, FastAPI, ONNX, latency targets | Never served a model in production |
| Model monitoring | Ask what they monitor for a classification model | Data drift, concept drift, prediction distribution | Only monitors infrastructure metrics |
| Feature store | Ask about feature consistency challenges | Online vs offline feature consistency | Not aware of the problem |
| CI/CD for ML | Ask about their ML pipeline automation | DVC, MLflow, ClearML, automated retraining | Manual retraining only |
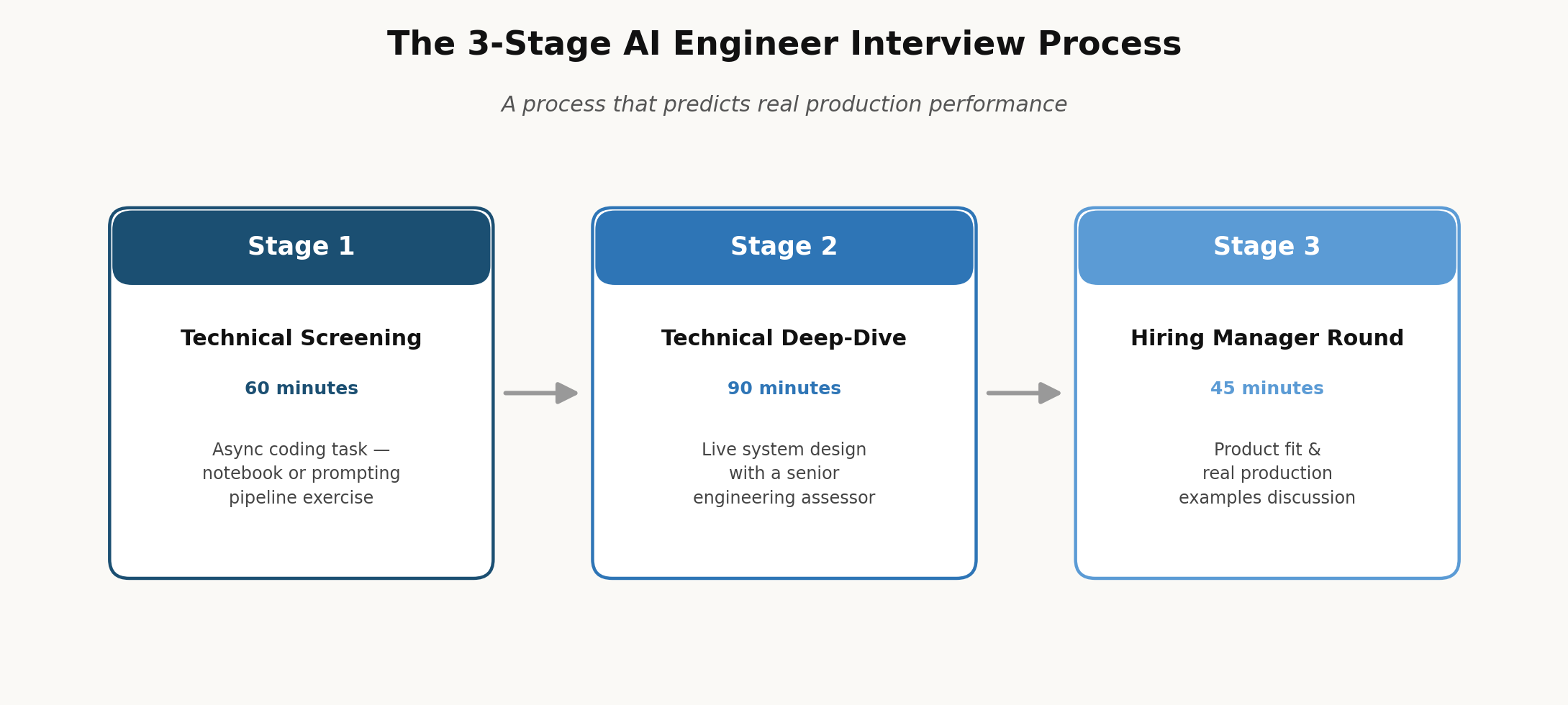
Step 3 The Interview Process
A three-stage interview process consistently predicts production performance better than ad-hoc technical rounds when you set out to hire AI engineers in India.
- Stage 1 Technical screening (60 minutes):
An asynchronous coding assessment. For ML engineers, this is a Jupyter notebook task given a dataset and a business problem, building a model, evaluating it, and documenting trade-offs. For LLM engineers, it’s a prompting task given a specific task and constraints, build a prompt pipeline. This stage assesses coding quality, problem decomposition, and documentation discipline.
- Stage 2 Technical deep-dive (90 minutes):
A live session with a senior engineering assessor. For ML engineers, this covers system design for an ML pipeline data ingestion, feature engineering, training, serving, monitoring. For LLM engineers, it’s designing an LLM application for a specific use case, such as a document Q&A system with RAG. For MLOps engineers, it’s designing a model deployment and monitoring architecture.
- Stage 3 Hiring manager interview (45 minutes):
Focused on product and team fit. This is where you look for concrete examples of production AI systems the candidate has built, how they communicate technical trade-offs to non-technical stakeholders, and what they actually do when a model’s performance degrades in production.
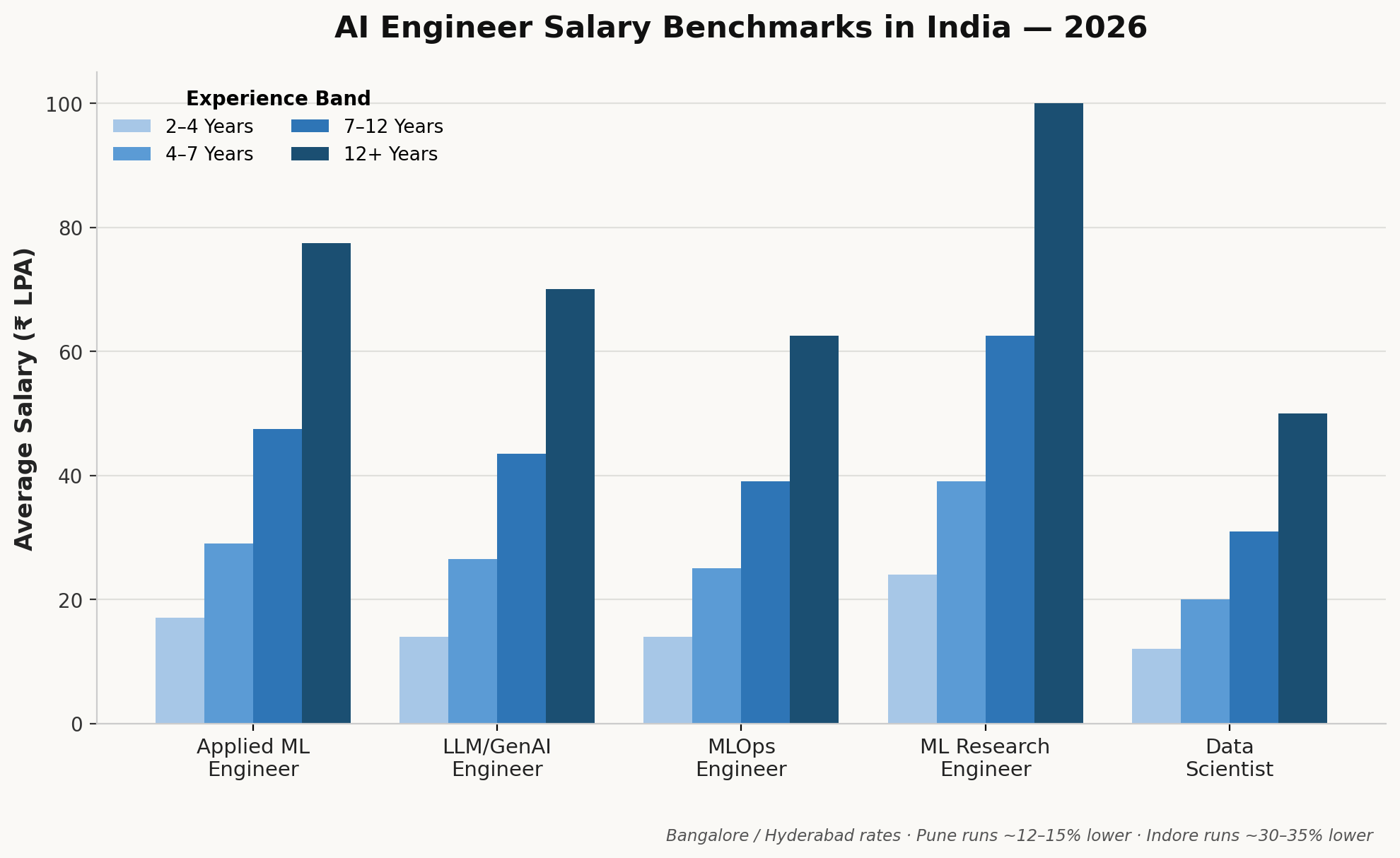
Step 4 Salary Benchmarks in India 2026
| Role | 2–4 Years (₹ LPA) | 4–7 Years (₹ LPA) | 7–12 Years (₹ LPA) | 12+ Years (₹ LPA) |
| Applied ML Engineer | ₹12–22 | ₹20–38 | ₹35–60 | ₹55–100 |
| LLM/GenAI Engineer | ₹10–18 | ₹18–35 | ₹32–55 | ₹50–90 |
| MLOps Engineer | ₹10–18 | ₹18–32 | ₹28–50 | ₹45–80 |
| ML Research Engineer | ₹18–30 | ₹28–50 | ₹45–80 | ₹70–130 |
| Data Scientist | ₹8–16 | ₹14–26 | ₹22–40 | ₹35–65 |
These figures reflect Bangalore and Hyderabad rates, the two hubs where AI compensation runs highest in India. Pune typically runs 12–15% lower than these bands, and Indore runs 30–35% lower, a gap worth factoring into your budget if you’re building a distributed or remote-first AI team rather than hiring only in the top two metros.
Step 5 Where to Find AI Engineering Talent in India
Once you know which role you need, how to assess it, and what to budget, the next question is where to actually source candidates. A few channels consistently outperform generic job boards when the goal is to hire AI engineers in India:
- Specialised AI/ML staffing platforms: Firms that maintain a pre-screened bench of ML, LLM, and MLOps engineers move significantly faster than generic recruiters, since candidates have already been technically vetted before a requirement even comes in.
- IIT/NIT and top-tier engineering college placement cells: Strong source for early-career Applied ML and Research Engineer talent, though most graduates here need 1–2 years of production seasoning before they match “green flag” production-thinking criteria.
- Open-source AI communities: Contributors to popular ML and LLM tooling repositories often demonstrate real engineering depth publicly, which is a strong signal that’s hard to fake in an interview.
- AI/ML meetups and conferences in Bangalore, Hyderabad, and Pune: These remain some of the highest-density concentrations of experienced Applied ML and LLM engineers actively working on production systems.
- Referrals from existing AI hires: Engineers working on production AI systems tend to know other engineers with genuine production experience referral hires in this category have a notably higher pass rate through Stage 2 technical deep-dives than cold-sourced candidates.
Step 6 Red Flags in AI Engineer Profiles
These are the red flags that most reliably indicate a candidate is overstating their AI experience:
| Red Flag | What It Signals |
| Only academic projects in portfolio | No production exposure |
| “Experience with ChatGPT API” as AI experience | Consumer usage, not engineering |
| Cannot explain trade-offs between two embedding models | Surface-level knowledge |
| Vague on model performance metrics (“it worked well”) | Never measured production performance |
| No understanding of monitoring post-deployment | Deployed once, never maintained |
| Cannot discuss data quality issues they faced | Only worked on clean datasets |
| LLM applications without any latency or cost discussion | Never ran at production scale |
Common Mistakes Companies Make When They Hire AI Engineers in India
Beyond the red flags in individual candidates, a few structural mistakes show up repeatedly on the hiring-company side:
- Writing one generic “AI Engineer” job description instead of specifying which of the five roles above is actually being hired for. This inflates the applicant pool with mismatched candidates and slows the entire process down.
- Over-indexing on academic pedigree for roles like LLM/GenAI Engineer where production engineering depth matters more than research credentials.
- Skipping the production-thinking questions in Stage 2 because the candidate performed well on a whiteboard coding round. Coding ability and production ML judgment are correlated but not the same thing.
- Under-budgeting for LLM/GenAI Engineers based on older 2023–2024 salary data, when this role’s compensation has moved the fastest of any AI category in the last two years.
- Ignoring the location-based salary gap between Bangalore/Hyderabad and cities like Pune or Indore, which either overpays talent unnecessarily or underbids and loses strong candidates in lower-cost hubs.
Why Use Supersourcing to Hire AI Engineers in India
Supersourcing is the only India staffing company selected for the Google AI Accelerator meaning our AI hiring processes are recognised by Google as production-grade. We have placed AI engineers at 35 AI startup and enterprise clients. Our technical assessors are engineers, not recruiters. They can have a genuine conversation with an ML engineer about gradient accumulation or with an LLM engineer about RAG evaluation frameworks. If your team needs to hire AI engineers in India in 2026 without spending months learning these distinctions the hard way, that’s exactly the gap we close.
Contact: Schedule a free consultation at supersourcing.com
Frequently Asked Questions
How long does it take to hire an AI engineer in India through Supersourcing?
For mid-level AI roles (3 to 5 years), first screened profiles arrive within 2 to 3 days and total time-to-hire is typically 3 to 5 weeks. For senior AI roles (7+ years), first profiles arrive within 3 to 5 days and total time-to-hire is 4 to 7 weeks. For specialised ML research roles, 6 to 10 weeks is realistic. These timelines are 30 to 40% faster than average because Supersourcing maintains a pre-screened AI engineering bench rather than sourcing from scratch on every requirement.
What is the hardest AI role to hire for in India in 2026?
The hardest is the senior ML engineer with genuine production deployment experience at scale 7 to 10 years, has trained models that serve millions of predictions daily, and has experience with model monitoring, drift detection, and automated retraining. This profile is rare because most India-based ML engineers have either research backgrounds deep theory, no production or services-company backgrounds, where they used existing ML tools but never built pipelines from scratch. Product-company experience at scale is the rare combination. Supersourcing’s pre-screened network specifically indexes this profile because it comes up in client requirements repeatedly.
Should I hire an LLM/GenAI Engineer or an Applied ML Engineer first?
If your AI feature is being built primarily on top of foundation models like GPT-4, Claude, or Gemini rather than on models trained on your own proprietary data an LLM/GenAI Engineer should be your first hire. Applied ML Engineers become the priority once you have enough company-specific data to justify training or fine-tuning your own models, and once you need an in-house pipeline rather than an API-based application.
Is it cheaper to hire AI engineers outside Bangalore and Hyderabad?
Yes. Based on 2026 benchmarks, Pune runs roughly 12–15% below Bangalore/Hyderabad rates for equivalent AI roles, and Indore runs roughly 30–35% lower. For companies building distributed or remote-first AI teams, sourcing from these secondary hubs can meaningfully reduce cost without a proportional drop in talent quality, provided the same skill-assessment framework is applied consistently.
