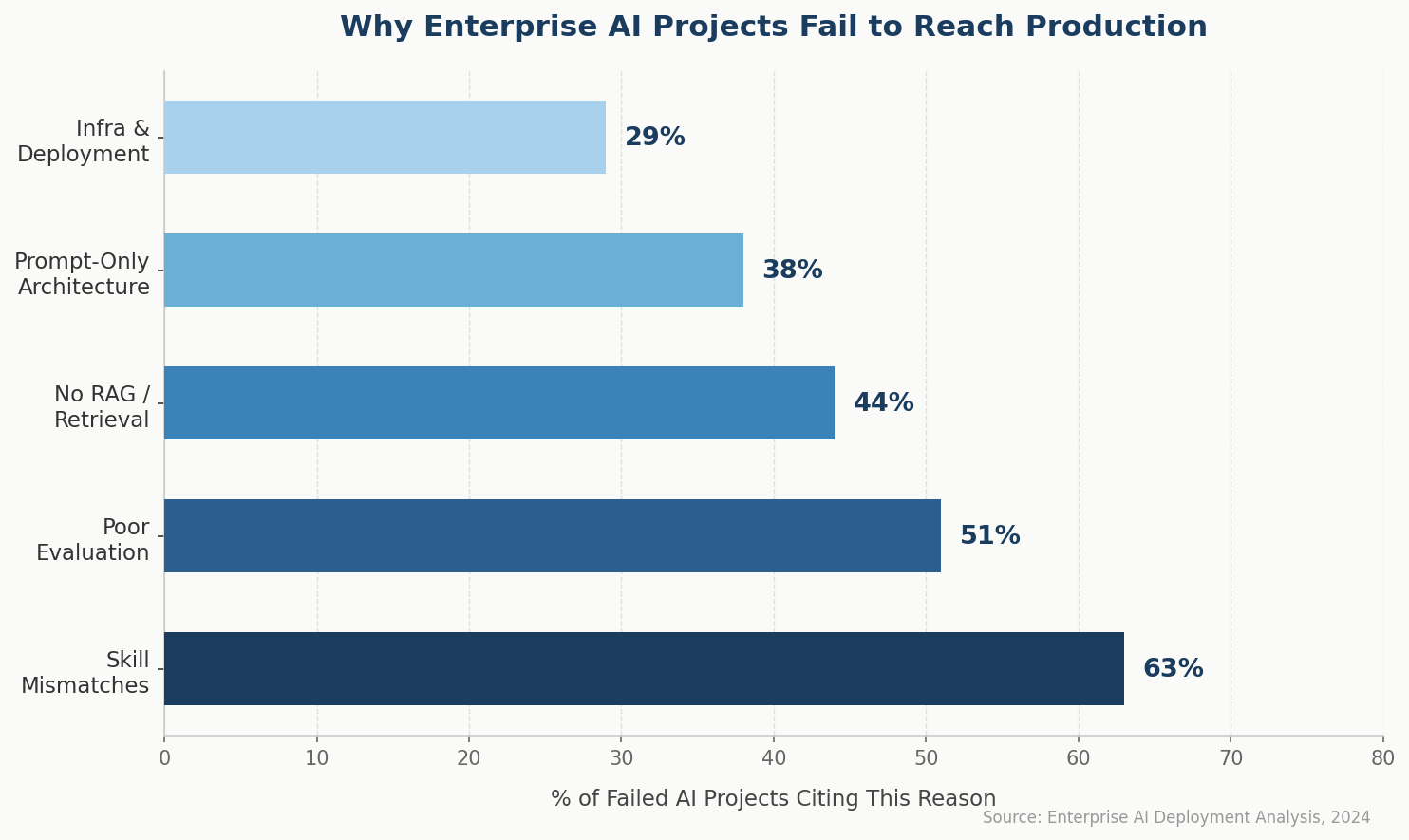
Sixty-three percent of enterprise AI projects in 2024 failed to reach production not because of bad ideas, but because of skill mismatches on the engineering team. The dominant mistake: hiring for prompt engineering when the job actually requires retrieval-augmented generation, fine-tuning, evaluation pipelines, and deployment architecture. As teams rush to hire LLM engineer India talent in 2026, the gap between what companies think they need and what production AI actually demands has never been wider.
Most enterprise AI initiatives don’t fail because of weak ideas, they fail because the engineering team is built for demos, not production. The gap shows up when systems need to move beyond prompts into data pipelines, evaluation frameworks, and scalable deployment.
Hire LLM engineer India is where many companies misstep in 2026. Roles are often scoped around prompt engineering, while real-world implementations demand retrieval-augmented generation (RAG), fine-tuning strategies, model evaluation, and production-grade architecture.
The stakes are rising fast. According to Statista generative AI market forecast, the global generative AI market is projected to exceed $60 billion by 2026, reflecting rapid enterprise adoption and increasing complexity of LLM systems.
The takeaway is clear: hiring for LLM success isn’t about prompts, it’s about building the full stack of capabilities required to take AI from prototype to production.
TL;DR: What This Blog Covers
Prompt engineering is no longer a hiring signal. In 2026, production-grade LLM systems demand engineers who can build RAG pipelines, run fine-tuning jobs, and design evaluation frameworks. Most companies are hiring one level below what they actually need.
This blog breaks down the exact technical skill stack that separates a demo-capable engineer from a production-ready one covering retrieval architecture, model customization, evaluation design, and deployment. It includes a hiring framework, real cost benchmarks for the Indian market, and the three mistakes that consistently derail LLM hiring.
If you are building an AI team in 2026 and want to get the hire right the first time, the sections below give you a repeatable process to evaluate candidates before you commit.
What Is an LLM Engineer?
An LLM engineer is a specialized software professional who designs, builds, and maintains systems that integrate large language models into production applications spanning data pipelines, embedding models, model fine-tuning workflows, inference infrastructure, and evaluation frameworks. This role is distinct from a data scientist, an ML researcher, and especially from a prompt engineer.
Why “Prompt Engineer” Is No Longer a Hiring Strategy
The job market shifted fast. In 2023, prompt engineering was genuinely scarce. By 2026, table stakes are the equivalent of knowing how to write a SQL query. Companies that are still filtering for prompt skills as a primary signal are, in effect, hiring for the 2022 version of AI work.
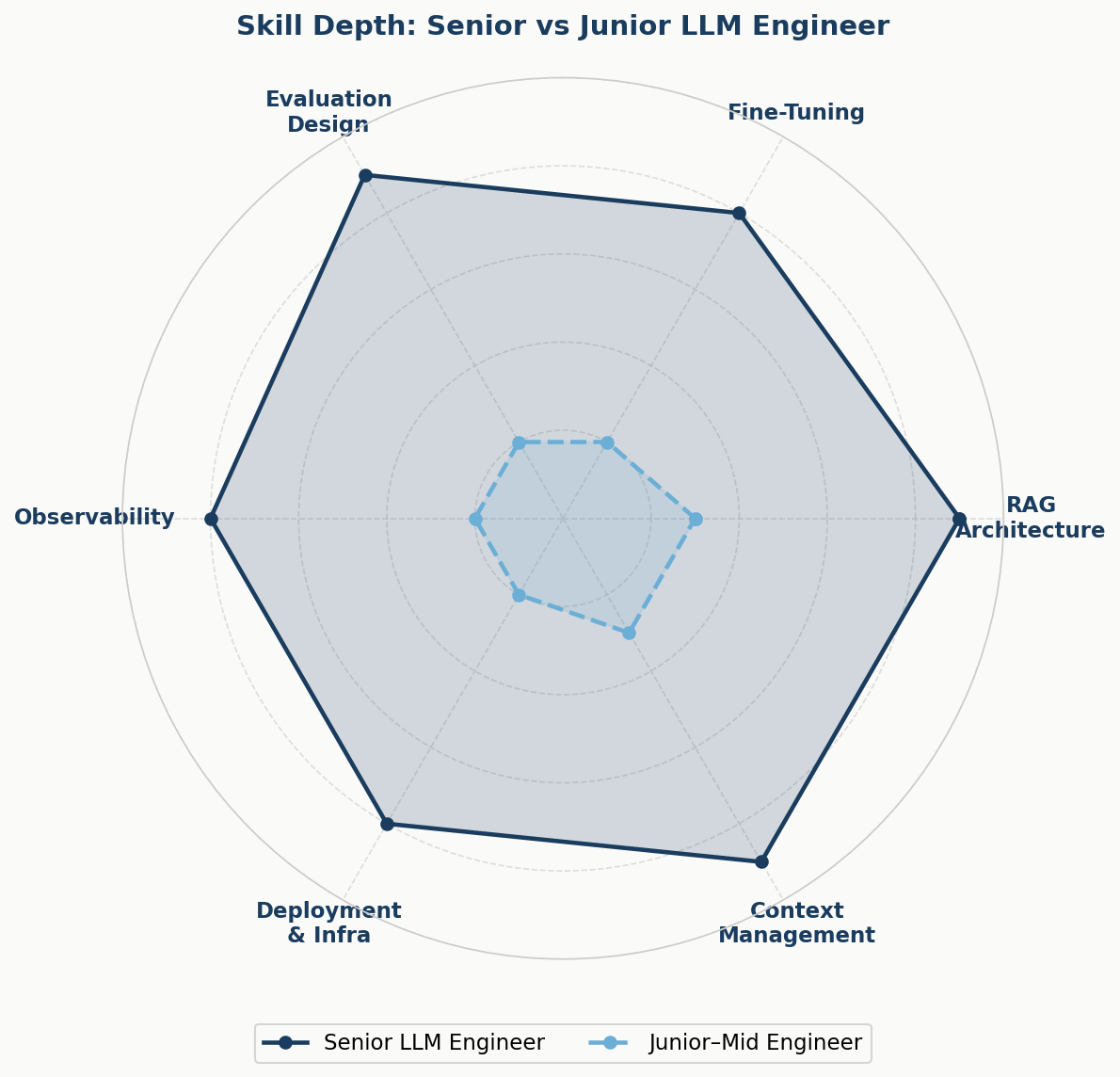
Real LLM engineer skills 2026 span four distinct technical layers: data and retrieval architecture, model customization, evaluation systems, and production deployment. Most mid-level candidates can write a decent prompt. Far fewer can design a RAG pipeline that maintains factual accuracy at scale, instrument LLM observability dashboards, or manage inference costs under SLA constraints. The skill delta between a prompt-heavy generalist and a true LLM engineer is 3–4x in project complexity capacity.
This is the actual risk when you hire LLM engineer India talent from a shallow pool: demos work, production breaks.
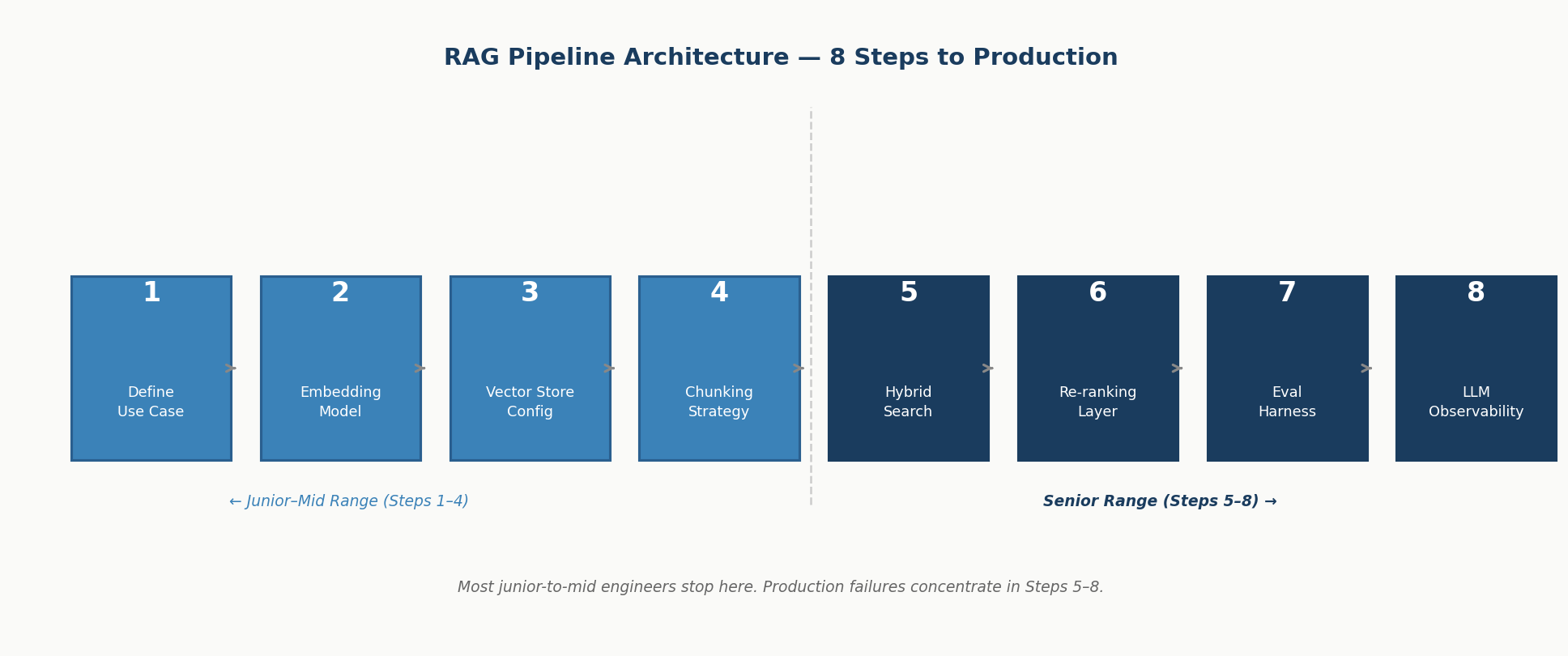
The Real Technical Skill Stack in 2026
Retrieval-Augmented Generation Architecture
Hire RAG engineer capability is now one of the most in-demand specializations within the broader LLM space. RAG is not a single feature; it is a full pipeline that includes document ingestion, chunking strategy, vector database integration (Pinecone, Weaviate, pgvector), embedding model selection, hybrid search design, and re-ranking logic. A strong RAG engineer will make architecture decisions that affect latency, retrieval accuracy, and total cost simultaneously.
A senior engineer building a RAG pipeline from scratch will typically go through these steps:
- Define the retrieval use case (open-domain Q&A, closed-domain enterprise search, multi-document synthesis)
- Choose the embedding model based on domain, language, and latency requirements
- Select and configure the vector store with appropriate indexing strategy (HNSW, IVF, or flat)
- Design chunking and overlap parameters based on document type
- Implement hybrid search (dense + sparse retrieval) for precision-recall balance
- Add a re-ranking layer using a cross-encoder model
- Build evaluation harness to measure retrieval hit rate and end-to-end answer quality
- Instrument the full pipeline with LLM observability tooling (LangSmith, Phoenix, or custom)
Most junior-to-mid candidates can execute steps 1–4. The drop-off happens at steps 5–8, and that is exactly where production systems fail.
Fine-Tuning and Model Customization
LLM fine-tuning expertise remains one of the hardest skills to find. Full fine-tuning is increasingly rare; the computer cost is prohibitive for most teams. What matters now is parameter-efficient fine-tuning: LoRA, QLoRA, and adapter-based methods that achieve domain adaptation at a fraction of the cost.
A qualified large language model developer India candidate should be able to: select the appropriate base model, prepare instruction-tuning datasets, apply RLHF and alignment techniques (or preference optimization alternatives like DPO), manage training runs on cloud GPU instances, and validate the fine-tuned model against the base model using task-specific benchmarks. Model quantization reducing a model from FP16 to INT8 or INT4 is a separate but related skill that affects inference latency optimization and deployment cost directly.
Evaluation and Testing Frameworks
This is the most underrated technical skill on every hiring checklist. LLM systems do not have deterministic outputs, which means traditional unit testing covers perhaps 30–40% of what can go wrong. A strong AI model evaluation engineer designs evaluation pipelines that assess faithfulness, relevance, coherence, and task-specific accuracy often using LLM-as-judge frameworks, human feedback loops, and adversarial prompt testing.
Teams that skip robust evaluation discover problems in production at a cost that is 5–10x what early detection would have required. Semantic search quality, hallucination rates, and refusal behavior all need quantified baselines before any model changes ships.
Context Window and Prompt Pipeline Architecture
Context window management is an architectural decision, not a prompt-writing task. In 2026, with models supporting 128K–1M token contexts, engineers must reason about what to include in context, in what order, at what compression level, and with what caching strategy to manage cost. Prompt pipeline architecture the systematic design of multi-step prompting chains with fallback logic, structured output enforcement, and latency budgeting is a distinct engineering discipline. It involves code, not just natural language.
Real-World Application: Where These Skills Resolve Business Problems
A fintech company building an internal document intelligence system initially hired two prompt-heavy engineers. After six months, their RAG retrieval accuracy plateaued at 61% and inference costs were running at ₹8–12 lakhs per month. After bringing on a senior LLM engineer with vector database and re-ranking expertise, retrieval accuracy reached 87% within 10 weeks and LLM deployment cost optimization work brought monthly inference spend down by 44%.
A healthcare SaaS company in Bengaluru needed a clinical note summarization system with citation accuracy. Their first version, built without a formal evaluation framework, produced medically unreliable outputs that failed internal review. Rebuilding with a proper LLM evaluation framework including faithfulness scoring against source documents reduced hallucination rates from 18% to under 3% before the product reached compliance review.
How to Evaluate an LLM Engineer Before Hiring
Companies that hire LLM engineer India talent without a structured technical assessment process end up with engineers who are strong in theory but weak in production implementation. Here is a practical decision framework for assessing candidates:
| Evaluation Dimension | Junior Signal | Senior Signal |
| RAG Architecture | Can set up basic vector search | Designs hybrid retrieval with re-ranking and eval harness |
| Fine-Tuning | Aware of LoRA/QLoRA concepts | Has run training jobs, validated outputs, managed GPU cost |
| Evaluation | Writes prompt-level tests | Builds automated eval pipelines with domain-specific metrics |
| Observability | Uses basic logging | Instruments full trace-level LLM observability with cost attribution |
| Deployment | Can deploy to a single cloud endpoint | Manages inference latency, autoscaling, and quantization tradeoffs |
A take-home task involving a real RAG pipeline, even a simplified one, reveals more in two hours than five rounds of behavioral interviews.
What Most Teams Get Wrong When They Hire LLM Engineer India Talent
The most common failure mode is treating the LLM engineer role as interchangeable with a senior Python developer. It is not. A strong backend engineer can learn prompt chaining in a week. Learning to architect a retrieval system that performs at 90%+ accuracy across diverse document types, instrument it properly, and tune it without blowing the inference budget that takes 12–18 months of focused project experience, minimum.
The second mistake is filtering on framework familiarity. Knowing LangChain or LlamaIndex is useful, but these frameworks change fast. What does not change is foundational understanding of embedding models, attention mechanisms, context window management, and evaluation methodology. Hire for depth in fundamentals; frameworks are learnable on the job.
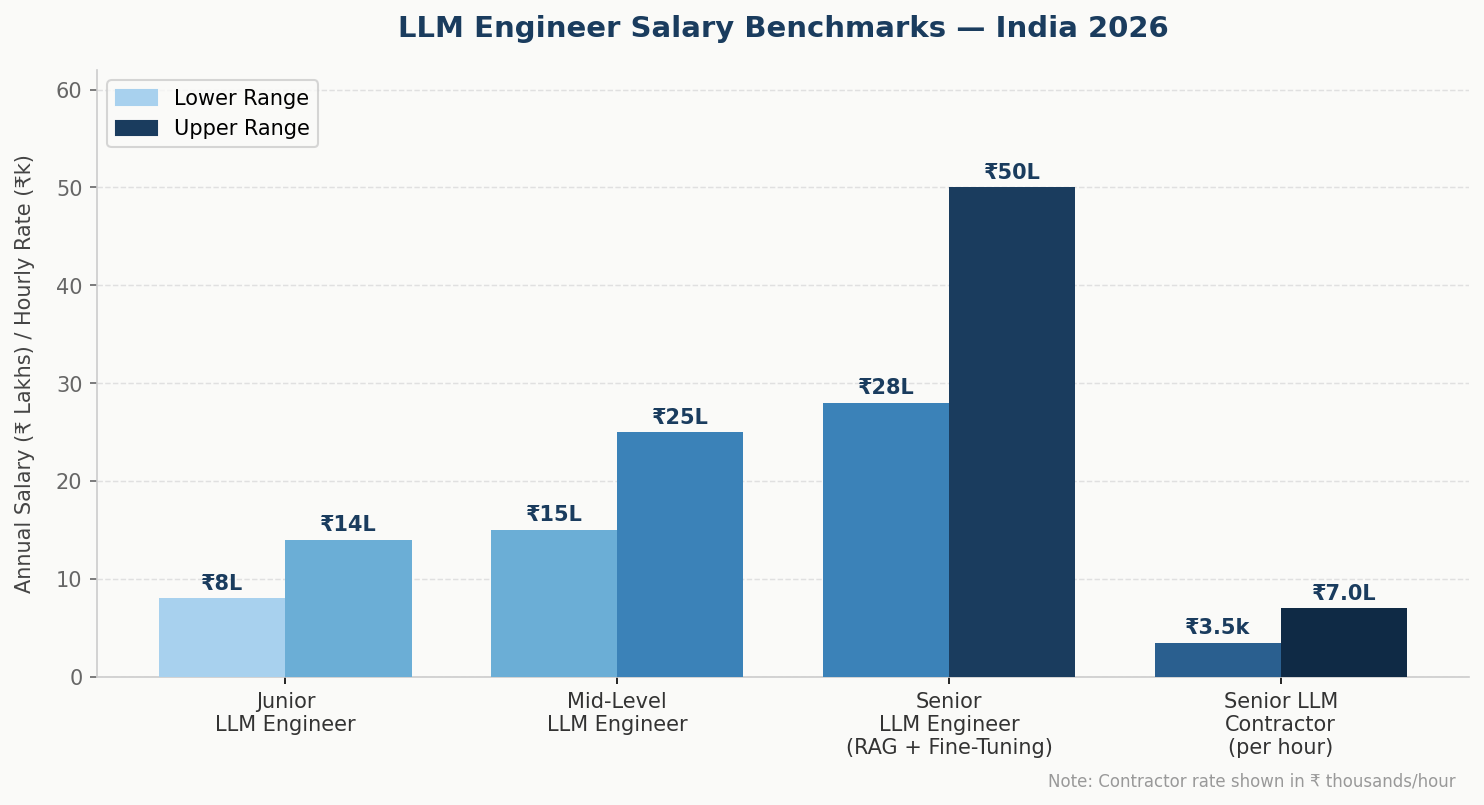
The third mistake is underpaying because India’s AI talent market “looks affordable.” Senior LLM engineers in India with genuine production experience in RAG and fine-tuning command ₹25–45 lakhs per annum and above. Teams that anchor below ₹18–20 lakhs for this profile are consistently getting the wrong tier of candidate.
Frequently Asked Questions
What does an LLM engineer actually do beyond prompt engineering?
An LLM engineer builds the full system around a language model, retrieval pipelines, embedding infrastructure, evaluation frameworks, fine-tuning workflows, and deployment architecture. Prompt engineering is one input to that system, not the system itself. In a production context, the engineering work around the model typically represents 80% of the total effort.
What is the difference between a prompt engineer and an LLM engineer?
A prompt engineer optimizes input text to get better outputs from an existing model. An LLM engineer builds, adapts, evaluates, and deploys the systems those models run inside. The skill overlap is small. Most LLM engineers can write good prompts; almost no prompt engineers can architect a RAG pipeline or run a fine-tuning job.
What skills should an LLM engineer have in 2026?
Core skills include: RAG pipeline design and vector database integration, parameter-efficient fine-tuning (LoRA/QLoRA), LLM evaluation framework design, context window and prompt pipeline architecture, inference optimization and quantization, and LLM observability instrumentation. Python proficiency and cloud deployment experience (AWS, GCP, or Azure) are baseline requirements.
How much does it cost to hire an LLM engineer in India?
Expect ₹15–25 lakhs per annum for mid-level engineers with 2–3 years of LLM-specific experience and ₹28–50 lakhs for senior engineers with production RAG, fine-tuning, and evaluation expertise. Contractors and fractional hires for project-based work are typically priced at ₹3,500–7,000 per hour depending on specialization.
How do you evaluate an LLM engineer’s technical depth before hiring?
Use a structured take-home assessment: ask candidates to build a minimal RAG pipeline over a provided document corpus, instrument it with basic evaluation metrics, and explain the architecture tradeoffs they made. This tests retrieval design, evaluation thinking, and systems reasoning simultaneously the three areas where shallow candidates most consistently fall short.
Is it cost-effective to hire LLM talent in India for enterprise AI projects?
Yes, with the right expectations. India’s LLM talent market is deep at the mid-level but the senior pool is narrow and competitive. Cost advantages are real (typically 40–55% versus equivalent US or UK profiles), but only when hiring against a precise skills rubric. Generic “AI developer” hiring at below-market rates reliably produces rework costs that erase any initial savings within 6 months.
Which skills separate mid-level from senior LLM engineers?
Senior LLM engineers own the evaluation architecture, make model selection and fine-tuning decisions independently, instrument LLM observability from day one, and reason about inference cost versus quality tradeoffs proactively. Mid-level engineers execute well within a defined architecture but need guidance on system design and evaluation methodology.

Ready to Build a Sharper Hiring Process?
If you are actively looking to hire LLM engineer India talent and want to pressure-test your technical assessment before committing to a candidate or a vendor, the team at Ampersand has run this evaluation process across more than 40 LLM and AI engineering engagements.
Most hiring mistakes in this space are not about effort, they are about using the wrong filters. A job description built around framework familiarity and prompt skills will consistently attract the wrong tier of candidate, regardless of how competitive the compensation is. Getting the rubric right before you open the role saves 3–4 months of rework.
We work with product companies, enterprises, and funded startups to define precise skill requirements, design technical assessments, and build LLM engineering teams that are production-ready from day one not six months after onboarding.
If you want to review your current hiring brief or talk through what a realistic LLM engineer profile looks like for your specific use case, reach out directly at mayank@engineerbabu.com. Response time is typically within one business day.
To explore our full AI engineering practice including RAG implementation, fine-tuning engagements, and LLM evaluation consulting visit Supersourcing.
Or if you would prefer to book time directly and walk through your requirements on a call, to schedule a no-commitment conversation.
