The $1.4M Mistake That Started This Guide
A $1.4M Databricks hiring mistake is not rare; it’s increasingly common as enterprises rush into lakehouse adoption without the right validation frameworks. In 2026, companies migrating from legacy Hadoop to modern data platforms often discover too late that “Databricks experience” on a CV doesn’t translate to real production expertise.
Hiring Databricks Engineers from India has become a strategic move for global enterprises building scalable data platforms on Azure, AWS, and GCP. India offers a large pool of data engineers, but the gap between certification-level knowledge and hands-on architecture capability is where most projects fail leading to costly rework, delays, and external consulting dependencies.
The urgency is driven by rapid market growth. According to Fortune Business Insights, the global big data analytics market is projected to reach $745 billion by 2030, with strong growth continuing through 2026 as enterprises invest heavily in data platforms: Big Data Analytics Market Report
As adoption accelerates, the real challenge is not finding Databricks engineers but identifying those who can design scalable lakehouse architectures, implement Unity Catalog correctly, and deliver production-grade performance from day one.
TL;DR 8 Answers Before You Read Further
| Question | Answer |
| What does a Senior Databricks Lead cost from India? | $58–88/hr fully loaded. Section 5 has the full stack by level. |
| Fastest I can close 20 Databricks engineers? | 35–50 days with a pre-vetted bench. 75+ days sourcing cold at that volume. |
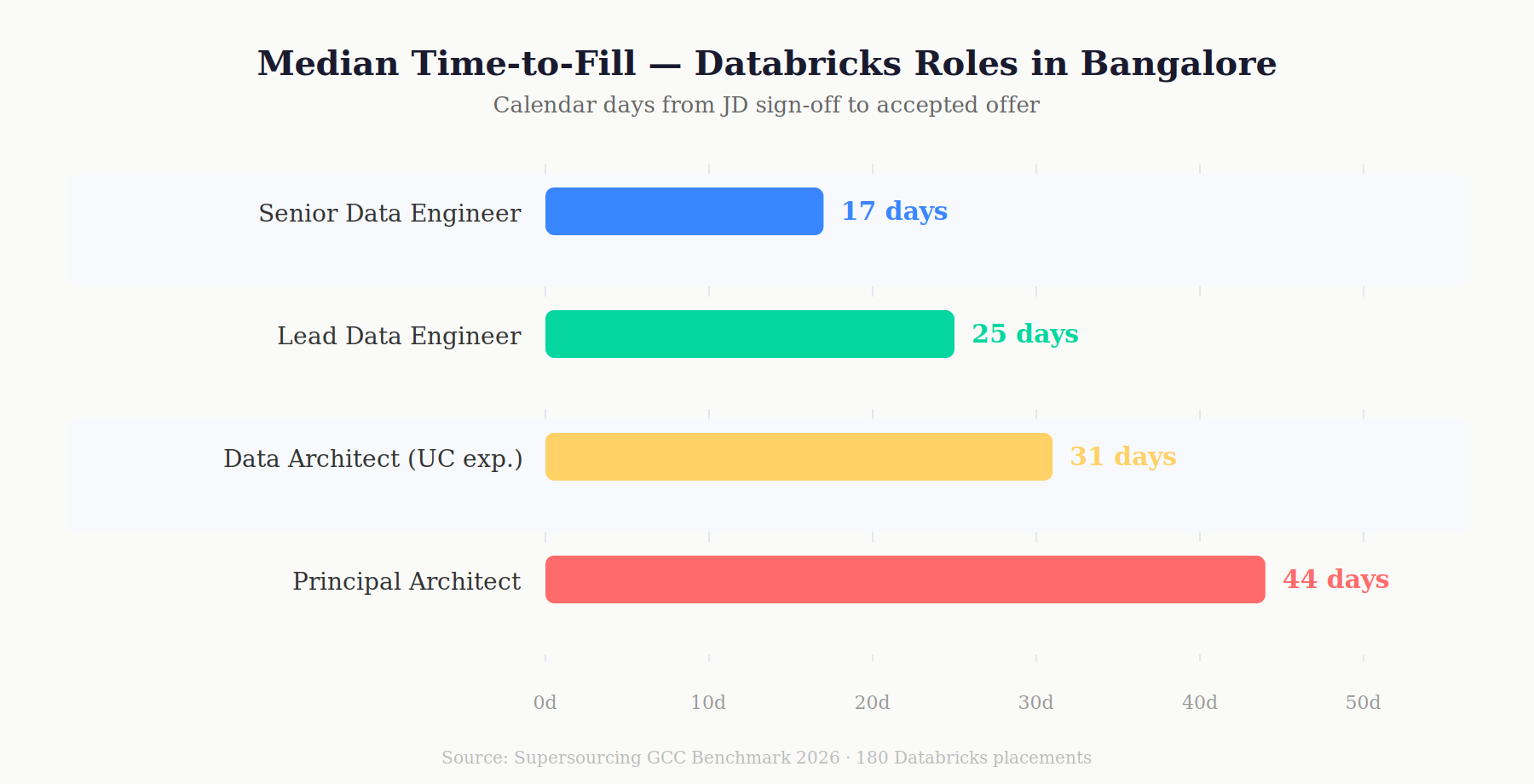
| Which Indian city has the deepest Databricks talent? | Bangalore. Highest density of AWS/GCP-trained data engineers. Databricks median fill: 17 days for Senior, 31 days for Architect. |
| What certification actually matters? | Databricks Certified Professional Data Engineer. Associate is entry-level. Most "Databricks engineers" hold Associate. Ask specifically for a professional. |
| What's the most commonly faked credential? | The Professional cert is presented as verified when the candidate actually holds Associate. Verify at credentials.databricks.com before the interview, not after. |
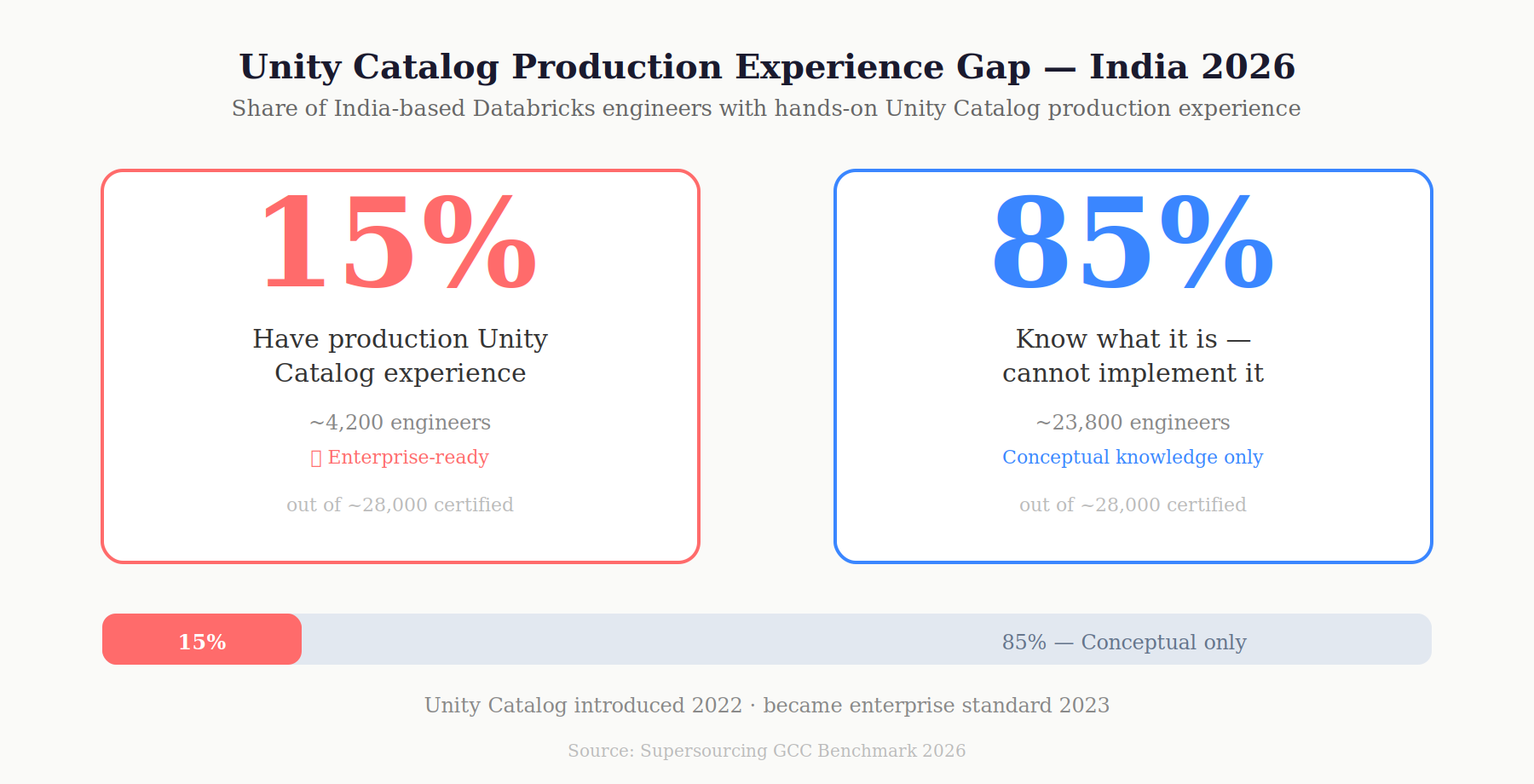
| Unity Catalog How many Indian engineers actually know it? | Fewer than 15% of India-based Databricks engineers have Unity Catalog production experience. It was introduced in 2022. Most teams are still on Hive Metastore. |
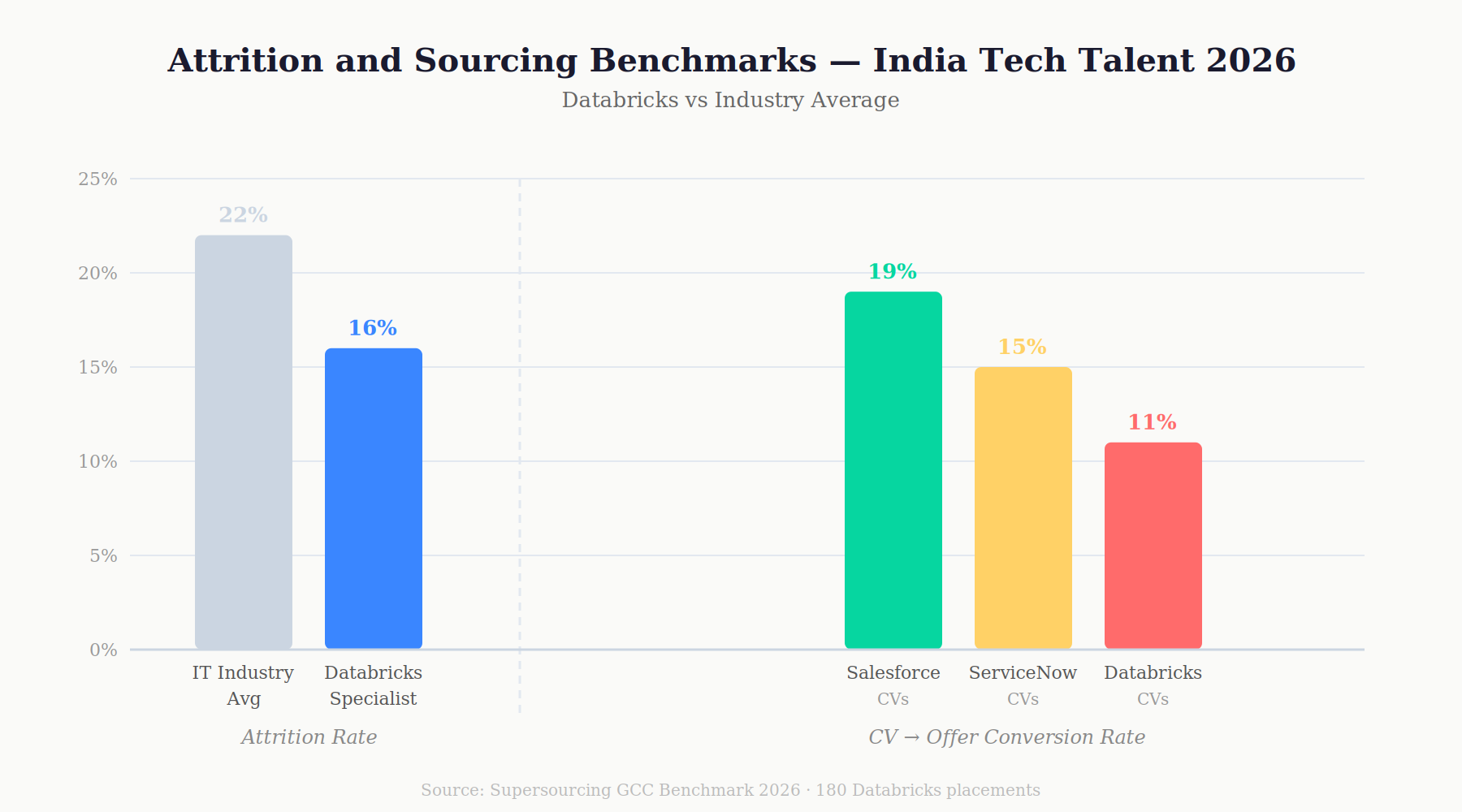
| What's typical attrition for Databricks specialists in India? | 14–18% for mid-senior Databricks engineers. Industry-wide IT average is 22%. Per the Supersourcing GCC Benchmark 2026. |
| How do I know if a candidate has real production experience vs Coursera? | Section 8. Five questions that expose tutorial candidates. The medallion architecture question alone filters 60% of inflated CVs. |
Are You Actually Ready for This?
Before you evaluate vendors, evaluate yourself. Most failed Databricks offshore engagements aren’t vendor failures. They’re buyer-readiness failures the vendor happily signed around.
Score each: 0 (not in place), 2 (partially), 4 (done).
| # | Criterion | Score |
| 1 | Named data platform owner. One person. Not a data committee. | 0/2/4 |
| 2 | JD library defined for Databricks roles you’re hiring | 0/2/4 |
| 3 | Databricks workspace provisioned for offshore team access | 0/2/4 |
| 4 | Unity Catalog governance policy decided who owns the metastore | 0/2/4 |
| 5 | Cloud provider locked (AWS/GCP/Azure) Databricks runtime behavior differs by cloud | 0/2/4 |
| 6 | Data classification policy covering offshore access to production datasets | 0/2/4 |
| 7 | Interview panel with hands-on Databricks experience available within 5 business days | 0/2/4 |
| 8 | Legal SLA under 15 days for MSA review | 0/2/4 |
| 9 | Git integration decided Databricks Repos vs external Git provider | 0/2/4 |
| 10 | Cluster policy ownership defined who approves configs, controls costs | 0/2/4 |
| 11 | KPIs defined: pipeline latency SLA, data quality scores, compute cost per pipeline | 0/2/4 |
| 12 | CISO signed off on offshore access to lakehouse / production warehouse | 0/2/4 |
| 13 | Escalation path defined: vendor PM → your VP Data → your CTO | 0/2/4 |
| 14 | IP ownership for custom pipeline code, notebooks, and Delta schemas in MSA | 0/2/4 |
| 15 | Finance can process USD-denominated invoices within 30 days | 0/2/4 |
What your score means:
| Score | Tier | Reality Check |
| 48–60 | Scaler | You’re ready. This guide is a checklist. |
| 34–46 | Builder | 3–4 gaps. They’ll cost you the first 60 days. Fix before signing. |
| 20–32 | Explorer | Significant internal work needed. Don’t sign an MSA yet. |
| 0–18 | Pre-Stage | You’re 90 days away from a productive offshore Databricks engagement. Start internally. |
From the deal floor: A Series D fintech company 600 employees, AWS-hosted Databricks, building a credit risk lakehouse scored 18 on this checklist. Their VP Engineering signed a 12-person SOW anyway. The cluster policy was never defined. The offshore team spun up development clusters with no auto-termination. Month two AWS bill for Databricks compute: $94,000 against a $22,000 budget. The engagement wasn’t a talent failure. It was a governance failure that the readiness checklist would have caught in 20 minutes.
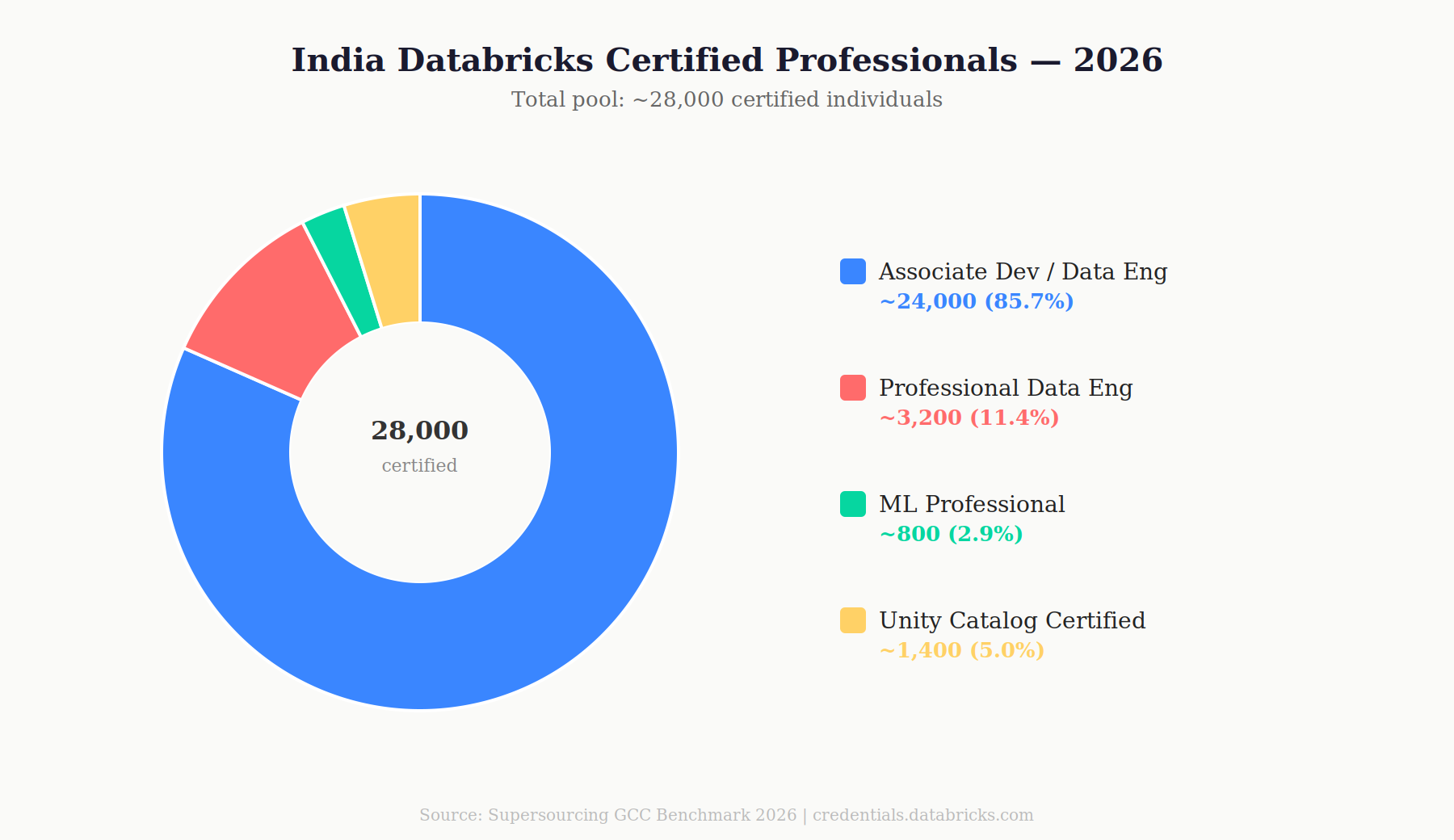
The Databricks Talent Market in India 2026
India’s data engineering talent pool is the largest outside the United States. For Databricks specifically, that statement needs qualification.
The certified pool: As of May 2026, approximately 28,000 Databricks-certified professionals are based in India. That number sounds deep. It isn’t. Break it down:
- Databricks Certified Associate Developer / Associate Data Engineer: ~24,000
- Databricks Certified Professional Data Engineer: ~3,200
- Databricks Certified ML Professional: ~800
- Unity Catalog certified practitioners: ~1,400
The Associate certification is a 90-minute proctored exam testing basic PySpark and notebook usage. It has been available since 2020 and is widely held. The Professional certification tests advanced optimization, streaming architecture, Delta Live Tables, and production system design. It requires real hands-on depth. Most candidates listing “Databricks Certified” on their CV hold Associate, not Professional.
For enterprise programs lakehouse architecture, Unity Catalog governance, multi-workspace environments, production streaming pipelines you need Professional-level practitioners. There are approximately 3,200 of them in India. That’s the real talent pool your vendor is drawing from.
The Unity Catalog gap: Databricks introduced Unity Catalog in 2022 as the unified governance layer replacing the legacy Hive metastore. As of 2026, it’s the standard for any enterprise-grade Databricks deployment. Fewer than 15% of India-based Databricks engineers have configured Unity Catalog in a production environment. The remaining 85% know what it is. They cannot implement it. This is the single most common gap in Databricks engagements sourced from India, and most vendor rate cards don’t reflect it.
Where the talent lives:
| City | Dominant Databricks Use Cases | Why |
| Bangalore | Lakehouse architecture, AWS/GCP Databricks, Delta Live Tables, GenAI/ML pipelines | Highest density of cloud-native data engineers. AWS, GCP, Databricks all have engineering presence here. |
| Pune | ETL modernization, Hadoop-to-Databricks migrations, SAP data integration | Strong legacy data warehouse background from TCS/Infosys CoEs. Transition talent pool. |
| Hyderabad | Azure Databricks, Microsoft Fabric integration, Power BI + Databricks pipelines | Microsoft India HQ effect. Strong Azure data ecosystem. |
| Gurgaon | BFSI data platforms, capital markets data pipelines, regulatory reporting | BFSI GCC concentration. Databricks for financial data use cases. |
| Chennai | Oracle-to-Databricks migrations, batch ETL, legacy modernization | Deep TCS/Cognizant legacy. Strong in migration programs, weaker in greenfield lakehouse. |
Supersourcing Index: Across 180 Databricks placements in the Supersourcing GCC Benchmark 2026, median time-to-fill for a Senior Databricks Data Engineer in Bangalore was 17 calendar days from JD sign-off to accepted offer. For a Databricks Data Architect with Unity Catalog production experience the pool narrows sharply median was 31 days. For a Principal Architect with multi-workspace governance experience: 44 days.
The CV inflation problem: Between 2021 and 2024, Databricks grew from a specialist tool to the dominant enterprise data platform. That growth created a predictable CV inflation wave. Every data engineer who completed the Databricks Fundamentals course free, 6 hours, available on the Databricks Academy added “Databricks” to their profile.
Lakehouse Fundamentals launched in 2022. Associate Developer certification launched shortly after. The result: a massive pool of engineers who can describe the medallion architecture conceptually but have never designed Bronze-to-Gold schema evolution in a production environment.
Red flag: Any vendor claiming “50+ Databricks engineers on bench” without being able to produce Professional cert IDs within 24 hours is presenting an Associate-level pool at a blended lead rate. Ask for cert IDs before the first CV reaches you.
What You’re Really Paying
Most buyers see a rate card and think they understand the cost. They don’t. Four layers sit between a Databricks engineer’s CTC and your invoice.
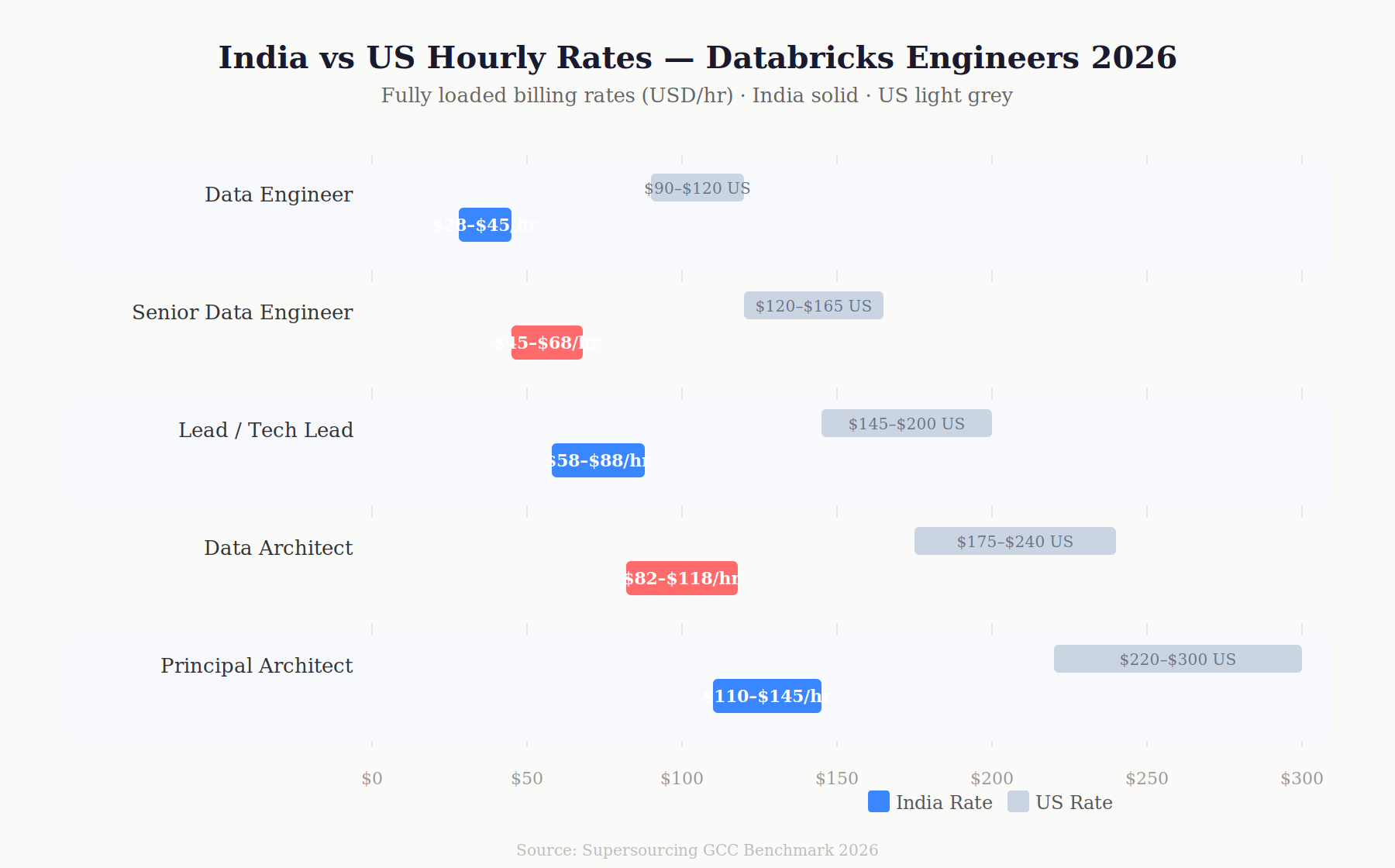
Rate Table by Level
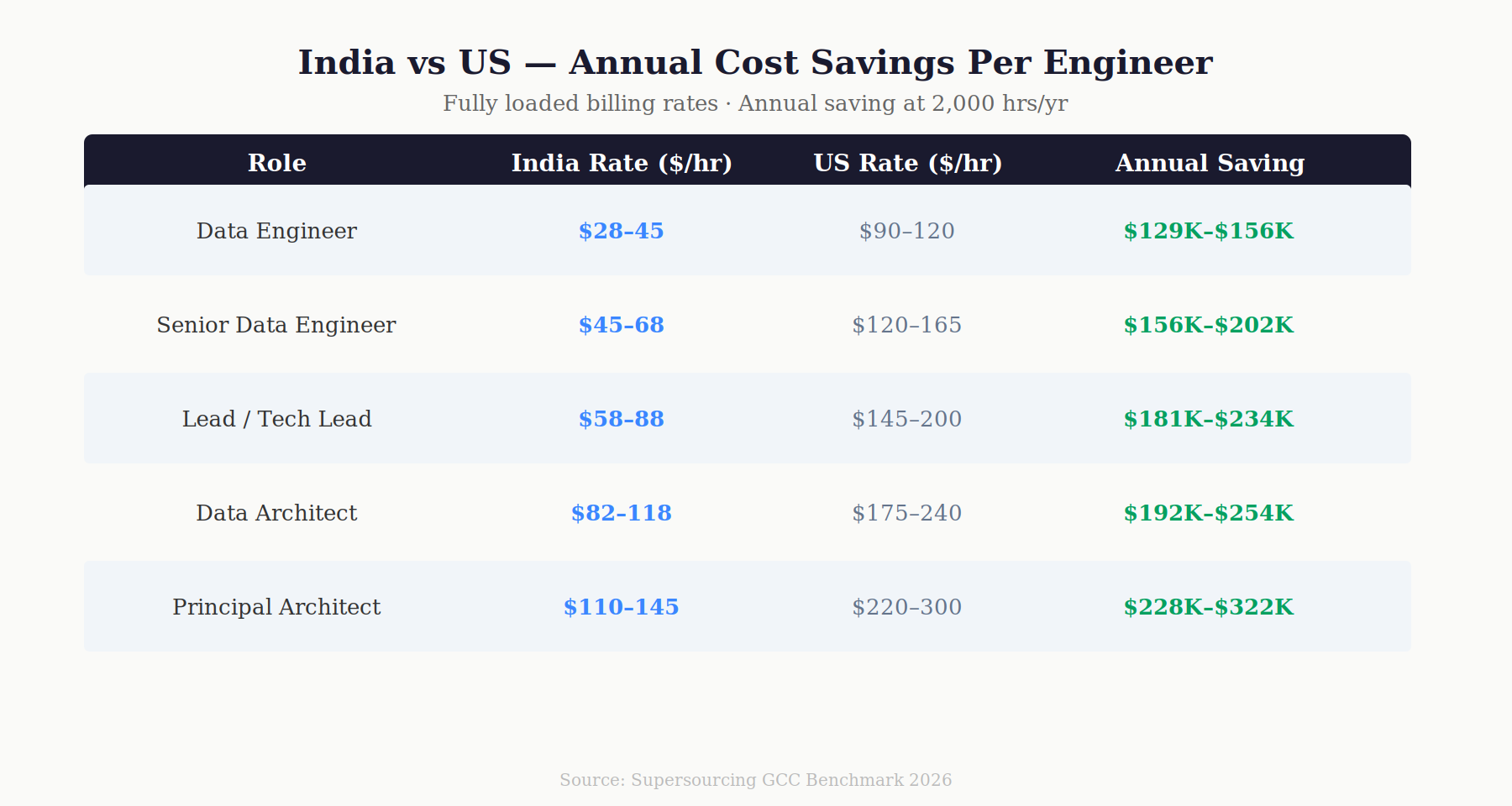
| Level | Experience | India Rate ($/hr) | US Equivalent ($/hr) | Annual Saving ($) |
| Data Engineer | 2–4 yr | $28–45 | $90–120 | $129K–$156K |
| Senior Data Engineer | 4–7 yr | $45–68 | $120–165 | $156K–$202K |
| Lead Data Engineer / Tech Lead | 6–10 yr | $58–88 | $145–200 | $181K–$234K |
| Data Architect | 8–12 yr | $82–118 | $175–240 | $192K–$254K |
| Principal / Platform Architect | 12+ yr | $110–145 | $220–300 | $228K–$322K |
The 4 Cost Layers
Layer 1 Gross CTC
What the engineer earns annually in INR. A Senior Data Engineer with 5 years and Professional cert earns ₹28–42 LPA. At ₹96.4/$1, that’s $29K–$44K USD annually, or $14–21/hr.
Layer 2 Employer Burden
What the vendor pays on top of CTC that never appears on your rate card but is embedded in it:
- Provident Fund (PF): 12% of basic salary (employer contribution)
- Employees State Insurance (ESIC): 3.25% of gross wages
- Gratuity: 8.33–20% of eligible salary (accrues after 5 years)
- Labour Welfare Fund (LWF): state-specific, nominal
- Performance bonus: 8.33% statutory minimum
Total employer burden: 22–28% on top of gross CTC. A ₹35 LPA engineer actually costs the vendor ₹43–45 LPA to employ.
Layer 3 Vendor Margin
For staff augmentation of Databricks specialists, vendor margin runs 18–24% of the fully-loaded cost. At 20% margin on a ₹44 LPA all-in cost, the vendor needs ~₹55 LPA in billing recovery approximately $32/hr just to break even. Everything above that is margin.
Layer 4 What Hits Your Invoice
Your invoice rate for a Senior Databricks Data Engineer: $45–68/hr. That’s Layer 1 + Layer 2 + Layer 3 in one number. At 2,000 hours/year per engineer, a 10-engineer team at a blended $58/hr costs $1.16M annually.
The cloud platform premium: The same engineer profile 6 years, Professional cert, Unity Catalog experience commands different rates depending on platform context:
- AWS Databricks: base rate (deepest pool, most competitive)
- GCP Databricks: +8–12% premium (thinner pool, Google-specific integrations)
- Azure Databricks: +5–10% premium (Microsoft Fabric integration experience commands more)
This is not a quality difference. It’s a supply difference. The same candidate with cross-cloud Databricks experience commands the top of range regardless of your cloud.
Blended team math: A 10-engineer Databricks team 1 architect, 2 leads, 5 seniors, 2 mid-level at market rates runs approximately $1.1–1.3M annually fully loaded. The US equivalent team: $2.8 — 3.4M. Annual saving on a 10-person team: $1.5–2.1M.
The Certification Hierarchy What Actually Matters
The full certification stack:
Databricks Certified Associate Developer for Apache Spark 3.0
Tests basic PySpark, DataFrame API, and notebook usage. 90 minutes. Entry-level. Signals that the candidate can write PySpark in a notebook environment. Does not test Delta Lake, Unity Catalog, streaming, or any production system design. This is the certification most engineers hold. It is not sufficient for senior or lead roles.
Databricks Certified Associate Data Engineer
Newer certification launched in 2023. Tests Delta Lake fundamentals, basic ETL pipeline construction, and simple medallion architecture. Still entry-level, but more production-relevant than the Spark Associate. A mid-level engineer should hold this as a baseline, not a differentiator.
Databricks Certified Professional Data Engineer
The one that matters for enterprise engagements. Tests advanced Delta Lake optimization, Delta Live Tables, Unity Catalog governance, streaming architectures, and production system design. Requires genuine hands-on experience. Approximately 3,200 holders in India. This is the filter to apply for Senior and above.
Databricks Certified Machine Learning Professional
Relevant for ML engineering roles MLflow, Feature Store, model deployment on Databricks. Not a data engineering credential. If you’re hiring for lakehouse and pipeline work, this cert is interesting but not primary.
Unity Catalog Certification
A newer credential validating Unity Catalog governance configuration, metastore architecture, and data access policy design. Approximately 1,400 holders in India. For any enterprise program that requires Unity Catalog which, in 2026, means any serious lakehouse program this should be a required credential for the lead architect role.
How to verify exact steps: Go to credentials.databricks.com. Enter the candidate’s name or badge URL. Every active credential appears with the credential name, issue date, and expiry. Check three things:
- The credential level Associate or Professional. They look similar on a CV. They are not similar in depth.
- Status is Active Databricks credentials expire and require recertification. An expired Professional cert means the engineer has not kept current.
- The specific credential matches the claimed role a “Data Technical Architect” candidate should hold Professional Data Engineer at minimum. Associate only is a mismatch.
The Delta Lake timeline trap: Delta Lake was open-sourced in 2019. Candidates claiming “5 years of Delta Lake experience” in 2026 are pushing the edge of credibility. Anyone claiming Delta Lake experience before 2019 is misrepresenting their timeline. Ask for specific project years.
The Unity Catalog gap in practice: Unity Catalog was introduced in late 2022 and became the default governance layer in 2023. If a candidate has “7 years of Databricks experience” but has never worked with Unity Catalog, one of two things is true: their recent projects were on legacy deployments that haven’t migrated, or they’re describing Databricks experience that predates serious enterprise adoption.
Either way, ask directly: “Walk me through how you’ve configured a Unity Catalog metastore for a multi-workspace environment.” If they can’t answer with specifics, they don’t have production Unity Catalog experience.
The JD That Actually Attracts the Right Candidates
Most enterprise JDs for Databricks roles are written by procurement teams who copied a template from a previous Java hire. They attract the wrong candidates, filter out the right ones, and add 3–4 weeks to the sourcing timeline.
JD 1: Senior Databricks Data Engineer (4–7 years, Staff Augmentation)
Senior Databricks Data Engineer Remote from India Engagement: Staff Augmentation | Duration: 12 months, renewable Rate: ₹28–42 LPA CTC equivalent | Billing: $45–68/hr (vendor-facing)
What you’ll own: Design and build production-grade Delta Lake pipelines on [AWS/GCP/Azure] Databricks. You’ll work within a medallion architecture (Bronze/Silver/Gold), own schema evolution strategy, and contribute to Unity Catalog governance under the direction of our Data Architect. This is a delivery role you’ll be measured on pipeline latency, data quality SLA adherence, and compute cost efficiency.
What we require:
- Databricks Certified Professional Data Engineer (active credential will be verified at credentials.databricks.com before interview)
- 4–7 years in data engineering, minimum 2 years in production Databricks environments
- Hands-on Delta Lake experience: Z-ordering, OPTIMIZE, VACUUM, schema evolution, time travel
- Unity Catalog experience access policy configuration, metastore understanding, catalog/schema/table namespace
- PySpark as primary language (Scala experience is a plus, not a requirement)
- Structured streaming experience: watermarking, late data handling, trigger intervals
- Git-based workflow we use Databricks Repos with PR-based code review, not free-form notebook development
What disqualifies you:
- Associate-only certification for a senior role
- Databricks experience limited to course environments or internal demos
- No Unity Catalog exposure we will not train for this at senior level
- “Big data experience” without specific Delta Lake version history
Interview process: Technical screen (30 min) → Hands-on notebook assessment in a live Databricks workspace (90 min) → Architecture discussion with VP Data (45 min)
JD 2: Databricks Data Architect (10+ years, GCC / BOT Model)
Databricks Data Architect India GCC or BOT Engagement Engagement: GCC Build or BOT | Duration: 24+ months CTC: ₹80–110 LPA | Billing: $95–130/hr (vendor-facing)
What you’ll own: End-to-end Databricks platform architecture for a [industry] enterprise program. You will own the Unity Catalog metastore design, workspace governance structure, cluster policy framework, Delta Live Tables pipeline architecture, and multi-environment promotion strategy. You will be the technical authority for a team of 15–40 data engineers.
What we require:
- Databricks Certified Professional Data Engineer (active) + Unity Catalog certification strongly preferred
- 10+ years in data architecture, minimum 4 years in enterprise Databricks environments
- Designed and delivered at least 2 production Unity Catalog implementations can describe metastore topology, permission inheritance model, and catalog governance design in detail
- Multi-cloud Databricks experience preferred (AWS + one of GCP or Azure)
- Delta Live Tables architecture ownership not just consumption
- Experience governing a 15+ engineer Databricks team: cluster policy design, cost allocation, Git integration strategy
- Familiarity with DPDP Act §10 (India), GDPR Art. 28(3), SOC2 Type II implications for offshore lakehouse access
Interview process: Architecture deep-dive (60 min, whiteboard or Miro) → Live Unity Catalog governance scenario (45 min) → Reference call with prior VP Data client
What most enterprise JDs get wrong for Databricks:
They ask for “experience with big data technologies” which attracts Hadoop engineers from 2015 who added Databricks to their CV. They don’t specify certification level which means vendors send Associate holders for Lead roles. They don’t mention Unity Catalog which signals to good candidates that the client doesn’t know what they actually need. And they list Scala as a requirement when 80% of India-based Databricks engineering happens in PySpark which filters out the exact pool you want and attracts candidates from a different era of the platform.
How to Verify Experience Not Just Credentials
The 3 verification steps before you interview:
Step 1: credentials.databricks.com
Before the CV reaches your interview panel, verify the credential. Go to credentials.databricks.com. Search by name or badge URL from the candidate’s LinkedIn. Confirm: credential level (Associate vs Professional), status (Active vs Expired), and issue date. This takes 90 seconds. Do it before scheduling. Discovering a misrepresented credential after a two-hour interview wastes everyone’s time and signals to the vendor that you’ll accept unverified talent.
Step 2: GitHub profile audit
Ask for the GitHub profile before the interview. A real Senior Databricks engineer in 2026 has public or portfolio code. Look for: Delta table optimization scripts (Z-ordering, compaction), medallion architecture implementations with schema evolution handling, structured streaming notebooks with watermarking, Unity Catalog configuration scripts or Terraform for workspace provisioning. A candidate for a $68/hr senior role with no public code and no portfolio is either working exclusively in locked enterprise environments (possible) or has no production work to show (more likely). Ask for the latter explanation directly.
Step 3: LinkedIn project cross-check
Check the companies listed against the project claims. A candidate claiming “designed a 50TB Delta lakehouse for a Fortune 500 retailer” should have that company in their LinkedIn history, the timeline should match Unity Catalog availability (post-2022 for any UC claim), and the company size should be consistent with the claimed data volume. Candidates who built internal demo environments describe them as production programs. The company size and data volume are the tell.
The 5 interview questions that expose fake seniority:
Q1: Medallion Architecture Design
“Walk me through your Bronze/Silver/Gold schema design for a streaming ingestion use case, your chunking decisions, schema evolution approach, and how you handle late-arriving data.”
Real answer includes: whether they used Delta Live Tables or manual Delta tables and why, specific schema evolution approach (Delta’s schema evolution mode vs explicit enforcement), watermarking configuration for late data (specific trigger interval and watermark delay values), and partition strategy for the Gold layer. They make decisions. They have opinions about tradeoffs.
Tutorial candidate says: “Bronze is raw data, Silver is cleaned, Gold is aggregated.” Describes the architecture conceptually. Make no decisions. Uses no specific numbers.
Q2: Unity Catalog Architecture
“How does Unity Catalog’s metastore architecture change your governance approach compared to Hive metastore? Walk me through how you’ve configured it for a multi-workspace environment.”
Real answer describes: the three-level namespace (catalog/schema/table), the difference in permission inheritance between UC and Hive, why the centralized metastore matters for multi-workspace governance, and how they handled the migration from legacy Hive. They can name the specific metastore region and describe the account-level vs workspace-level permission split.
Tutorial candidate says: “Unity Catalog is the newer governance layer, it’s more centralized.” Cannot describe the permission model or the metastore topology.
Q3: Delta Table Query Optimization
“A Delta table query is running slowly, walk me through your diagnostic process and the optimizations you’d apply.”
Real answer: DESCRIBE DETAIL to check file count and size distribution, OPTIMIZE with Z-ordering on high-cardinality filter columns, VACUUM to remove stale files, partition analysis to check partition skew, and cache strategy for hot data. They describe the order of operations and the tradeoff between Z-ordering write cost and read performance.
Tutorial candidate describes optimization generically. Says “we can optimize the query.” Cannot describe DESCRIBE DETAIL output or explain why Z-ordering helps specific query patterns.
Q4: Streaming Architecture
“When do you choose Delta Live Tables over manual Delta streaming, and what are the operational tradeoffs?”
Real answer: DLT for declarative pipeline definitions where data quality expectations (expectations framework) matter, ease of pipeline monitoring, and reduced operational overhead. Manual Delta streaming for more complex event-time handling, custom state management, or scenarios where DLT’s abstractions are too constraining. They can describe DLT’s expectations framework specifically and explain a scenario where they chose manual streaming instead.
Tutorial candidate says: “Delta Live Tables is newer and easier to use.” Cannot describe the expectations framework or explain a scenario where manual streaming was the right choice.
Q5: Multi-Workspace Governance
“Describe how you’ve governed data access policy across workspaces in a regulated HIPAA, PCI, or SOC2 context.”
Real answer describes: Unity Catalog permission inheritance model across workspaces, how they’ve used catalog grants to separate PII data from non-PII in a shared metastore, row-level security implementation using dynamic views in UC, and the audit log configuration for compliance reporting. They can name the specific regulation and describe how Databricks features are mapped to the control requirements.
Tutorial candidate describes data governance conceptually. Cannot describe row-level security in Unity Catalog or map Databricks features to compliance controls.
8 CV red flags exact language to watch for:
- “Databricks experience” with no cert level specified and no named production system
- “Delta Lake experience from 2017 or 2018” Delta Lake was open-sourced in 2019
- “Unity Catalog implementation experience” on a project that ended before Q3 2022 UC wasn’t available
- “LLM/GenAI Databricks experience” without Mosaic AI or MLflow specifics signals Coursera-level exposure
- “Hadoop + Databricks” listed at equal depth Hadoop-first engineers presenting as Databricks-native
- Multiple “large-scale” projects all at the same company likely one implementation described multiple times
- “Databricks certified” without specifying Associate or Professional
- “Spark optimization experience” without mentioning the Catalyst optimizer or Tungsten execution engine real Spark engineers know the underlying framework
How to Source What’s Working, What Isn’t
What’s working in 2026:
Databricks Champions and Community forums.
Databricks runs a Champions program for highly active community contributors. Champions in India have approximately 40 active ones almost uniformly at Principal or Architect level. They post solutions in the Databricks community forums, speak at DataAI Summit, and have verifiable public technical presence. A VP Data who spends 30 minutes in the Databricks community forum before engaging a vendor has a shortlist of names worth asking for specifically.
GitHub search for Unity Catalog + Delta Live Tables.
Search GitHub for repositories containing both “unity_catalog” and “delta_live_tables” with India-based contributors. This surfaces active practitioners who have committed production-quality code. These are passive candidates; they’re not on Naukri or LinkedIn actively but they respond to direct, specific outreach.
3 ready-to-use LinkedIn boolean search strings:
String 1 (Senior Engineer): “Databricks” AND “Unity Catalog” AND “Delta Live Tables” AND (“Senior” OR “Lead”) AND “India”
String 2 (Architect): “Databricks” AND “Professional Data Engineer” AND (“Architect” OR “Principal”) AND (“Bangalore” OR “Hyderabad”)
String 3 (Unity Catalog specialist): “Unity Catalog” AND “metastore” AND “Databricks” AND (“India” OR “Bangalore” OR “Pune”)
Databricks Partner Network referrals. Databricks maintains a partner directory of certified implementation partners in India. Partners keep bench rosters of available engineers. A direct inquiry to 3–4 Databricks-certified partners in Bangalore yields a curated shortlist faster than a general vendor search. Partners have skin in the game; they don’t want to damage their Databricks relationship by referring to unqualified candidates.
Supersourcing pre-vetted bench. For Senior Data Engineers, Supersourcing’s median fill time from JD sign-off to accepted offer is 17 calendar days. The bench is credential-verified cert IDs confirmed at credentials.databricks.com before any CV is submitted.
What isn’t working:
Generic “big data” job postings on Naukri.
Naukri is India’s dominant job board for mid-market hiring. For Databricks, it floods your pipeline with Hadoop engineers from 2015 who added Databricks to their profile when the platform became dominant. Every applicant looks like a Databricks engineer. Almost none of them are. The filtering overhead is enormous and the signal-to-noise ratio is the worst of any sourcing channel for this stack.
Asking vendors for “Databricks CVs” without specifying Unity Catalog + Professional cert.
If you send a vendor a generic Databricks JD, they will send you 15 CVs of Associate-certified engineers at Lead rates. Not because they’re dishonest. Because “Databricks experience” is how their internal search works and Associate is what the pool contains. Specify Professional cert level and Unity Catalog production experience in the vendor brief. Cut the inbound pool by 80%. Improve quality by 300%.
Referral-only sourcing at scale.
The Databricks practitioner community in India is tight. For 1–2 hires, referrals work. For a 20-engineer program, referral-only sourcing adds 45–60 days to your timeline. The community isn’t large enough to absorb that volume on referrals alone.
Interviews without hands-on assessment.
A verbal Databricks interview in 2026 is not a filter. Good candidates have been coached. Tutorial-level candidates can describe medallion architecture from memory. The only reliable filter is a 60–90 minute hands-on assessment in a real Databricks workspace, a notebook task that requires live Delta Lake optimization, schema evolution handling, or Unity Catalog permission configuration. Candidates who can’t do it live haven’t done it in production. This is not debatable.
Supersourcing Index: Pipeline-to-offer conversion rate for Databricks roles in the Supersourcing GCC Benchmark 2026 the percentage of submitted CVs that convert to accepted offers is 11%. For Salesforce: 19%. For ServiceNow: 15%. The Databricks conversion rate is lower not because the talent is worse, but because CV inflation is higher. Of every 100 Databricks CVs submitted by vendors, 11 result in hires that pass the technical bar. The vetting process described in Section 8 is how to find that 11% without interviewing all 100.
The Contract Stack for Databricks Engagements
Four clauses are non-negotiable. Without all four, you are exposed.
Clause 1: Individual Resource Approval with Cert ID
Every engineer who touches your Databricks environment must be individually approved in writing before they start. The SOW schedule should list: engineer name, Databricks cert level, cert ID (verifiable at credentials.databricks.com), and approved workspace access scope. This creates an audit trail and prevents the most common failure of a vendor rotating in an unverified replacement and billing at the approved rate.
Clause 2: Substitution Notice
Any personnel change requires 14 days written notice and client approval before the substitution occurs. The replacement must meet or exceed the credentials of the engineer being replaced. Without this clause, a vendor can replace your approved Senior Data Engineer with an Associate-level hire the week after SOW signing and you have no contractual remedy.
Clause 3: IP Assignment Deed Per Engineer
Executed within 5 business days of each engineer’s start date. Must cover: pipeline code, notebook code, custom Delta table schemas, Unity Catalog configuration scripts, and any proprietary data transformation logic. Generic MSA IP clauses are insufficient for Databricks engagements because notebook IP is ambiguous in shared workspace environments. The Deed should specify that all work products created in your Databricks workspace under the engagement vests in you, including Delta table definitions and Unity Catalog permission policies.
Clause 4: Workspace Access Termination
All vendor engineer user accounts in your Databricks workspace must be deactivated within 24 hours of engagement end. Unity Catalog service principals used by vendor engineers must be revoked. Cluster policies associated with vendor access must be reviewed and updated. Personal access tokens issued to vendor engineers must be invalidated. This needs to be a contractual obligation with a breach remedy, not a best-effort offboarding process.
Databricks-specific IP risk: Three risks that standard MSA IP clauses don’t address:
Notebook code in shared workspaces. If vendor engineers are working in a shared Databricks workspace with your internal engineers, notebook ownership is ambiguous by default. The IP Deed must specify that any notebook created in your workspace instance, regardless of who created it, is your IP.
Unity Catalog permission inheritance. When an engagement ends, service principals and group memberships in Unity Catalog don’t automatically expire. A vendor engineer who was granted MODIFY on a Gold catalog table retains that permission until it’s explicitly revoked. The termination clause must specify UC permission revocation as a day-one offboarding action.
Delta table schema IP. Custom Delta table schemas with proprietary business logic embedded in column naming conventions, partition strategies, or Z-ordering patterns are valuable IP. They are not covered by standard software IP clauses, which reference “code.” Your MSA must explicitly include “data architecture specifications and Delta table schema definitions” in the IP assignment scope.
Compliance overlay for Databricks engagements:
- DPDP Act §10 (India): If your lakehouse contains personal data of Indian citizens, your vendor is a Data Processor under the Digital Personal Data Protection Act 2023. Require a DPDP-compliant Data Processing Agreement addendum. Verify the vendor has a documented data processing register.
- GDPR Art. 28(3): If EU personal data flows through your Databricks environment, the vendor must execute a GDPR-compliant DPA. Verify their Data Processing Agreement covers sub-processor obligations.
- SOC2 Type II: For any vendor whose engineers access production lakehouse data, require SOC2 Type II certification not Type I, not a self-assessment. Verify against the issuing auditor directly, not the PDF the vendor sends you.
Running a Databricks Team at Scale
Governance model for a 20+ engineer program:
Workspace structure.
Production, staging, and development workspaces should be separate Databricks workspace instances, not separate folders in the same workspace. Offshore engineers should have MODIFY access to development and staging, and read-only or no access to production until code is promoted through a reviewed PR process. This is a Unity Catalog configuration decision that must be made before the first engineer is onboarded.
Unity Catalog metastore ownership.
One named person on your team ideally your data platform owner holds the account-level Unity Catalog admin role. Vendor engineers should be granted catalog-level or schema-level permissions, never account-level admin. When the engagement ends, revoking catalog-level grants is a 10-minute operation. Revoking account-level admin access that was incorrectly granted is a security incident.
Git integration.
Databricks Repos (native Git integration) or an external Git provider connected via Databricks either works. What doesn’t work: free-form notebook development without version control. On a 20+ engineer team, unversioned notebooks accumulate at a rate that makes the codebase unmanageable within 6 months. Mandate PR-based code review for any notebook or pipeline code that touches Silver or Gold layer data. This is not a preference. It is the difference between a maintainable platform and a legacy system at month 18.
Cluster policy ownership.
Define cluster policies before the first engineer logs in. Policies should cap maximum cluster size, require auto-termination (60 minutes of inactivity is a standard default), restrict instance types to approved list, and require cost tagging for pipeline attribution. Without cluster policies, offshore teams who are not paying your AWS/Azure/GCP bill default to large clusters and forget to terminate them. The fintech case in Section 3 was entirely preventable with a 30-minute cluster policy setup.
Early warning signals that a Databricks engineer is disengaging:
- Declining notebook commit frequency visible in Databricks Repos commit history
- Cluster cost spikes on their assigned clusters sign of inefficient code being pushed without review, or of padding compute time
- Missing sprint demos without prior notice
- LinkedIn activity spike Databricks skills updated, new connections from data companies, “Open to Work” signal
- Reduced pull request participation reviewing fewer PRs than their peers
Retention levers specific to Databricks engineers in India:
Platform evolution keeps them. Engineers who work on Delta Live Tables, Databricks SQL, Unity Catalog governance, and Lakehouse Federation stay significantly longer than those running legacy ETL pipelines. The platform is evolving fast. Engineers who get to work on the new surface area Mosaic AI, Databricks Apps, Delta Sharing are not looking for the door.
Certification sponsorship is cheap and effective. The Professional Data Engineer exam costs approximately $200. Sponsoring it costs you $200. The retention signal it sends “we invest in your development” is worth multiples of that. Engineers who are mid-certification don’t leave. Supersourcing’s data across 180 Databricks placements: engineers whose Professional cert was sponsored by the engagement client had a 34% lower attrition rate in the first 18 months than those who self-funded.
Architecture ownership is the strongest retention lever. A data engineer who owns Unity Catalog governance for a 30-person team, who designs the workspace promotion strategy, who is the technical authority on cluster policy, that person has status in the engagement and a career story they can tell. They don’t leave for a 15% salary bump. Money buys a departure meeting, not a resignation letter. Ownership prevents the departure meeting.

When Things Go Wrong
Pattern 1: The Unity Catalog Retrofit
A 600-person US logistics company hired 8 Databricks engineers through a staffing vendor for a supply chain lakehouse program. The engagement ran for 6 months. At the 6-month review, the client’s new VP Data joining from a company with a mature Databricks deployment discovered the team was running on legacy Hive metastore. Unity Catalog had never been configured. Six months of pipeline development was built on a governance layer the client had already decided to deprecate before the engagement started. It was never in the SOW requirements because the previous VP Data didn’t know to require it.
The retrofit took 14 weeks. Two senior engineers had to be replaced because their Unity Catalog knowledge was insufficient. An external Databricks architect was brought in at $175/hr to design the metastore migration. Total rework cost: approximately $280K. Total delay to lakehouse go-live: 4 months.
What the interview should have caught: the Q2 Unity Catalog question in Section 8. If the lead engineer can’t describe the metastore topology, they don’t have Unity Catalog experience. If the vendor can’t produce a Unity Catalog cert ID, they don’t have verified experience. These are 90-second checks.
Pattern 2: The Notebook Sprawl Problem
A US fintech company Series C, 400 employees ran a 30-engineer Databricks program for 18 months with no Git integration and no cluster policy. The dedicated team used free-form notebook development in a shared workspace. By month 18: 4,200 notebooks in the shared workspace, no version history, no owner attribution, $180K/year in uncontrolled compute costs (clusters left running, oversized instance types, no auto-termination), and a codebase that no new engineer could onboard to in under 6 weeks.
The governance fix required 3 months of dedicated platform engineering work migrating notebooks to Databricks Repos, establishing cluster policies, implementing cost tagging, and removing duplicate pipelines. The fix cost approximately $160K in engineering time. The root cause: no readiness checklist before the engagement started (see Section 3, criteria 9 and 10).
Pattern 3: The Associate-Presenting-as-Lead
A UK-based retail enterprise presented with a “Databricks Lead Data Engineer” at £58/hr through an Indian staffing vendor. The CV listed: Databricks Certified Data Engineer, 6 years of experience, medallion architecture experience, Unity Catalog implementation. All credible on paper.
The credential check which the client’s procurement team did not do before scheduling revealed: the certification was Associate Data Engineer, not Professional. The Unity Catalog “implementation” was a training environment. The 6 years included 4 years of Hadoop work with Databricks added in year 5.
The client discovered this at the technical interview when the candidate could not answer the Unity Catalog metastore question. The vendor replaced the candidate. The replacement took 3 weeks. The client lost 3 weeks of delivery runway because they didn’t run a 90-second credential check.
The SOW also had no substitution clause, so the vendor billed for the 3-week gap as “bench time.” The client paid £26K for zero delivery. The substitution clause in Section 10 costs nothing to add and would have made that billing impossible.
When India Is the Wrong Call for Databricks
Be honest. Three scenarios where India-based Databricks hiring creates more risk than it resolves.
Scenario 1: Highly regulated, niche platform combinations.
If your program requires Databricks + Azure Purview integration + Microsoft Fabric + GDPR operational compliance + financial IT services regulatory reporting the overlap of all five in a single engineer profile is genuinely thin in India. You can find Databricks engineers. You can find Azure engineers.
Finding someone who has configured Databricks-to-Purview lineage tracking in a GDPR-regulated European financial services environment is a different proposition. For this profile, the sourcing timeline is 60–90 days and the rate is at the top of the Architect range. If you need it faster or cheaper, consider a US or European-based architect for the governance design and India-based engineers for the execution layer.
Scenario 2: West Coast US programs with hard real-time collaboration requirements.
India Standard Time is UTC+5:30. For US East Coast programs New York, Boston, Charlotte there’s a 2.5–3 hour morning overlap that works for standups, PR reviews, and architecture calls. For US West Coast programs San Francisco, Seattle, Los Angeles the overlap is minimal unless your India team works late shifts. If your VP Data is in San Francisco and expects to pair with the lead architect on production incidents in real time, the timezone math doesn’t work without a structured late-shift arrangement, which adds 15–20% to the rate. Factor this in before the SOW.
Scenario 3: Greenfield lakehouses where architecture decisions haven’t been made.
Offshore Databricks teams execute architecture. The best ones contribute to it. None of them should be making foundational architecture decisions in a vacuum, which cloud, which Unity Catalog topology, which streaming framework, or what the Gold layer data model looks like.
If you’re hiring 20 India engineers before you have an onsite or near-shore principal architect who owns the technical vision, you will pay for the rework when the architecture needs to change. The failure pattern in Section 12 Pattern 1 is exactly this. Hire the architect first. Build the team around the architecture.
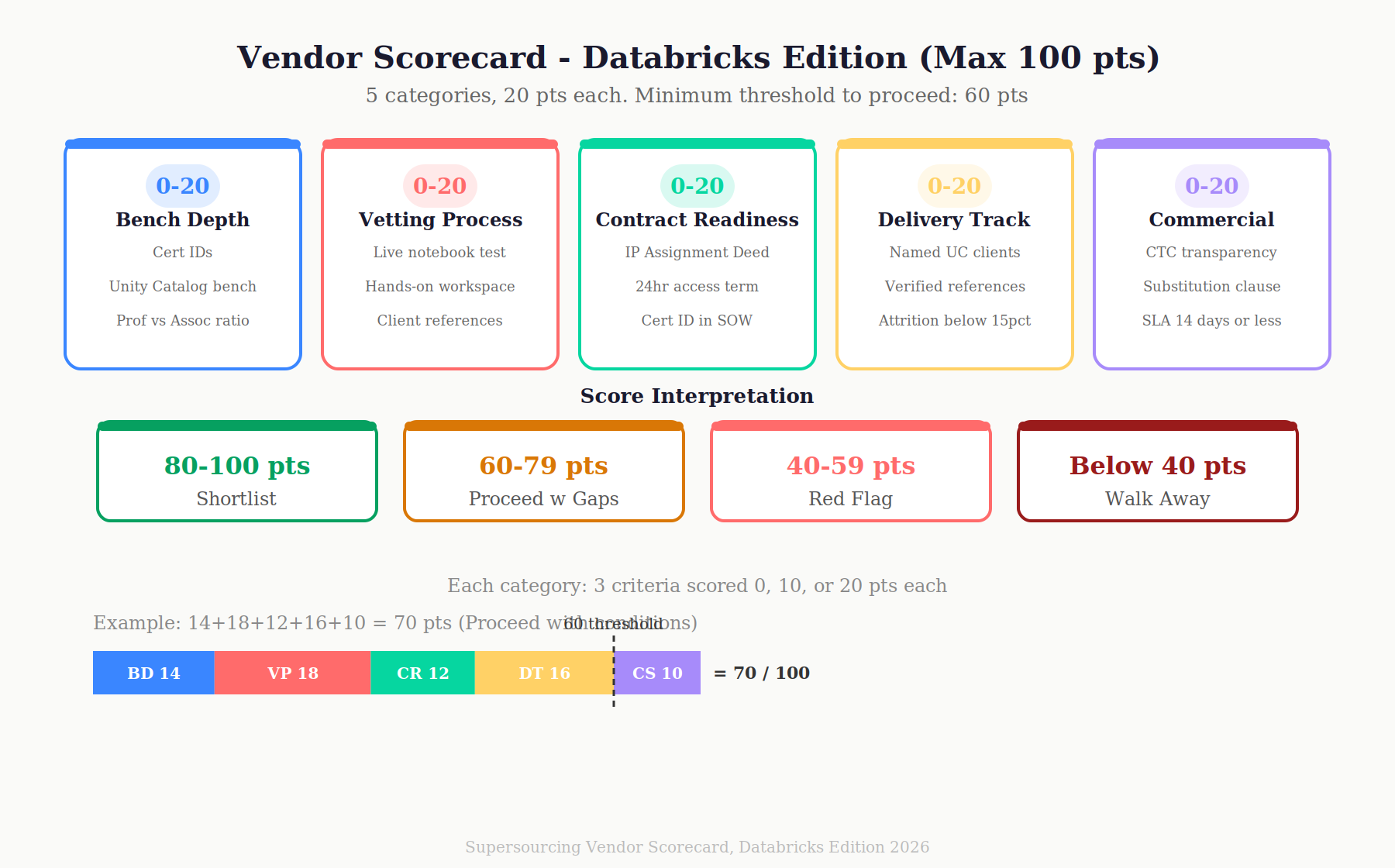
The Supersourcing Vendor Scorecard Databricks Edition
Score your vendor before you sign. Maximum 100 points. Minimum threshold to proceed: 60.
Category 1: Bench Depth (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Can produce Professional cert IDs for claimed bench within 24 hours | Cannot | Some | All claimed bench |
| Unity Catalog-experienced engineers on bench | None | 1–2 | 3+ verified |
| Professional cert holders vs Associate only | Associate only | Mixed | Majority Professional |
Category 2: Vetting Process (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Platform-specific technical assessment | Generic coding test | Databricks-specific written | Live notebook assessment |
| Hands-on assessment in real Databricks workspace | No | Optional | Mandatory for all senior+ |
| Reference check on prior Databricks projects | None | CV-based | Named client references |
Category 3: Contract Readiness (0–20 pts)
| Criterion | 0 | 10 | 20 |
| IP Assignment Deed per engineer in standard MSA | Not available | Available on request | Standard in all SOWs |
| Workspace access termination clause | Not present | Present, vague | Present, specific (24hr) |
| Databricks cert ID in SOW schedule | Never | On request | Standard |
Category 4: Delivery Track Record (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Named Databricks clients they can reference | None | Logo only | Named contact available |
| Completed engagements on Unity Catalog | None claimed | Claimed, unverified | Verified with client reference |
| Attrition rate on Databricks programs | Unknown / >22% | 15–22% | <15% |
Category 5: Commercial Structure (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Rate card transparency (CTC visible on request) | Refused | Partial | Full CTC visible |
| Substitution clause standard | Not present | Available | Standard in all MSAs |
| SLA on replacement if engineer rolls off | None | Best effort | Contractual SLA ≤14 days |
Score interpretation:
- 80–100: Shortlist. Proceed to SOW negotiation.
- 60–79: Proceed with conditions. Close the gap categories before signing.
- 40–59: Red flag. Negotiate hard on Category 2 and 3 minimums or walk.
- Below 40: Walk. A vendor who scores below 40 on this scorecard will cost you more in rework than you save on rate.
15 Questions Buyers Actually Ask
Q: What’s the difference between a Databricks engineer and a Spark engineer?
A Spark engineer understands the Apache Spark execution model Catalyst optimizer, Tungsten execution, RDD vs DataFrame API. A Databricks engineer works on the Databricks platform, which runs Spark but adds Delta Lake, Unity Catalog, Delta Live Tables, Databricks SQL, and MLflow. A Spark engineer without Databricks-specific experience will need 2–4 months to ramp on the platform layer. A Databricks engineer without deep Spark knowledge will struggle with advanced optimization. For enterprise lakehouses, you want both. The Professional certification tests Spark depth within the Databricks context; it’s a reasonable proxy for both.
Q: Should I require Unity Catalog experience or train for it?
Require it for the lead architect and senior engineers. Train for it for mid-level engineers who have strong Delta Lake fundamentals. Unity Catalog configuration is not trivially learnable on the job; the permission inheritance model, metastore topology, and multi-workspace governance design require hands-on experience to do correctly the first time. A mid-level engineer with solid PySpark and Delta Lake skills can learn UC in a structured 4–6 week onboarding if there’s an experienced architect leading the configuration. Without that architect, training mid-level engineers on UC in a production context is a risk.
Q: What’s the realistic timeline to hire a Principal Databricks Architect in Bangalore?
44 days from JD sign-off to accepted offer, per the Supersourcing GCC Benchmark 2026. The pool of Principal-level architects with Unity Catalog production experience and multi-workspace governance depth in India numbers under 200 active practitioners. They are employed. Sourcing them requires a specific outreach strategy, not a job posting. If you need one in under 30 days, you’re paying a premium except top-of-range rates and a bench fee for the sourcing effort.
Q: Can one vendor handle both Databricks and Snowflake on the same program?
Yes, but require separate rate cards and vetting protocols for each stack. A vendor strong on Databricks may not have equivalent Snowflake depth. Bundling the rate card creates an incentive to staff the weaker stack with lower-quality talent to protect margin on the stronger one. Separate SOW schedules with separate approved resource lists give you clean accountability on both stacks.
Q: What happens to notebook IP when the engagement ends?
Whatever your MSA says happens. If your MSA has a generic “work product” IP clause, notebook ownership is ambiguous, notebooks created in a shared workspace environment are not clearly “software code” under most standard definitions. Your IP Assignment Deed (Section 10) must explicitly include notebook code and Delta table schemas. Without it, you have a negotiation problem, not a legal certainty.
Q: Is Databricks on Azure materially different from Databricks on AWS for hiring purposes?
Yes for senior and above roles. The Databricks runtime is the same. The surrounding ecosystem is not. Azure Databricks integrations with Purview, Synapse, ADLS Gen2, and Microsoft Fabric require Azure-specific knowledge. AWS Databricks integrations with Glue, S3, Redshift, and Lake Formation require AWS-specific knowledge. A Principal Architect who has only worked on AWS Databricks will need 2–3 months to develop the Azure ecosystem context for a mixed Azure program. Factor this into your JD and rate expectations.
Q: How do I benchmark a vendor’s rate card against the market?
Three data points: the Supersourcing rate table in Section 5 of this guide (updated May 2026), the Zinnov GCC Benchmark (published annually), and a parallel brief to two competing vendors for the same role at the same specification level. Rate cards that are more than 15% above the Section 5 table for the same role and experience level require justification, usually the vendor is claiming a premium for Unity Catalog or ML specialization. Ask them to verify it.
Q: What’s the minimum team size where India Databricks hiring makes economic sense?
5 engineers for staff augmentation. Below 5, the management overhead onboarding, vendor coordination, timezone overlap, IP setup approaches the cost saving. For a 3-engineer program, a Databricks-specialist boutique or a senior freelancer with strong credentials is a better fit than an enterprise IT staffing engagement.
Q: Can I use a BOT model for a Databricks GCC?
Yes, and it’s increasingly common. The BOT model for a Databricks GCC works well when: you plan to hire 30+ engineers over 3 years, you want to build institutional knowledge and platform ownership internally, and you have a 2–3 year runway before the transfer. The transfer clause must specify that the Databricks workspace ownership, Unity Catalog metastore admin, cluster policies, and Git repository access transfer to your India entity, not just the headcount. Guide 2 in this series covers BOT transfer clause specifics.
Q: How do I evaluate whether a vendor’s Databricks bench is real or theoretical?
Ask for the bench roster: names, specific cert IDs (verified at credentials.databricks.com), current notice periods, and the last project each person worked on. A real bench has people with documented Professional-level credentials who are currently available between engagements or on 30–60 day notice. A theoretical bench is “we can source these profiles” dressed as “we have these people available.” The difference: can they produce credential IDs today? If not, they’re sourcing, not benching.
Q: What’s typical ramp time for a new Databricks engineer joining an existing India team?
3–4 weeks for a Senior Data Engineer joining an established program with documented runbooks, Git-based notebook structure, and a clear cluster policy. 6–8 weeks without that governance infrastructure they spend the first month understanding an undocumented codebase. This is why the governance framework in Section 11 matters: it compresses the ramp time for every engineer after the first cohort, which matters enormously on a 30+ person program with ongoing attrition replacement.
Q: Should I pay a bench fee for a scarce Databricks profile?
For Principal Architects and Unity Catalog specialists, yes, if the vendor can demonstrate the person is real (verified cert ID, live reference, confirmed availability). A bench fee of $500–$1,000/month to hold a verified Principal Architect while your legal team reviews the MSA is cheaper than a 6-week sourcing restart. For Senior Data Engineers no. The pool is sufficient that a bench fee is not warranted unless you need more than 10 engineers simultaneously.
Q: What’s the hardest Databricks role to fill from India in 2026?
Databricks Principal Architect with production Unity Catalog governance experience and multi-cloud Databricks deployment history. The combination of: 12+ years data experience, Databricks Professional cert, Unity Catalog production depth, AWS and Azure cross-cloud experience, and enterprise governance track record narrows the India pool to under 100 active practitioners. Median fill time: 44 days. Expect top-of-range rates. Expect competition from other enterprise buyers for the same profiles.
Q: Is Databricks talent quality in India comparable to US talent?
At the Senior and above level with Professional certification and production Unity Catalog experience: yes, functionally equivalent for execution roles. For greenfield architecture decisions on novel use cases Mosaic AI deployment, Databricks Apps, Lakehouse Federation across multiple clouds the deepest talent is still US-concentrated, because those capabilities are newer and the production deployment base in India is smaller. By 2027–2028, as Indian enterprises accelerate their own Databricks deployments, that gap will close. In 2026, hire from India for execution excellence. Keep architecture leadership onsite or near-shore until the offshore architect has 2+ years in your specific environment.
Q: Is Supersourcing the right partner for a 4-engineer Databricks program?
Not our ideal engagement. Our model is built for 10+ engineer programs with enterprise governance requirements, verified bench depth, and SOW-level accountability. For a 4-engineer program, a Databricks-specialist staffing firm or a verified freelance architect with a small delivery team is a better fit. We’d rather tell you that than win a deal we’ll underserve.
Closing
Databricks hiring from India works. The talent is real, the certifications are verifiable, and the savings versus US hiring are substantial $181K to $322K per engineer per year depending on level. The failure mode is not India. The failure mode is hiring without the verification steps that separate 28,000 “Databricks certified” professionals from the 3,200 who can architect and deliver your enterprise lakehouse program.
This guide is those verification steps. The credential check takes 90 seconds. The Unity Catalog question takes 3 minutes. The notebook assessment takes 90 minutes and eliminates every tutorial-level candidate from your pipeline. None of it is hard. All of it matters.
If you want Supersourcing to run the verification for a specific Databricks role, bring us a JD and we’ll tell you what the talent pool looks like, what the realistic rate is, and how long it’ll take to source someone who passes all the layers.
Book a 30-minute Databricks Talent Discovery Call → No deck. Just the numbers and the bench.
