The $2.8M GenAI Program That Produced Nothing Production-Ready
A US-based financial services company 6,000 employees, Salesforce CRM, extensive document management infrastructure approved a $2.8M GenAI program. The brief: an intelligent document processing system for loan application analysis, a RAG-based knowledge assistant for credit analysts, and an automated regulatory report summarisation tool. Fourteen months. Nine India-based GenAI engineers.
Enterprise GenAI initiatives are moving from experimentation to high-stakes production systems but most are still failing to deliver real business value. The gap isn’t in ambition or budget; it’s in execution.
That’s where hiring GenAI & LLM engineers becomes a critical inflection point for enterprise buyers. Many teams end up hiring engineers who can build impressive demos using LangChain, vector databases, and RAG pipelines but lack the experience to deploy reliable, scalable, and compliant AI systems in production environments.
The urgency is only increasing. According to McKinsey, generative AI could add up to $4.4 trillion annually to the global economy, pushing enterprises to accelerate real-world GenAI deployments across functions.
The result? Expensive pilots, unstable outputs, and systems that never make it to production. This guide breaks down what enterprise buyers get wrong and how to hire GenAI and LLM engineers who can actually build production-grade AI systems in 2026.
This guide is what that CTO needed before he approved the SOW.
TL;DR 8 Answers Before You Read Further
| Question | Answer |
| What does a Senior GenAI Engineer from India cost? | $55–82/hr fully loaded. A GenAI / LLM Architect runs $85–135/hr. Section 5 has full rates. |
| What's the most important thing to verify? | Production deployment. Not demos, not internal tools, not hackathon projects. User-facing systems with real load, latency SLAs, and monitoring. |
| Which Indian city has the deepest GenAI talent? | Bangalore dominates. Highest concentration of ML/AI engineers with production experience from product companies and US tech GCCs. |
| Is there a GenAI certification that matters? | No single standard as of May 2026. AWS, Google, and Microsoft AI/ML certifications exist but don't validate production LLM deployment. Verification is entirely interview and portfolio dependent. |
| What's the biggest CV inflation problem in GenAI? | "LLM Architect" with no production system, no GitHub activity, and no named deployment. Everyone added GenAI to their CV in 2023–2024. Fewer than 15% have built production systems. |
| Agentic AI: how many Indian engineers have production experience? | Fewer than 500 engineers in India have shipped production agentic AI systems (LangGraph, AutoGen, CrewAI) serving real users. Most "agentic AI experience" is from 2023–2024 tutorials. |
| What's typical attrition for GenAI engineers? | 18–25% the highest of any stack in this guide series. GenAI is the hottest engineering market globally. Top GenAI engineers have options everywhere. |
| What's the single biggest hiring mistake? | Hiring based on framework knowledge (LangChain, LlamaIndex) instead of production system delivery. The frameworks are easy to learn. Shipping reliable AI systems at scale is hard. |
Are You Actually Ready for This?
GenAI programs fail for two distinct reasons: talent quality (hiring demo engineers for production roles) and buyer readiness (not knowing what production GenAI requires before you start). Score yourself.
Score each: 0 (not in place), 2 (partially), 4 (done).
| # | Criterion | Score |
| 1 | Use case defined with specific success metrics not “build an AI chatbot” | 0/2/4 |
| 2 | Data strategy confirmed which data the AI system can access, what’s off-limits | 0/2/4 |
| 3 | Acceptable hallucination rate defined what percentage of incorrect outputs is tolerable | 0/2/4 |
| 4 | Human-in-the-loop escalation path designed when does a human review AI output | 0/2/4 |
| 5 | Latency SLA defined what response time is acceptable for each use case | 0/2/4 |
| 6 | Cost per query budget confirmed LLM API costs at scale can be significant | 0/2/4 |
| 7 | Compliance and regulatory review completed can AI-generated output be used in your regulatory context | 0/2/4 |
| 8 | Model selection made or evaluation framework defined | 0/2/4 |
| 9 | Interview panel with production AI experience available within 5 business days | 0/2/4 |
| 10 | Legal SLA under 15 days for MSA review | 0/2/4 |
| 11 | Audit trail requirements defined what decisions need to be logged and explainable | 0/2/4 |
| 12 | Security review completed prompt injection, data leakage, model output sanitisation | 0/2/4 |
| 13 | Escalation path: vendor PM → your AI Lead → your CTO | 0/2/4 |
| 14 | IP ownership for model fine-tuning, RAG pipelines, and prompt engineering in MSA | 0/2/4 |
| 15 | Finance can process USD-denominated invoices within 30 days | 0/2/4 |
What your score means:
| Score | Tier | Reality Check |
| 48–60 | Scaler | Ready. You know what you’re building. |
| 34–46 | Builder | 3–4 gaps. In GenAI, undefined success metrics produce demo projects. Fix before signing. |
| 20–32 | Explorer | You’re funding experimentation, not production delivery. Acknowledge this before signing a production-grade SOW. |
| 0–18 | Pre-Stage | Do an internal AI readiness sprint first. An offshore GenAI team without internal AI leadership will produce impressive demos and no deployable product. |
From the deal floor: A US retail company $800M revenue, Salesforce Commerce Cloud approved a GenAI program with criterion 3 (acceptable hallucination rate) and criterion 7 (compliance review) both at zero. The use case was AI-generated product descriptions at scale.
Month three: the AI was generating product descriptions with incorrect dimensions, wrong material compositions, and fabricated certifications for products in the children’s category.
The program was halted by the legal team. $320K spent. No deployed output. The hallucination rate and compliance questions would have shaped the architecture before the first sprint.
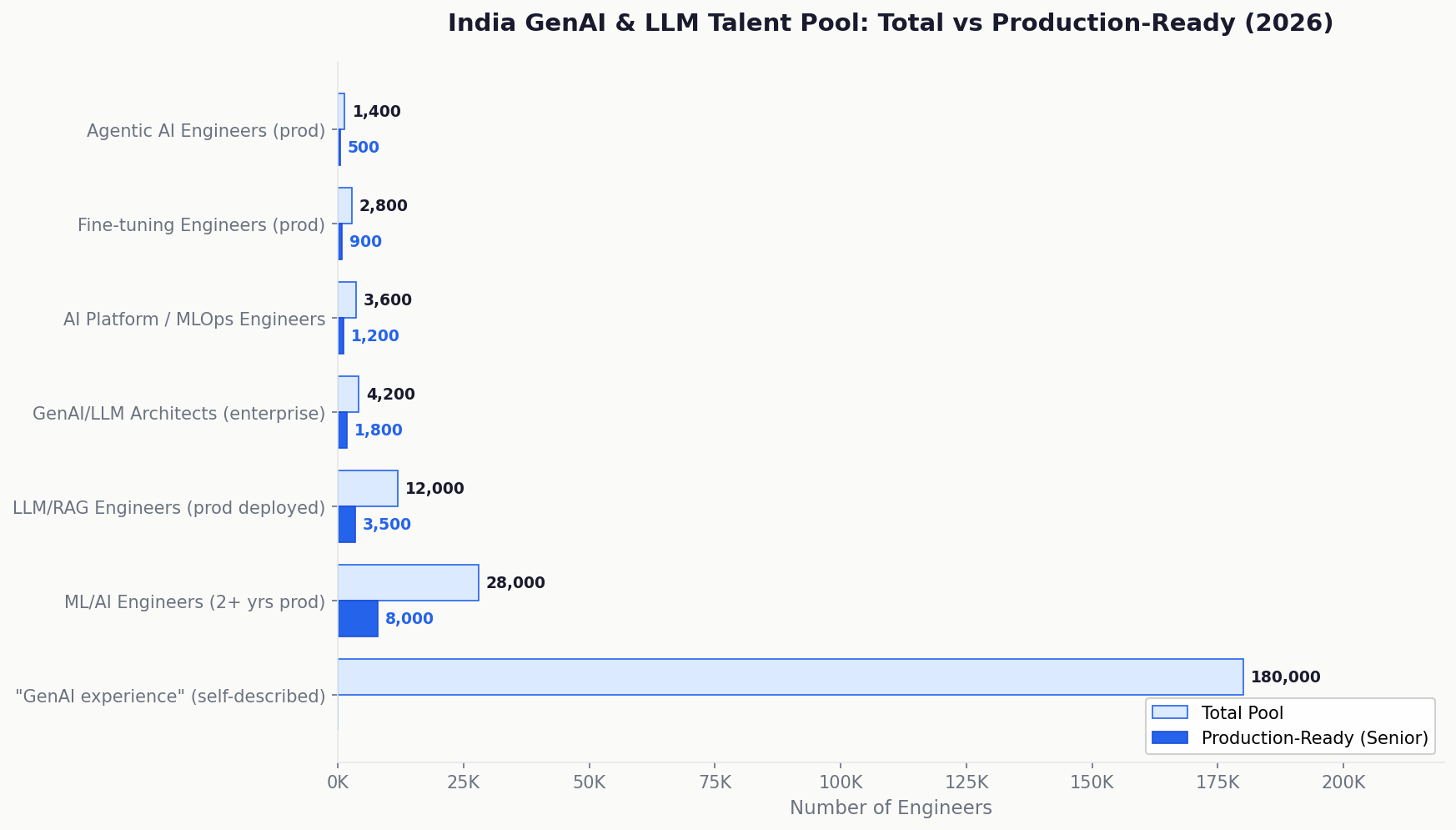
The GenAI & LLM Talent Market in India 2026
India produced more software engineers than any country outside the US in 2025. In 2023 and 2024, a substantial portion of that engineering population added “AI” and “GenAI” to their CVs. This is the defining talent market challenge for GenAI hiring in India, the largest CV inflation event in the history of software engineering.
The pool reality:
| Profile | Estimated India Pool | Production-Ready at Senior Level |
| “GenAI experience” (any level, self-described) | ~180,000 | |
| ML / AI Engineers with 2+ years ML production experience | ~28,000 | ~8,000 |
| LLM / RAG Engineers with production deployment | ~12,000 | ~3,500 |
| GenAI / LLM Architects with enterprise production systems | ~4,200 | ~1,800 |
| Agentic AI engineers with production multi-agent systems | ~1,400 | ~500 |
| Fine-tuning engineers with production fine-tuning delivery | ~2,800 | ~900 |
| AI Platform / MLOps engineers with LLM serving infrastructure | ~3,600 | ~1,200 |
The number that matters: approximately 1,800 GenAI architects in India have built enterprise production systems user-facing, monitored, with latency SLAs and cost controls. This is not a small number. It is a dramatically smaller number than the 180,000 who describe themselves as having GenAI experience.
The tutorial-to-production gap:
This is unique to GenAI compared to every other stack in this guide series. For Murex, SAP, or ServiceNow you either have production experience on the platform or you don’t. The platform access itself is a barrier that filters tutorial-only candidates.
GenAI has no such barrier. OpenAI’s API, Google Gemini, Anthropic Claude, LangChain, LlamaIndex, Pinecone, Chroma all free or low-cost to access. A developer can build a sophisticated-looking RAG application in a weekend using free tools and publish it to GitHub. That application looks identical to a production system on a CV. It is not a production system.
The difference between a demo RAG application and a production RAG application:
| Demo RAG | Production RAG |
| Single PDF or small corpus | Millions of documents, dynamic updates |
| No latency requirement | P95 latency SLA (e.g., <3 seconds) |
| No cost optimisation | Token budget management, model tiering |
| No monitoring | Retrieval quality metrics, hallucination detection |
| No fallback | Circuit breakers, graceful degradation |
| No security | Prompt injection prevention, data access controls |
| No audit trail | Every query and response logged with context |
| Developer uses it | Real users with diverse, unpredictable inputs |
Every item in the production column requires specific engineering decisions that tutorial developers have not made. The interview questions in Section 8 are designed to surface exactly these decisions.
Where the talent lives:
| City | Dominant GenAI Specialisations | Why |
| Bangalore | LLM architecture, RAG systems, agentic AI, MLOps/LLMOps, AI platform engineering | Highest concentration of US tech companies AI GCCs Google, Microsoft, Amazon, Meta, Uber, Flipkart all have significant AI engineering presence. India’s deepest AI talent pool by far. |
| Hyderabad | ML engineering, computer vision, NLP, Microsoft AI ecosystem | Microsoft India AI research presence. Strong in Azure OpenAI and Microsoft Copilot Stack. |
| Pune | Applied ML, recommendation systems, GenAI for enterprise workflows | Growing AI product company ecosystem. Cognizant and Persistent AI practices. |
| Gurgaon | FinTech AI, BFSI AI applications, compliance AI | Financial services AI applications. Regulatory AI use cases. |
| Chennai | NLP for Indic languages, document processing AI, legacy AI modernisation | Strong NLP background from academic institutions. Indic language AI depth. |
| Mumbai | AI for financial services, AI for media and entertainment | BFSI AI applications. Media and content AI. |
Supersourcing Index: Across 86 GenAI placements in the Supersourcing GCC Benchmark 2026, median time-to-fill for a Senior LLM/RAG Engineer (production deployment verified) in Bangalore was 26 calendar days. For a GenAI Architect with enterprise RAG and agentic AI production experience: 38 days. For a Principal AI Architect with LLM serving infrastructure, fine-tuning delivery, and multi-agent production systems: 52 days.
The 2023–2024 CV inflation wave in numbers:
Between Q1 2023 and Q4 2024, approximately 150,000 Indian software engineers added GenAI-related skills to their LinkedIn profiles. The majority: LangChain tutorials, OpenAI API hello world projects, Coursera GenAI certificates, and one-weekend hackathon projects. This is not criticism; learning new skills is positive. The problem is when tutorial experience is presented as production delivery experience on CVs submitted for enterprise GenAI programs.
Red flag: Any vendor claiming “large GenAI bench” without being able to name production systems company name, user volume, latency SLA for each claimed senior engineer within 24 hours is presenting tutorial engineers for production roles.
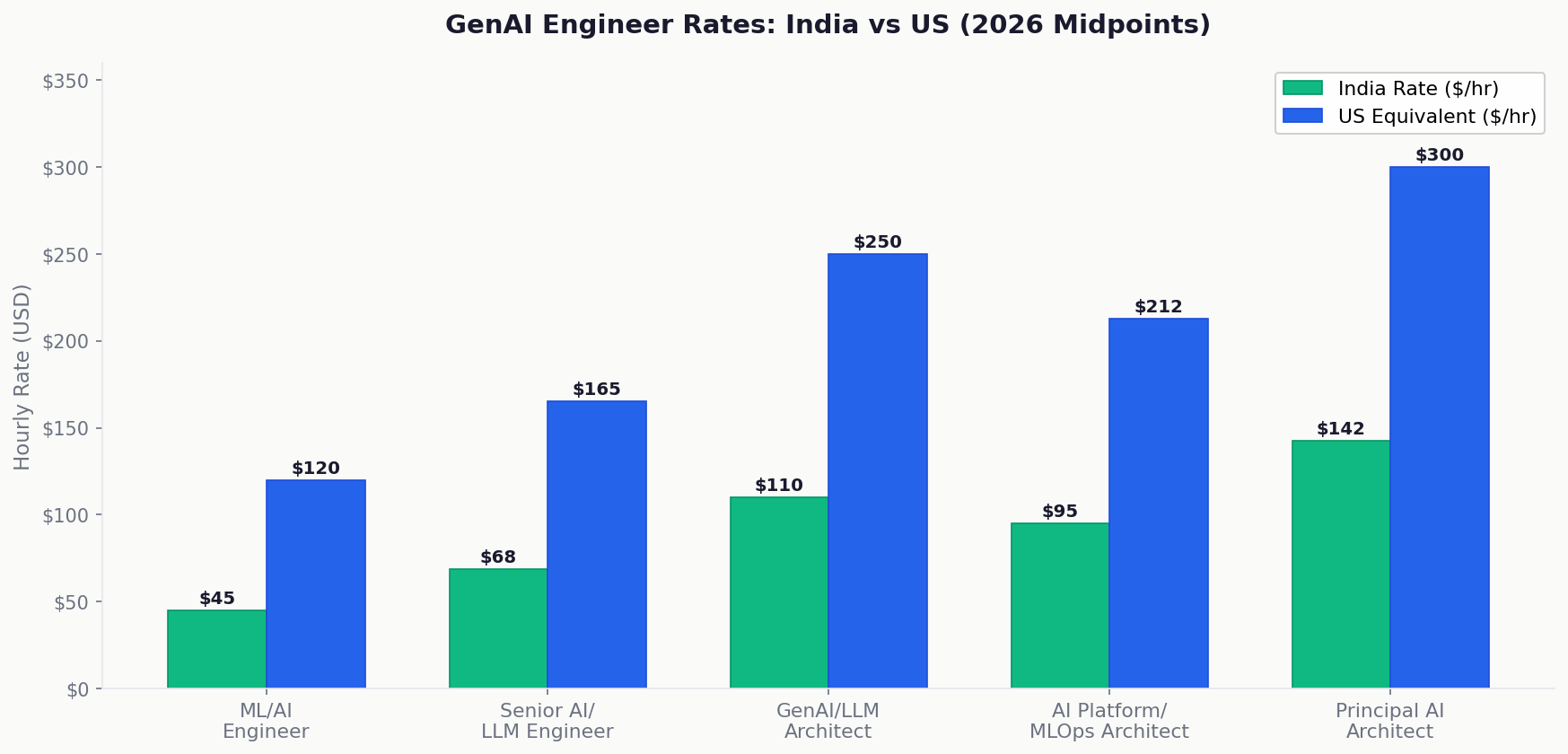
What You’re Really Paying
Rate Table by Level
| Level | Experience | India Rate ($/hr) | US Equivalent ($/hr) | Annual Saving ($) |
| ML / AI Engineer | 2–4 yr | $35–55 | $100–140 | $135K–$176K |
| Senior AI / LLM Engineer | 4–7 yr | $55–82 | $140–190 | $176K–$224K |
| GenAI / LLM Architect | 5–8 yr | $85–135 | $200–300 | $239K–$343K |
| AI Platform / MLOps Architect | 6–10 yr | $75–115 | $175–250 | $208K–$280K |
| Principal AI Architect | 10+ yr | $120–165 | $250–350 | $270K–$385K |
Note: GenAI rates are experience-compressed compared to other enterprise stacks. A 5-year GenAI architect can command rates equivalent to a 10-year SAP architect because production GenAI delivery experience is scarce regardless of total years.
The 4 Cost Layers
- Layer 1 Gross CTC A Senior GenAI Engineer with 5 years production LLM experience earns ₹35–55 LPA. At ₹96.4/$1, that’s $36K–$57K annually $18–28/hr at gross level.
- Layer 2 Employer Burden PF, ESIC, Gratuity, bonus: 22–28% on top of gross CTC.
- Layer 3 Vendor Margin For GenAI specialists: 20–26%. The market is hot, sourcing cost is high, and the attrition risk (18–25%) requires vendors to price in replacement cost.
- Layer 4 What Hits Your Invoice Senior GenAI Engineer: $55–82/hr. At 2,000 hours/year, a 5-engineer GenAI team at blended $70/hr costs $700K annually. US equivalent: $1.6–1.9M. Annual saving on a 5-person team: $900K–$1.2M.
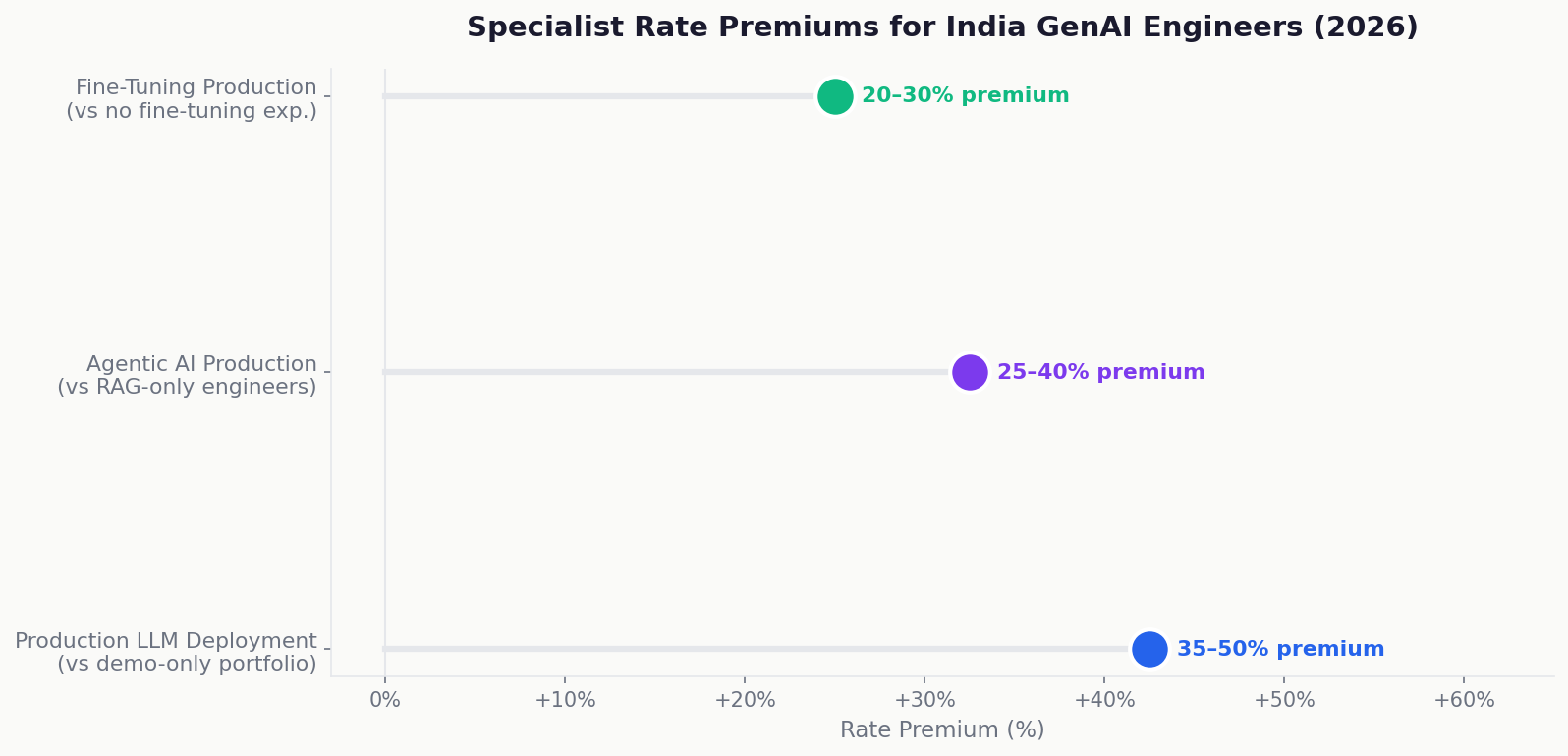
The production premium: Engineers with verified production LLM deployments named system, user count, latency SLA command 35–50% premium over engineers with equivalent years of experience but demo-only portfolios. This premium is real and justified. Production experience is genuinely scarce.
The agentic AI premium: Engineers with production multi-agent system delivery experience (LangGraph, AutoGen, CrewAI, or custom orchestration) command 25–40% premium over RAG-only engineers. Production agentic AI is significantly harder than production RAG tool call reliability, state management, error recovery, and cost control in multi-step agent workflows are engineering challenges that most “agentic AI” developers have not solved in production.
The fine-tuning premium: Engineers with production fine-tuning delivery dataset preparation, training run execution, evaluation framework, production serving command 20–30% premium. True fine-tuning experience (not LoRA on a Colab notebook) is rare. Most “fine-tuning experience” in India is from running someone else’s training script on a cloud GPU with a toy dataset.
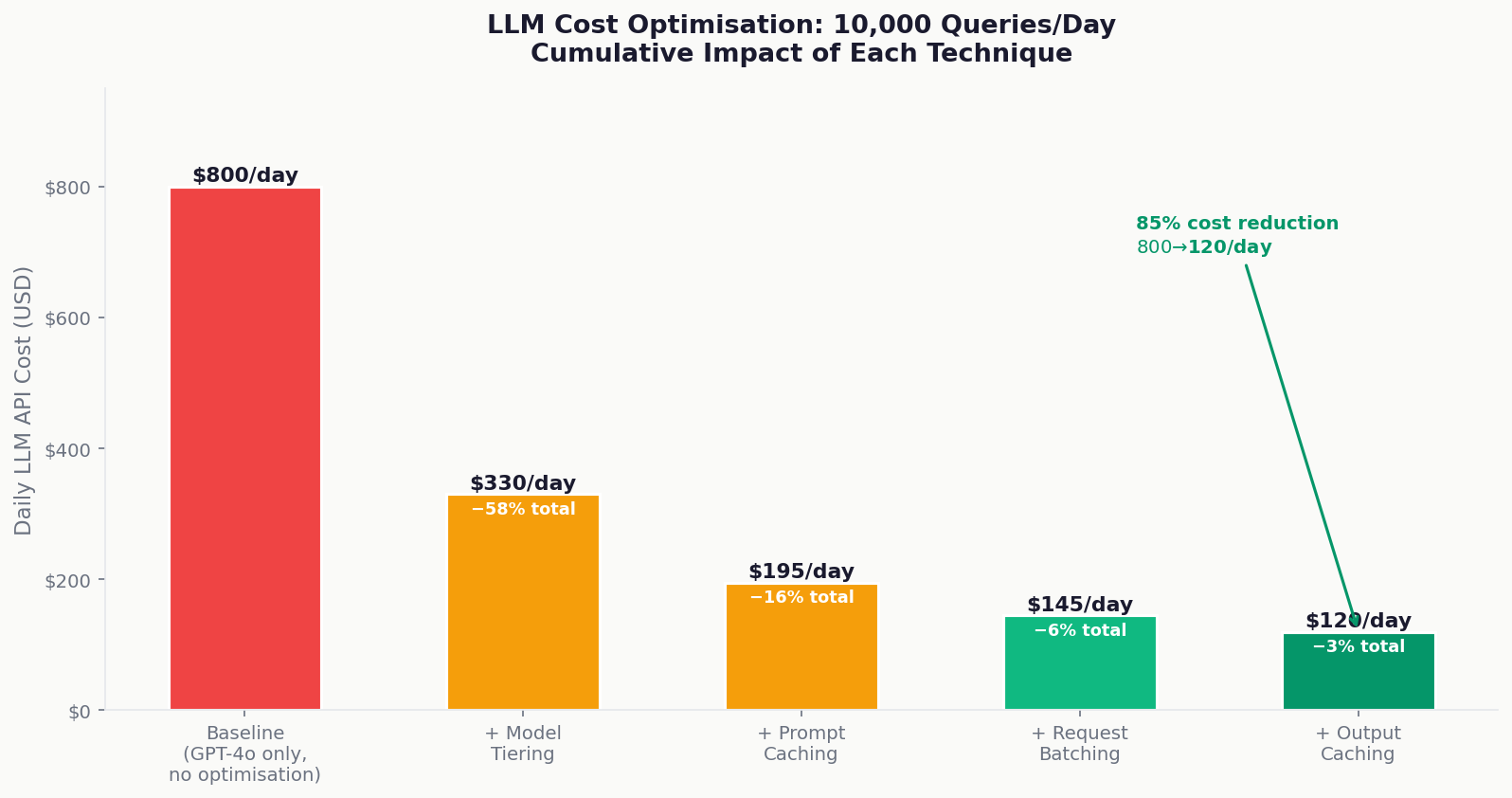
LLM API cost as a program variable: Unlike every other stack in this guide series, GenAI programs have a significant variable cost that sits outside engineering billing LLM API costs. GPT-4o at $5/1M input tokens and $15/1M output tokens can generate material costs at enterprise scale. A RAG system serving 10,000 queries per day at 2,000 tokens average per query costs approximately $1,500/day in API costs alone. This must be in your program budget; it is not part of the engineering billing rate.
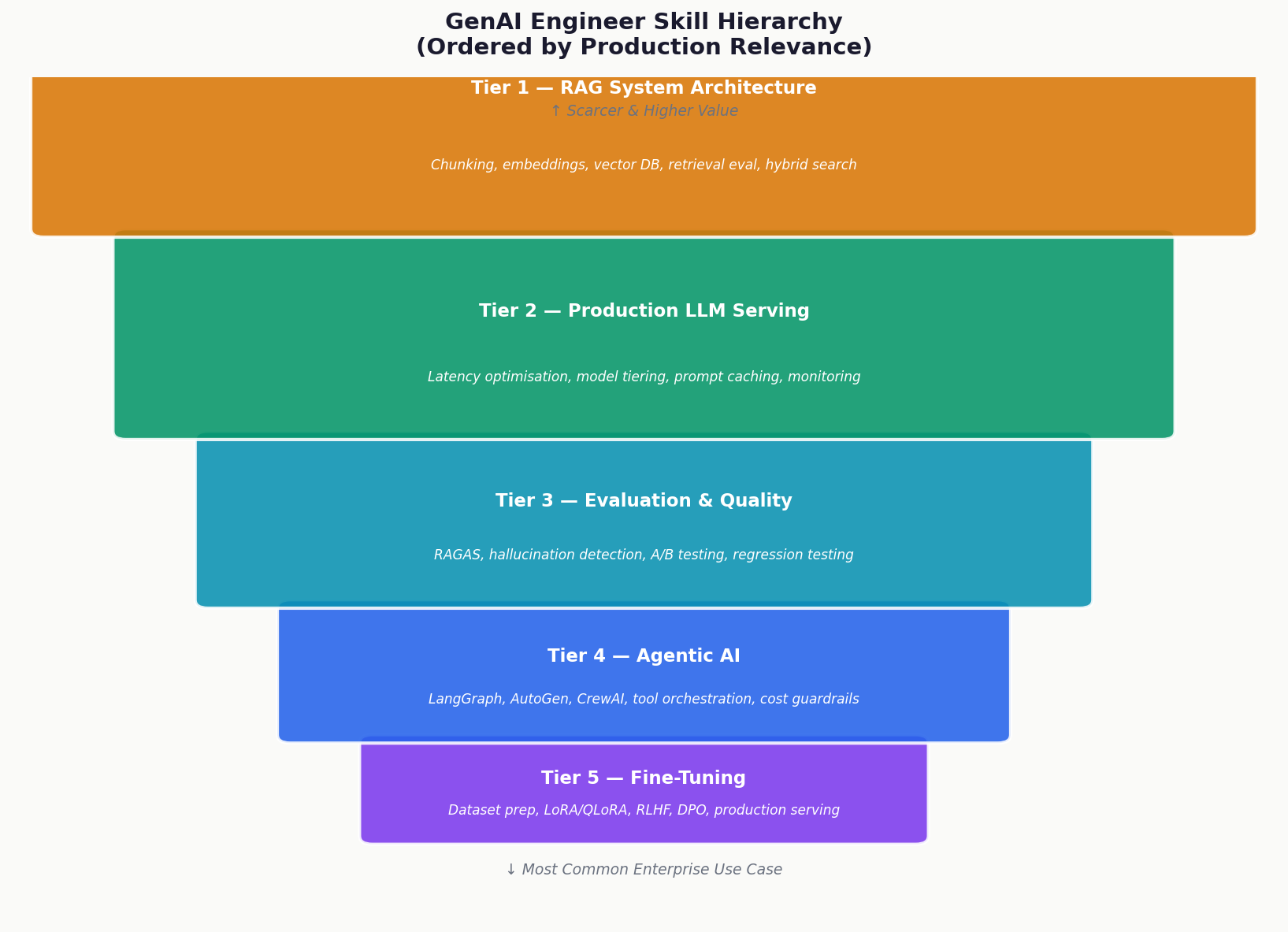
The Skill Hierarchy What Actually Matters
Unlike every other stack in this guide series, GenAI has no industry-standard certification hierarchy. AWS, Google, and Microsoft all offer AI/ML certifications, but none specifically validates production LLM deployment experience. Verification is entirely interview and portfolio dependent.
The skills that matter in order of production relevance:
Tier 1 RAG System Architecture (most common enterprise use case)
Chunking strategy design (fixed-size vs semantic, overlap decisions), embedding model selection (OpenAI ada-002 vs fine-tuned models vs local models), vector database selection and configuration (Pinecone vs Weaviate vs pgvector tradeoffs), retrieval evaluation (precision, recall, MRR measurement), context window management, re-ranking, and hybrid search (dense + sparse retrieval). This is the core skill for most enterprise GenAI programs.
Tier 2 Production LLM Serving
Latency optimisation (streaming responses, KV cache, request batching), cost optimisation (model tiering GPT-4o for complex queries, GPT-4o-mini for simple, local models for high-volume), prompt caching (Anthropic and OpenAI prompt caching APIs), token budget management, rate limit handling, fallback model configuration, and monitoring (latency, cost, quality metrics per model). This separates demo engineers from production engineers.
Tier 3 Evaluation and Quality
Hallucination detection frameworks, RAG evaluation metrics (faithfulness, answer relevancy, context precision RAGAS framework or equivalent), A/B testing for prompt changes, regression testing for model updates, human evaluation workflows for ground truth labelling. Most “GenAI engineers” skip evaluation entirely in demo contexts.
Tier 4 Agentic AI (scarcer, higher value)
Tool definition and selection logic, multi-step agent state management, parallel tool execution, agent error recovery and retry logic, human-in-the-loop integration points, agent cost control (maximum tool call limits, budget guardrails), and observability for agent traces. LangGraph, AutoGen, and CrewAI are the current leading frameworks each with different strengths for different use cases.
Tier 5 Fine-Tuning (specialist, specific use cases)
Dataset preparation (quality over quantity, instruction-following format, deduplication), LoRA/QLoRA parameter-efficient fine-tuning, RLHF and DPO for alignment, evaluation on held-out test sets, overfitting detection, catastrophic forgetting mitigation, and production serving of fine-tuned models. Real fine-tuning for enterprise use cases is done by a small subset of GenAI engineers.
Certifications worth noting (not definitive, but indicative):
- AWS Certified Machine Learning Specialty: Tests ML on AWS including SageMaker. Doesn’t validate LLM production experience specifically but signals cloud ML infrastructure knowledge.
- Google Professional Machine Learning Engineer: Tests ML system design on GCP. More infrastructure-focused than LLM-specific.
- Microsoft Azure AI Engineer Associate: Tests Azure OpenAI and Azure AI Services. More relevant for Azure-stack GenAI programs than the others.
- DeepLearning.AI specialisations (Coursera): Not certifications in the traditional sense but widely held. Signal learning investment, not production delivery.
The honest answer: no certification verifies production GenAI delivery. GitHub portfolios and interview-based production scenario questions are the only reliable verification methods.

The JD That Attracts the Right Candidates
JD 1: Senior LLM / RAG Engineer (4–7 years)
Senior LLM / RAG Engineer Remote from India Engagement: Staff Augmentation | Duration: 12 months, renewable Rate: ₹35–55 LPA CTC equivalent | Billing: $55–82/hr (vendor-facing)
What you’ll own: Design and build production RAG pipelines for our enterprise knowledge management platform. You’ll own chunking strategy, embedding model selection, vector store configuration, retrieval quality measurement, and context assembly. You’ll be measured on retrieval precision/recall, query latency P95, and cost per query not demo quality.
What we require:
- 4–7 years engineering experience, minimum 2 years building production LLM systems (not demos, not internal prototypes user-facing systems with real load)
- RAG pipeline production experience: can describe chunking strategy decisions, embedding model selection rationale, and retrieval quality measurement approach from a live system
- Vector database production experience: Pinecone, Weaviate, pgvector, or Qdrant in production can describe indexing decisions and query optimisation
- Latency and cost optimisation experience: streaming responses, model tiering, prompt caching with specific numbers from production systems
- Evaluation framework experience: RAGAS or equivalent measuring faithfulness, relevancy, and precision in production
- Python primary language, LangChain or LlamaIndex production experience
What disqualifies you:
- GenAI experience limited to personal projects, hackathons, or internal tools with fewer than 100 daily users
- “RAG experience” that cannot describe chunking strategy decisions or retrieval quality metrics from a real system
- No production monitoring experience if you’ve never set up LLM observability (LangSmith, Langfuse, or equivalent), you haven’t run a production LLM system
- Framework knowledge (LangChain, LlamaIndex) without understanding the underlying model APIs and why the framework makes specific choices
Interview process: Portfolio review (GitHub + named production systems, 20 min pre-screen) → Live RAG design scenario (90 min) → Production troubleshooting discussion (45 min)
JD 2: GenAI / AI Platform Architect (8+ years)
GenAI / AI Platform Architect India GCC or BOT Engagement: GCC Build or BOT | Duration: 24+ months CTC: ₹75–115 LPA | Billing: $95–135/hr (vendor-facing)
What you’ll own: End-to-end AI platform architecture for our enterprise GenAI program RAG systems, agentic workflows, LLM serving infrastructure, evaluation pipelines, and MLOps/LLMOps framework. You will own the model selection strategy, cost governance, security architecture (guardrails, prompt injection prevention, data access controls), and the engineering standards for a team of 8–15 AI engineers.
What we require:
- 8+ years in ML/AI engineering, minimum 3 years in production LLM systems
- Can name 3+ production systems they’ve architected company name, user volume, latency SLA, and cost per query
- Multi-model strategy experience when to use GPT-4o vs GPT-4o-mini vs Claude vs local models, and how to implement model routing
- Agentic AI production experience LangGraph, AutoGen, or custom orchestration in a user-facing system
- LLM security architecture prompt injection prevention, output sanitisation, PII detection, data access controls
- Cost governance at scale token budget management, per-user cost allocation, model tiering strategy
- Evaluation and quality framework how to measure and maintain output quality as models and prompts change
Interview process: Architecture presentation on a named production system they’ve built (45 min) → Live multi-agent design scenario (60 min) → Security threat model discussion (30 min) → Reference call with prior CTO or Head of AI
What most enterprise JDs get wrong for GenAI:
They list framework keywords (LangChain, LlamaIndex, AutoGen) as requirements which are selected for tutorial completion, not production delivery. They require “experience with GPT-4, Claude, Gemini” which every developer who has used the OpenAI playground has. They don’t define what “production” means which gives candidates no signal about the depth required.
They don’t ask for specific systems which allow demo portfolios to pass the same filter as production portfolios. And they don’t mention evaluation, monitoring, or cost optimization which tells production-capable engineers that the buyer doesn’t know what production GenAI requires.
How to Verify Experience Not Just Claims
The 3 verification steps before any GenAI interview:
Step 1: GitHub portfolio audit
Ask for the GitHub profile before scheduling. GenAI engineers have public or shareable code. Look for: RAG pipeline implementations with chunking and retrieval logic (not just a LangChain quickstart), evaluation framework implementations (RAGAS configuration, custom evaluation scripts), LLM serving infrastructure code (FastAPI wrappers with streaming, cost tracking, error handling), fine-tuning scripts with dataset preparation and evaluation, and agentic workflow implementations with error recovery logic.
A senior GenAI engineer for a $70/hr role with no public code and no portfolio should be asked directly: “Can you share a private repository or case study that demonstrates production RAG system design?” If they cannot share any evidence of production work, they have not done production work.
Step 2: Named production system verification
Before scheduling a technical interview, ask for the name and URL (if public) of the most significant production LLM system they have built. Ask: the approximate daily active users, the P95 latency of the system, the primary LLM used, and the vector database or retrieval approach. Real production engineers answer these questions specifically and immediately. Demo engineers give vague answers or describe systems with no user load.
Step 3: Production metric specificity
Ask in writing: “What was the hallucination rate or incorrect output rate on the most recent production GenAI system you built, and how did you measure it?” Real production engineers have an answer: they’ve set up evaluation frameworks and know their quality metrics. Engineers who have only built demos either don’t have a measurement framework or give a theoretical answer rather than a measured one.
The 5 interview questions that expose demo engineers:
Q1: RAG Pipeline Architecture “Describe your RAG pipeline architecture for a production system, your chunking strategy decision, embedding model selection rationale, vector store choice, and how you measure retrieval quality.”
Real answer: describes specific decisions chunk size (e.g., 512 tokens with 64-token overlap) and why (document type, query patterns), embedding model choice (e.g., text-embedding-3-small vs ada-002 vs a fine-tuned model) and the evaluation that drove the decision, vector store choice (e.g., pgvector for existing PostgreSQL infrastructure vs Pinecone for scale vs Weaviate for hybrid search) and the tradeoffs, and retrieval quality measurement (e.g., RAGAS faithfulness and answer relevancy scores, specific numbers). They have production numbers “our retrieval precision at k=5 was 0.73 before re-ranking, 0.84 after.”
Tutorial engineer describes RAG architecture correctly at a conceptual level. Cannot describe chunking decisions with rationale, cannot state retrieval quality metrics from a real system.
Q2: Latency and Cost Optimisation “How do you handle latency and cost optimisation for a production LLM system serving 5,000 queries per day? Walk me through your specific techniques and the impact each had.”
Real answer: discusses model tiering (simple queries routed to GPT-4o-mini at 1/15th the cost of GPT-4o, complex queries to GPT-4o), prompt caching for repeated prompt prefixes (40–60% token reduction on cached content), streaming responses for perceived latency reduction, request batching for background processing, and KV cache utilisation for multi-turn conversations. They name specific cost reductions “model tiering reduced our daily API cost from $800 to $220 without measurable quality degradation for 80% of query types.” They have production numbers.
Tutorial engineer says “we can use smaller models for simpler queries.” Cannot describe prompt caching, request batching mechanics, or state specific cost reduction numbers.
Q3: Agentic AI Error Handling “Describe your error handling and retry logic in a production multi-agent system, specifically how you handle tool call failures, agent loops, and cost overruns.”
Real answer: describes the specific error handling framework exponential backoff for transient API failures, circuit breaker pattern for persistent tool failures, maximum tool call limits per agent session (e.g., 15 tool calls as a hard ceiling to prevent runaway agents), fallback tools for critical path failures, human escalation trigger conditions, and cost guardrail implementation (per-session token budget with graceful degradation when exceeded). They describe a real incident where an agent entered an unexpected loop and how their error handling caught it.
Tutorial engineer describes error handling conceptually. Says “we handle errors with try/catch.” Cannot describe agent loop detection, maximum tool call limits, or cost guardrail implementation.
Q4: LLM Security “What are the three most significant security risks in a production enterprise RAG system and how have you specifically mitigated each?”
Real answer: prompt injection (user inputs that attempt to override system instructions mitigated by input sanitisation, structured output enforcement, and separator tokens between system and user context), data exfiltration (RAG retrieval returning sensitive documents to unauthorised users mitigated by document-level access controls in the retrieval layer, not just at the UI), and output sanitisation (model outputs containing PII or sensitive information from retrieved context mitigated by output scanning with PII detection models or regex patterns before serving to users). They describe specific implementation approaches for each.
Tutorial engineer names prompt injection (widely discussed) but cannot describe mitigation implementation or name data exfiltration and output sanitisation as distinct risks.
Q5: Evaluation Framework “How do you measure the quality of a production RAG system over time specifically, how do you detect quality degradation when the underlying documents change or the LLM is updated?”
Real answer: describes the evaluation framework automated evaluation using RAGAS (or equivalent) with a curated golden dataset of question-answer pairs, scheduled regression testing (daily evaluation run against the golden dataset), quality metrics tracked in dashboards (faithfulness, answer relevancy, context precision with alert thresholds), human evaluation pipeline for periodic ground truth refresh, and A/B testing infrastructure for prompt changes and model updates. They describe how they’ve detected and responded to quality degradation in a specific case.
Tutorial engineer describes evaluation as “we review outputs manually.” Cannot describe automated evaluation pipelines, golden datasets, or regression testing approaches.
8 CV red flags:
- “LLM Architect” with no GitHub repositories showing production-quality code
- “RAG experience” that lists only LangChain and OpenAI no vector database, no evaluation framework, no chunking strategy discussion
- “Agentic AI experience” claimed before 2023 modern agentic frameworks (LangGraph, AutoGen, CrewAI) didn’t exist before mid-2023
- “Fine-tuning experience” without mentioning dataset preparation, evaluation methodology, or the specific model fine-tuned
- “Production GenAI system” with no user count, no latency mention, and no company name demo systems are described exactly this way
- Every major LLM listed as “experience” (GPT-4, Claude 3, Gemini Pro, Llama 3, Mistral) real practitioners have depth on 1–2 models, not shallow exposure to all of them
- “GenAI experience from 2019 or 2020” the modern LLM era started with GPT-3 in 2020 and became enterprise-relevant with ChatGPT in late 2022
- Multiple “production AI systems” all at the same company, all described with the same vague language likely one system described multiple ways
How to Source What’s Working, What Isn’t
What’s working in 2026:
GitHub search for production-quality AI repositories.
Search GitHub for repositories with real engineering depth evaluation frameworks, production serving code, fine-tuning pipelines with dataset preparation scripts. Authors of repositories with >100 stars in the GenAI space are identifiable, active practitioners. This surfaces passive candidates who don’t apply to job postings but will respond to specific, technically-informed outreach.
AI company alumni networks.
Engineers who have worked at India’s AI-first product companies Sarvam AI, Krutrim, Observe.AI, Uniphore, Mad Street Den, Yellow.ai or at US tech company AI GCCs in Bangalore (Google DeepMind India, Microsoft Research India, Meta AI India) have production AI experience. Alumni networks from these organizations are the highest-quality sourcing channel for senior GenAI engineers.
3 ready-to-use LinkedIn boolean search strings:
- String 1 (Senior RAG Engineer): “RAG” AND (“LangChain” OR “LlamaIndex”) AND (“production” OR “deployed”) AND (“Senior” OR “Lead”) AND “Bangalore”
- String 2 (Agentic AI): (“LangGraph” OR “AutoGen” OR “CrewAI”) AND (“production” OR “enterprise”) AND “India”
- String 3 (AI Platform / MLOps): (“LLMOps” OR “MLOps“) AND (“LLM” OR “GenAI”) AND (“Architect” OR “Lead”) AND “Bangalore”
AI conference community.
NeurIPS, ICLR, and ACL have India-based attendees and contributors who represent the research end of the AI community. For production engineering (as opposed to research), the relevant communities are AI engineering conferences AI Engineer Summit, MLOps World, and India-based events like the Bangalore AI/ML meetup community. Speakers and active community members at these events are verifiably senior practitioners.
Supersourcing pre-vetted bench. For Senior LLM/RAG Engineers with verified production deployments, Supersourcing’s median fill time is 26 calendar days with portfolio and production system verification completed before the first CV is submitted.
What isn’t working:
Any job posting that lists GenAI keywords without production requirement.
“Experience with LangChain, LlamaIndex, OpenAI API, RAG, vector databases” returns the full India GenAI pool including every tutorial completion. Without “production deployment with named system and user volume” as an explicit requirement, you are screening from the wrong pool.
Technical interviews without GitHub portfolio pre-screening.
Scheduling a 90-minute technical interview for a GenAI role without first reviewing the candidate’s GitHub or portfolio is the most expensive GenAI hiring mistake after not asking production questions. An impressive verbal description of a RAG architecture takes 10 minutes to coach. A genuine production codebase takes 2 years to build.
Vendor frameworks as qualifications.
“Must have LangChain experience” selected for tutorial completion. LangChain has a 30-minute quickstart guide that any developer can complete in an afternoon. The framework is the least important qualification for a production GenAI engineer. The engineering depth beneath the framework is what matters.
Assuming ML engineers automatically transfer to GenAI.
India has a large, genuine ML engineering community computer vision, recommendation systems, NLP for classification and NER. These engineers have real ML production experience. Production GenAI / LLM engineering has different challenges: prompt engineering, RAG architecture, model API economics, hallucination management that ML engineers need to learn specifically. ML experience is a strong foundation. It is not an automatic GenAI production experience.
Supersourcing Index: Pipeline-to-offer conversion rate for Senior GenAI roles in the Supersourcing GCC Benchmark 2026: 11%. Of every 100 CVs submitted for senior GenAI/LLM roles, 11 result in hires that pass the production verification bar. The portfolio pre-screening step alone reduces the interview load by 60%. 60 of those 100 CVs are eliminated by the GitHub and named production system check before any interview is scheduled.

The Contract Stack for GenAI Engagements
Clause 1: Individual Resource Approval with Production System Verification
Every engineer approved must be listed with: name, named production system(s) they’ve built, approximate user volume, and primary LLM stack used. This is unusual for an MSA approval clause but GenAI is the only stack in this series where “production experience” is the primary qualification and it is unverifiable through certification. Making it a contractual specification means a vendor substituting a demo engineer for a production engineer is a verifiable breach.
Clause 2: IP Assignment Models, Pipelines, and Prompt Templates
GenAI IP is complex and requires explicit coverage. The Deed must cover: custom fine-tuned model weights and adapter files (LoRA weights, for example), RAG pipeline architecture and configuration (chunking strategies, evaluation frameworks), prompt templates and system prompts (these are valuable IP in regulated industries), evaluation datasets and golden test sets, and vector database schemas and embedding configurations. Standard software IP clauses do not clearly cover model weights, prompt templates, or evaluation datasets.
Clause 3: Data Use Restriction
GenAI programs often involve proprietary data, customer data, financial data, medical records being used in RAG systems or for fine-tuning. The MSA must explicitly restrict: use of client data for any purpose outside the engagement, use of client data to improve vendor’s own models or benchmarks, transmission of client data to third-party LLM APIs without explicit approval (some LLM providers use API inputs for training by default this must be explicitly disabled and confirmed), and retention of client data after engagement end.
Clause 4: Model Update Notification
LLM providers update models regularly GPT-4o updates, Claude model updates, Gemini updates with changes that can affect output quality, cost, and latency. The vendor engineering team should not switch model versions without client notification. Require a 7-day notification before any model version change in production with regression testing evidence confirming quality maintenance.
Clause 5: Hallucination and Quality SLA
Define the acceptable quality threshold in the contract “the system will produce factually incorrect responses in no more than X% of test cases as measured by the evaluation framework defined in Appendix A.” This is unusual for software contracts but entirely appropriate for AI systems where output quality is probabilistic. The evaluation framework and acceptable threshold must be agreed before the contract is signed, not discovered at user acceptance testing.
Running a GenAI Team at Scale
Prompt engineering governance.
Prompts are code. They should be version-controlled, reviewed, and tested before production deployment. A team that makes ad-hoc prompt changes in production without version control will produce inconsistent, unpredictable behaviour that is impossible to debug. Establish: prompt version control in Git, A/B testing infrastructure for prompt changes, regression testing requirement before production prompt updates.
Evaluation pipeline as infrastructure.
The evaluation pipeline, your golden dataset, your automated quality metrics, your regression tests is as important as the product code. It requires engineering maintenance, dataset refresh, and monitoring. Treat it as a first-class engineering deliverable, not an afterthought. A GenAI program without an evaluation pipeline cannot measure quality, cannot detect degradation, and cannot safely update models or prompts.
Cost governance.
LLM API costs at scale are material. Establish: per-query cost tracking, per-user or per-feature cost allocation, alert thresholds for cost spikes (a prompt injection attack can generate enormous token volumes), and model tiering review cadence. The offshore team must operate within a defined cost budget per sprint, not just a time budget.
Model versioning and rollback.
When an LLM provider updates a model, output quality can change in ways that your evaluation framework catches or doesn’t. Establish a model version pinning strategy: specify the exact model version in production (e.g., gpt-4o-2024-08-06, not just gpt-4o), test new model versions against your golden dataset before upgrading, and maintain the ability to roll back to the previous model version quickly.
Early warning signals:
- Declining evaluation scores on the golden dataset without model or prompt changes
- Increasing user complaint rate about response quality
- Sprint deliverables that are demos rather than production-hardened features
- Cost per query trending upward without corresponding quality improvement
- GitHub commit frequency dropping engineers may be blocked or disengaged
Retention levers:
Model diversity and cutting edge work. GenAI engineers stay on programs where they’re working with the latest models and techniques. A dedicated team using only GPT-4o and basic RAG in month 12 will lose engineers who want to work with frontier models, agentic architectures, and multimodal systems. Give them roadmap exposure to emerging techniques.
Research and publication support. India’s AI community has strong academic roots. GenAI engineers who can write and publish about their production learnings, technical blog posts, conference talks, and internal research stay engaged longer. Support this proactively.
Ownership of novel systems. The highest-retention position for a GenAI engineer is “I built this production system that serves X users and it does something genuinely new.” Create ownership opportunities, not just implementation roles.
When Things Go Wrong
Pattern 1: The Demo-to-Production Gap
Described in Section 1. The financial services company that spent $1.4M on demos before a production-capable leader was brought in. This pattern of demo engineers building impressive prototypes that are not production-deployable is the most common GenAI program failure in enterprise settings.
The fix: the production system verification in Section 8 (named system, user volume, latency SLA) eliminates demo-only engineers before the first interview. The portfolio pre-screen (GitHub for production-quality code) eliminates 60% of the wrong pool before any interview time is spent.
Pattern 2: The Hallucination Liability
A US insurance company built a GenAI customer service system using an offshore India team. The system answered policy coverage questions. The evaluation framework measured response time and user satisfaction. It did not measure factual accuracy.
Month seven: the system told a customer that their homeowner’s policy covered flood damage. It did not. The customer filed a claim. The claim was denied. The customer sued. Legal costs and settlement: $340K. The hallucination rate question in Section 3 (criterion 3) and the quality SLA in the contract would have required factual accuracy measurement from the start.
Pattern 3: The Prompt Injection Incident
A retail company’s GenAI product recommendation chatbot was targeted by a coordinated prompt injection attack. Users submitted inputs designed to override the system prompt and extract the product pricing database. The offshore engineering team had not implemented prompt injection prevention they had not been asked to.
24 hours of compromised product pricing data. Incident response cost: $85K. The security threat model discussion question (Q4 in Section 8) and the data use restriction clause in Section 10 would have established prompt injection prevention as a baseline requirement from the program start.
When India Is the Wrong Call
Scenario 1: Real-time AI with sub-100ms latency requirements.
Some GenAI use cases require sub-100ms response times, real-time speech AI, trading signal generation, and live video analysis. These use cases require engineers who are deeply familiar with low-latency serving infrastructure, model quantisation for edge deployment, and hardware acceleration.
This profile exists in India but is concentrated at a small number of product companies (Sarvam AI, Observe.AI) and US tech GCCs. For sub-100ms GenAI, the India pool is thin and the sourcing timeline is long. Consider a hybrid model with US-based latency specialists and India-based engineers for the higher-latency components.
Scenario 2: Regulated AI requiring interpretability for regulatory examination.
Financial services, healthcare, and government AI applications increasingly require model interpretability, the ability to explain why a specific output was produced to a regulator or auditor. Interpretability for LLMs (attention visualisation, LIME, SHAP for transformer models) is a research-adjacent skill that has a thin production engineering pool globally, including India.
For AI systems where regulatory examination of individual decisions is required, consider whether LLMs are the right approach at all; traditional ML with interpretability features may be more defensible.
Scenario 3: Frontier model research and development.
If your program requires fundamental research, new model architectures, novel training approaches, RLHF from scratch India has strong AI research talent but it is concentrated in a small number of academic and corporate research labs. For production AI engineering (building systems with existing models), India’s pool is deep.
For frontier research, the relevant talent is at IITs, IISc, and the research arms of Google DeepMind India and Microsoft Research India not accessible through standard staffing channels.
The Supersourcing Vendor Scorecard GenAI Edition
Score your vendor before you sign. Maximum 100 points. Minimum threshold: 65.
Category 1: Production Verification (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Can name production systems for all claimed senior engineers within 24 hours | Cannot | Some | All, with user volume and LLM stack |
| GitHub or portfolio evidence requested and evaluated | Not requested | Requested, not evaluated | Evaluated with production quality criteria |
| Demo vs production distinction acknowledged proactively | Conflates them | Distinguishes when asked | Proactively separates with verification |
Category 2: Technical Vetting (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Production RAG scenario in technical assessment | No RAG questions | Conceptual RAG questions | Live production scenario with metrics |
| Evaluation framework knowledge tested | Not tested | Mentioned | RAGAS or equivalent, specific metrics |
| Security threat model in technical screen | Not tested | Mentioned generally | Prompt injection + data controls specific |
Category 3: Contract Readiness (0–20 pts)
| Criterion | 0 | 10 | 20 |
| IP Assignment covering model weights, prompts, and evaluation datasets | Not available | Available on request | Standard, items named |
| Data use restriction (no training on client data) | Not present | Present, vague | Present, specific API data retention clauses |
| Quality SLA with evaluation framework defined | Not present | Mentioned as possible | Contractual threshold with measurement method |
Category 4: GenAI Delivery Track Record (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Named enterprise GenAI production clients | None | Logo only | Named contact + system + user volume |
| Evaluation framework used on prior program verifiable | None | Claimed | Verified with quality metrics |
| Attrition on GenAI programs | Unknown / >25% | 18–25% | <18% |
Category 5: Commercial Structure (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Rate card by production tier (demo vs production experience) | Single rate | Senior/junior distinction | Production verification tier |
| Substitution clause with production equivalence | Not present | Available | Standard, production system equivalence |
| Model update notification requirement | Not present | Best effort | 7-day contractual notification |
Score interpretation: 85–100 shortlist; 65–84 proceed with conditions; 45–64 high risk; below 45 walk.
15 Questions Buyers Actually Ask
Q: Is there a GenAI certification I should require?
No single certification validates production LLM deployment as of May 2026. AWS Certified Machine Learning Specialty, Google Professional ML Engineer, and Microsoft Azure AI Engineer Associate exist and signal cloud AI infrastructure knowledge, but none specifically tests production RAG systems, agentic AI delivery, or LLM cost optimisation. Verification for GenAI is entirely portfolio and interview dependent; the production system named, the GitHub portfolio, and the production scenario questions in Section 8 are the only reliable verification method.
Q: What’s the difference between an ML engineer and a GenAI engineer?
ML engineers typically have backgrounds in supervised and unsupervised learning classification, regression, recommendation systems, computer vision, and traditional NLP. They work with training pipelines, feature engineering, and model evaluation frameworks built around structured datasets. GenAI engineers work with large pre-trained language models via API or fine-tuning RAG pipelines, prompt engineering, agentic systems, and LLM serving infrastructure. The skills overlap significantly at the infrastructure level. The application layer is different. An ML engineer is a strong foundation for GenAI work but requires specific LLM production experience to be immediately productive on a GenAI program.
Q: LangChain vs LlamaIndex does the framework choice matter for hiring?
Less than most buyers assume. Both are Python-based frameworks for building LLM applications. LangChain covers agents, chains, memory, and retrieval. LlamaIndex focuses specifically on data ingestion and retrieval (RAG). An engineer who deeply understands one can learn the other in days. What matters is whether the engineer understands the production engineering principles beneath the framework chunking strategy, retrieval quality, latency optimisation. A senior engineer who can explain why they chose one framework over another for a specific use case is more valuable than one who just knows both superficially.
Q: How do I manage LLM API costs for a large-scale production system?
Model tiering is the primary lever routing simple queries to smaller, cheaper models (GPT-4o-mini, Claude Haiku) and complex queries to larger models (GPT-4o, Claude Sonnet). Prompt caching (available on Anthropic and OpenAI APIs) reduces token costs for repeated prompt prefixes by 60–90%. Request batching for non-real-time workloads reduces per-token cost on some providers. Caching deterministic outputs if the same query returns the same result reliably, cache it at the application layer rather than calling the LLM. These techniques combined can reduce LLM API costs by 70–85% compared to naive single-model, non-cached implementations.
Q: What is RAG and why does it matter?
RAG (Retrieval-Augmented Generation) is the technique of combining a language model with a retrieval system, typically a vector database, to answer questions using specific, up-to-date documents rather than only the model’s training knowledge. Instead of asking GPT-4 to answer a question from memory, RAG retrieves relevant documents from your knowledge base and provides them as context to the model. This addresses two core limitations of LLMs: knowledge cutoffs (the model doesn’t know about events after its training) and hallucination on specific factual questions. Most enterprise GenAI programs involve some form of RAG knowledge bases, document Q&A, customer support with product knowledge.
Q: What is agentic AI and when do I need it?
Agentic AI refers to LLM systems that can take sequences of actions calling tools, browsing the web, writing and executing code, interacting with APIs to complete multi-step tasks autonomously or semi-autonomously. You need agentic AI when a single LLM query and retrieval step is insufficient for example, researching a topic across multiple sources, filling out a form by calling multiple APIs, or debugging code by running tests and iterating. Agentic AI is significantly more complex to build in production than RAG tool reliability, agent loops, cost runaway, and error recovery are all production challenges that RAG doesn’t have. Only hire for agentic AI if your use case genuinely requires multi-step autonomous action.
Q: How do I handle hallucinations in a production GenAI system?
Multiple layers: grounding (RAG ensures answers are based on retrieved documents, not model knowledge), citation requirements (the model must cite the document it’s drawing from, enabling verification), confidence scoring (models can indicate uncertainty; route low-confidence responses to human review), output validation (automated fact-checking against the source documents for critical facts), human-in-the-loop for high-stakes decisions (any AI output affecting financial decisions, medical recommendations, or legal matters should have a human review step), and continuous evaluation (measure hallucination rate using an automated evaluation framework against a golden dataset of known correct answers). There is no single fix for production hallucination management that requires all of these layers.
Q: What’s the realistic timeline to build a 10-engineer GenAI team in India?
For a mixed team senior LLM engineers, a GenAI architect, and AI platform engineers, all with verified production experience expect 40–55 days from JD sign-off to full team onboarded. The production verification step (portfolio review + named system verification) adds 5–7 days to the standard sourcing timeline but eliminates the 60% of candidates who would fail the technical bar anyway. For a team that includes agentic AI specialists or fine-tuning engineers specifically, add 15–20 days for the thinner pools.
Q: Should I use open-source models or commercial APIs for my production GenAI program?
Both have roles. Commercial APIs (OpenAI, Anthropic, Google) are fastest to production, have the strongest general capabilities, and have clear pricing. Appropriate for most enterprise use cases where data privacy requirements allow cloud API usage. Open-source models (Llama 3, Mistral, Gwen) are appropriate when: data privacy requirements prevent sending data to third-party APIs, cost at scale makes commercial APIs uneconomical (high query volume), or specific fine-tuning is required. Running open-source models at production scale requires significant infrastructure GPU provisioning, model serving infrastructure, monitoring. This is a distinct engineering skill set from commercial API integration.
Q: How do I evaluate whether a vendor’s GenAI team can handle regulated industry requirements?
Three specific questions: Have they implemented prompt injection prevention in a production system? (yes/no + describe) Have they built systems where AI outputs were subject to regulatory examination or audit? (yes/no + describe the audit trail architecture) Have they implemented data access controls at the retrieval layer in a RAG system? (yes/no + describe). Regulated industry GenAI financial services, healthcare, insurance requires all three. Engineers who have only built GenAI for consumer or internal enterprise tools often haven’t encountered these requirements.
Q: Is Supersourcing the right partner for a 3-engineer GenAI proof-of-concept?
Not our ideal engagement. Our model is built for 8+ engineer programs with enterprise production requirements. For a 3-engineer proof-of-concept, an AI-specialist boutique or a direct hire of senior freelance engineers with verified production portfolios is a better fit. We’d rather tell you that than win a deal where you need exploration and we deliver enterprise governance overhead.
Closing
GenAI hiring from India works for production programs. The production-capable engineers exist in approximately 1,800 GenAI architects who have shipped real systems to real users. They are in Bangalore, primarily. They have GitHub portfolios. They can name their production systems. They have latency SLAs and cost-per-query numbers from memory because they’ve managed those numbers in production.
Finding them requires one filter that most enterprise buyers don’t apply: production system verification before the first interview. Named system. User volume. Latency SLA. GitHub portfolio. These four data points collectible in 15 minutes of pre-screening eliminate the 89% of GenAI CVs that represent tutorial experience presented as production capability.
The 11% that remain are the engineers who have built what you need.
Book a 30-minute GenAI Talent Discovery Call → No deck. Just the numbers and the bench.
