The $1.6M DevOps Program That Automated the Wrong Things
A US-based healthcare software company 800 employees, 12 microservices on AWS, manual deployment process taking 3 days, infrastructure managed through ad-hoc shell scripts approved a DevOps transformation. The brief: implement Kubernetes on AWS EKS, build GitOps pipelines with ArgoCD, migrate infrastructure to Terraform, implement observability with Prometheus/Grafana, and establish SRE practices with SLOs and error budgets. Twelve months. Six India-based DevOps engineers. $1.6M.
The vendor had strong credentials. Kubernetes certifications. AWS expertise. CI/CD experience. The CVs were technically dense.
What the program discovered at month six: the team had automated prolifically. 14 GitHub Actions pipelines built. Terraform state for 180 AWS resources. ArgoCD manages 8 applications. Prometheus with 340 custom metrics. Grafana dashboards everywhere.
Hiring DevOps & Platform Engineers is where many enterprises miscalculate. Tooling was implemented in pipelines, dashboards, infrastructure as code but core architectural decisions were flawed: insecure Kubernetes design, broken deployment strategies, and missing SLO-driven reliability practices. The result wasn’t speed, it was risk, downtime, and compliance exposure.
This gap is becoming more expensive. According to Statista DevOps market size forecast, the global DevOps market is projected to reach over $25 billion by 2026, driven by enterprise-scale cloud and platform adoption.
The lesson is clear: DevOps success isn’t about how much you automate, it’s about whether you hire engineers who can design systems correctly from day one.
Remediation: network policy implementation (3 weeks), Terraform remote state with locking (1 week), deployment strategy correction across all services (2 weeks), SLO definition and alerting redesign (4 weeks). $195K. The tooling knowledge verified. The architecture judgment is not verified.
This guide is what VP Engineering needed before she signed the SOW.
TL;DR 8 Answers Before You Read Further
| Question | Answer |
| What does a Senior DevOps Engineer cost from India? | $38–62/hr fully loaded. A Platform / SRE Architect runs $72–108/hr. Section 5 has the full rate stack. |
| What's the single most important thing to verify? | Production architecture decisions not tool knowledge. The tooling (Kubernetes, Terraform, ArgoCD) is learnable. Making the right architecture decisions under real production constraints is what separates senior engineers from junior ones with certifications. |
| Which Indian city has the deepest DevOps talent? | Bangalore dominates. Highest concentration of product company DevOps engineers with production platform experience from high-scale systems. |
| What certification actually matters? | CKA (Certified Kubernetes Administrator) for Kubernetes roles. AWS Solutions Architect Professional / GCP Professional Cloud Architect for cloud. Terraform Associate for IaC. HashiCorp Vault for secrets management. These are publicly verifiable. |
| What's the CV inflation problem in DevOps? | Moderate. Tool proficiency is easier to fake than production architecture judgment. The right questions in the interview expose the difference between someone who has run a Kubernetes cluster and someone who has designed one correctly for production workloads. |
| Platform Engineering vs DevOps what's the difference for hiring? | DevOps engineers focus on CI/CD pipelines, automation, and release processes. Platform engineers build the internal developer platforms, the Kubernetes clusters, service meshes, developer portals, and self-service infrastructure that application teams consume. Platform engineering is the senior career path. |
| What's typical attrition for DevOps engineers? | 18–24% annually. One of the highest attrition rates of any stack, skills are highly portable across companies and cloud providers. |
| What's the single biggest hiring mistake? | Hiring DevOps engineers without defining which production problem they're solving. "DevOps engineer" covering Kubernetes, Terraform, CI/CD, observability, SRE, and security is 5 different specialisations. Define the primary focus before hiring. |
Are You Actually Ready for This?
DevOps programs fail when the problem is undefined when a team is hired to “do DevOps” without specific outcomes, specific current-state problems, and specific tooling decisions. Score yourself.
Score each: 0 (not in place), 2 (partially), 4 (done).
| # | Criterion | Score |
| 1 | Named platform owner one person who owns the internal developer platform | 0/2/4 |
| 2 | Current state documented what infrastructure exists, how deployments work today | 0/2/4 |
| 3 | Target state defined specific outcomes: deployment frequency, MTTR, change failure rate | 0/2/4 |
| 4 | Cloud provider confirmed AWS, GCP, or Azure (tooling choices differ significantly) | 0/2/4 |
| 5 | Container strategy confirmed Kubernetes, ECS, or VM-based (Kubernetes is not always the answer) | 0/2/4 |
| 6 | IaC tooling decided Terraform, Pulumi, or cloud-native CDK | 0/2/4 |
| 7 | Observability requirements defined SLOs, error budgets, alerting owners | 0/2/4 |
| 8 | Interview panel with production DevOps architecture experience available within 5 business days | 0/2/4 |
| 9 | Legal SLA under 15 days for MSA review | 0/2/4 |
| 10 | Development environment access provisioned for offshore team | 0/2/4 |
| 11 | Security and compliance requirements defined HIPAA, SOC2, PCI context | 0/2/4 |
| 12 | CISO signed off on offshore access to production infrastructure credentials | 0/2/4 |
| 13 | Escalation path: vendor PM → your Platform Lead → your CTO | 0/2/4 |
| 14 | IP ownership for Terraform modules, Helm charts, and pipeline templates in MSA | 0/2/4 |
| 15 | Finance can process USD-denominated invoices within 30 days | 0/2/4 |
What your score means:
| Score | Tier | Reality Check |
| 48–60 | Scaler | Ready. |
| 34–46 | Builder | Undefined outcomes and tooling decisions will produce automation without impact. |
| 20–32 | Explorer | Define the target state and current problems before engaging any vendor. |
| 0–18 | Pre-Stage | A DevOps team without defined outcomes will automate the wrong things. Section 1 verbatim. |
The DevOps & Platform Engineering Talent Market in India 2026
DevOps and platform engineering is the most broadly defined engineering discipline in enterprise technology. “DevOps engineer” in India covers a spectrum from a developer who knows Jenkins to a Site Reliability Engineer who designed the infrastructure for a 100M-user platform. The skill range within the label is enormous.
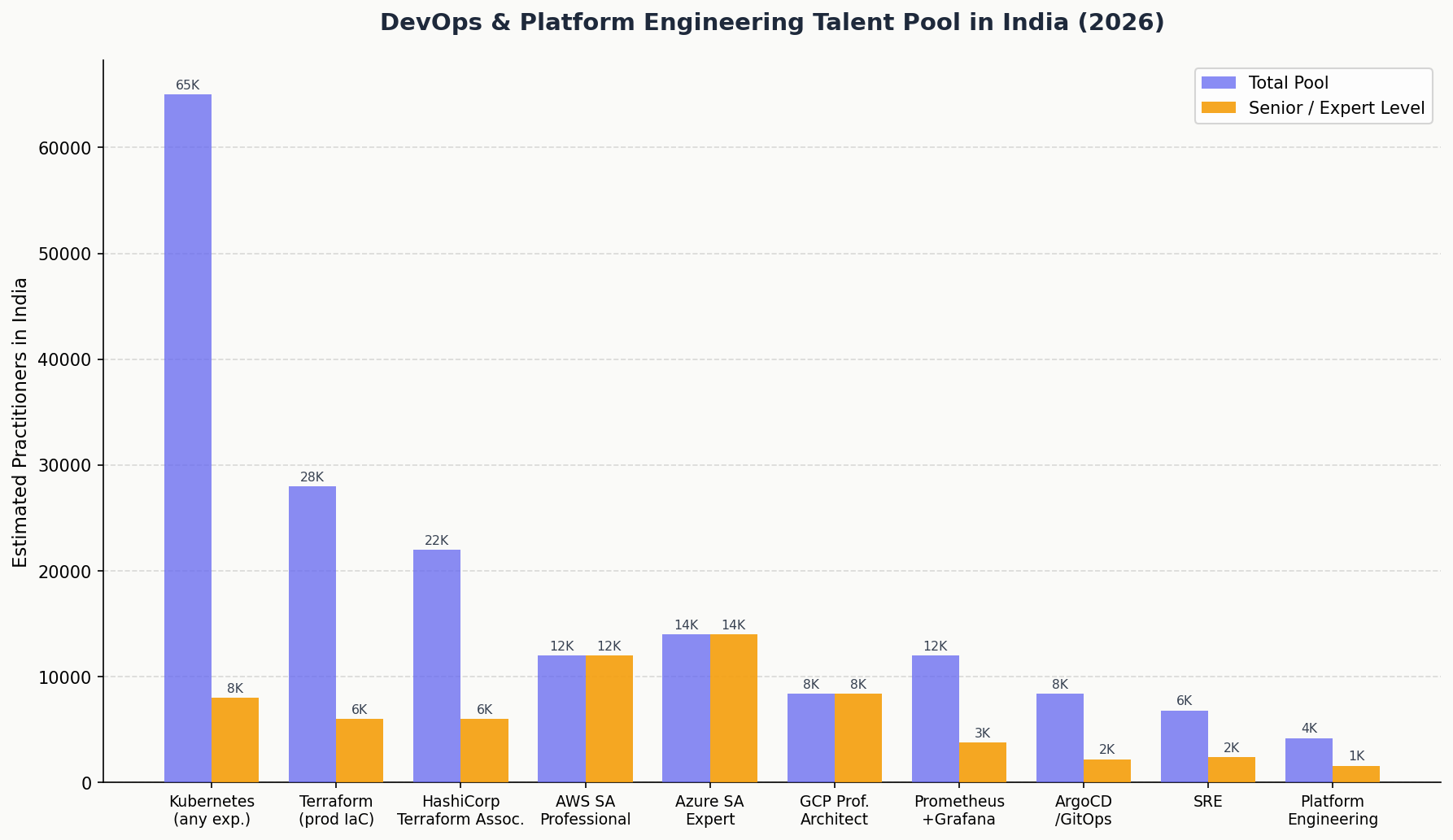
The pool breakdown:
| Specialisation | Estimated India Pool | Senior/Expert Level |
| Kubernetes (any experience) | ~65,000 | ~8,000 |
| CKA (Certified Kubernetes Administrator) | ~18,000 | ~8,000 |
| CKS (Certified Kubernetes Security Specialist) | ~4,200 | ~4,200 |
| AWS Solutions Architect Professional | ~12,000 | ~12,000 |
| GCP Professional Cloud Architect | ~8,400 | ~8,400 |
| Azure Solutions Architect Expert | ~14,000 | ~14,000 |
| Terraform (production IaC experience) | ~28,000 | ~6,000 |
| HashiCorp Certified Terraform Associate | ~22,000 | ~6,000 |
| ArgoCD / GitOps production experience | ~8,400 | ~2,200 |
| Prometheus + Grafana production observability | ~12,000 | ~3,800 |
| SRE (Site Reliability Engineering) | ~6,800 | ~2,400 |
| Platform Engineering (internal developer platforms) | ~4,200 | ~1,600 |
| Service Mesh (Istio / Linkerd) production | ~3,600 | ~1,200 |
| FinOps (cloud cost optimisation) | ~2,800 | ~980 |
The specialisation fragmentation problem:
“DevOps engineer” in a job posting returns candidates with wildly different skill sets. An engineer who specialises in CI/CD pipeline development (GitHub Actions, Jenkins, GitLab CI) has different skills from one who specialises in Kubernetes cluster administration (node pools, RBAC, network policies, storage classes), which differs from one who specialises in infrastructure-as-code (Terraform modules, state management, drift detection), which differs from one who specialises in observability (SLO design, alerting strategy, distributed tracing with Jaeger/Zipkin).
For enterprise programs, define the primary focus before sourcing. The DevOps label covers too much ground for a single JD.
The product company vs SI background distinction:
India’s DevOps talent pool comes from two distinct backgrounds and the difference matters significantly for platform engineering roles.
Product company / startup background: Engineers who have built and operated production systems that real users depend on. They have made architecture decisions under pressure, debugged production incidents, designed for scale, and built platforms that developer teams use. Their experience is operational; they’ve been paged at 2am for production failures.
SI delivery background: Engineers who have implemented DevOps tooling for client programs setting up Jenkins pipelines, configuring Kubernetes clusters, writing Terraform for predefined architectures. Their experience is implementation-focused delivering against specifications rather than designing and operating production systems.
Both backgrounds are valuable. For platform engineering and SRE roles where architecture judgment and operational depth matter, product company background is materially more relevant. For implementation and automation roles where delivery velocity and tooling knowledge matter, SI background is often sufficient.
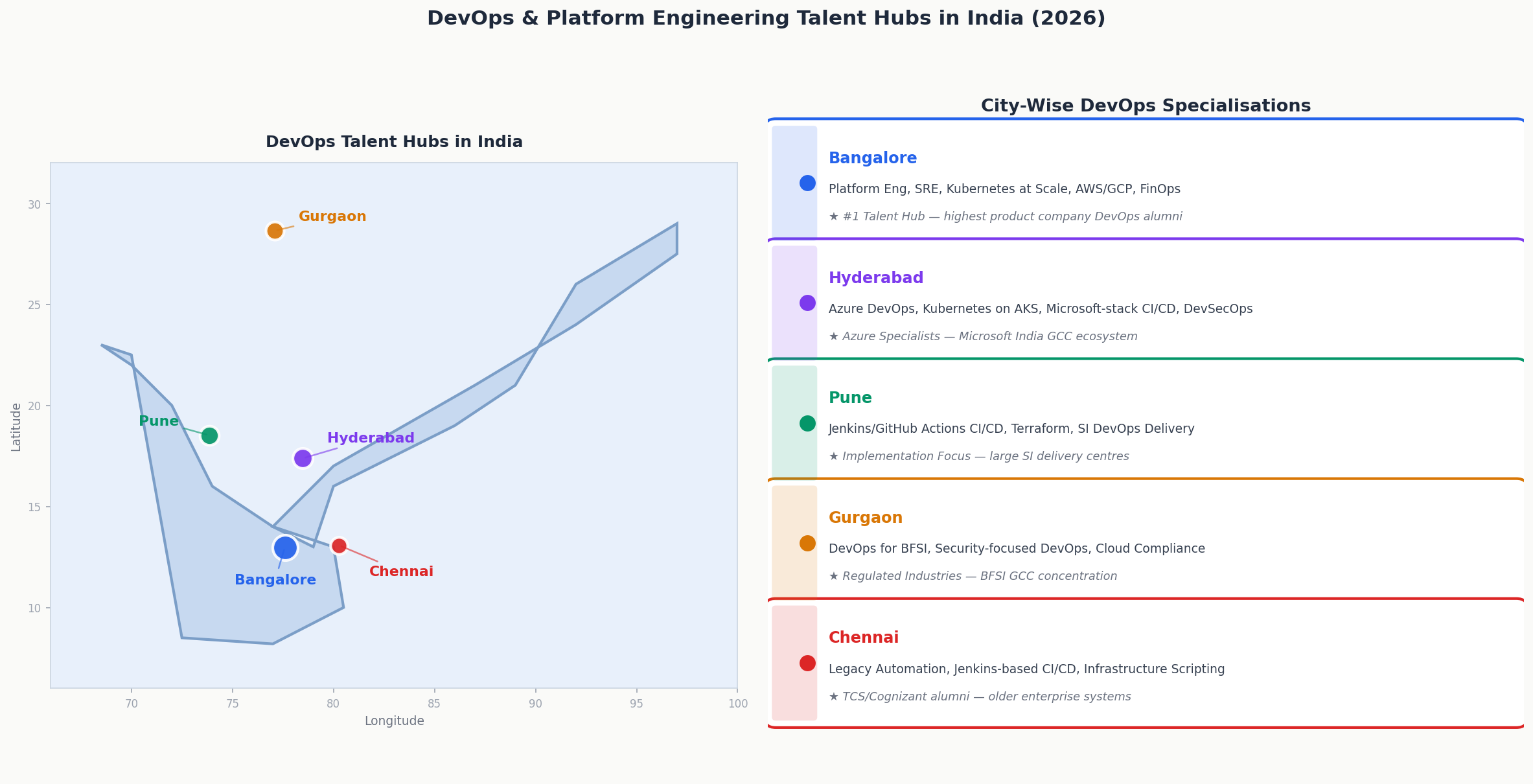
Where the talent lives:
| City | Dominant DevOps Specialisations | Why |
| Bangalore | Platform Engineering, SRE, Kubernetes at scale, AWS/GCP cloud architecture, FinOps | Highest concentration of product company DevOps engineers. US tech GCCs with platform teams. Flipkart, Swiggy, Zepto engineering alumni with production scale experience. |
| Hyderabad | Azure DevOps, Kubernetes on AKS, Microsoft-stack CI/CD, DevSecOps | Microsoft India ecosystem. Azure-heavy enterprise programs. |
| Pune | Jenkins/GitHub Actions CI/CD, Terraform for enterprise programs, SI DevOps delivery | Large SI delivery centers. DevOps implementation for enterprise clients. |
| Gurgaon | DevOps for BFSI, security-focused DevOps, cloud compliance automation | BFSI GCC concentration. Regulated industry DevOps programs. |
| Chennai | Legacy automation, Jenkins-based CI/CD, infrastructure scripting | TCS/Cognizant legacy. Automation for older enterprise systems. |
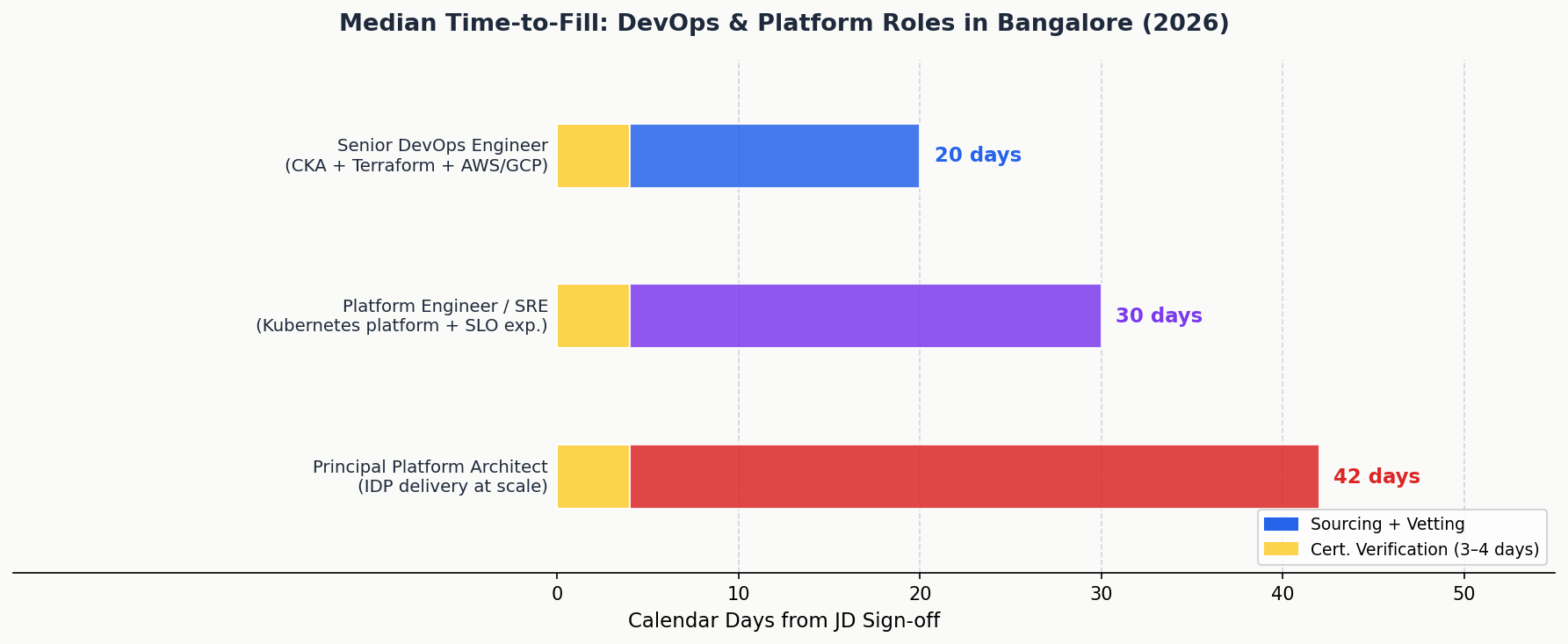
Supersourcing Index: Across 82 DevOps and platform engineering placements in the Supersourcing GCC Benchmark 2026, median time-to-fill for a Senior DevOps Engineer (CKA + Terraform + AWS/GCP, production experience) in Bangalore was 20 calendar days. For a Platform Engineer / SRE with Kubernetes platform design and SLO experience: 30 days. For a Principal Platform Architect with internal developer platform delivery at scale: 42 days.
What You’re Really Paying
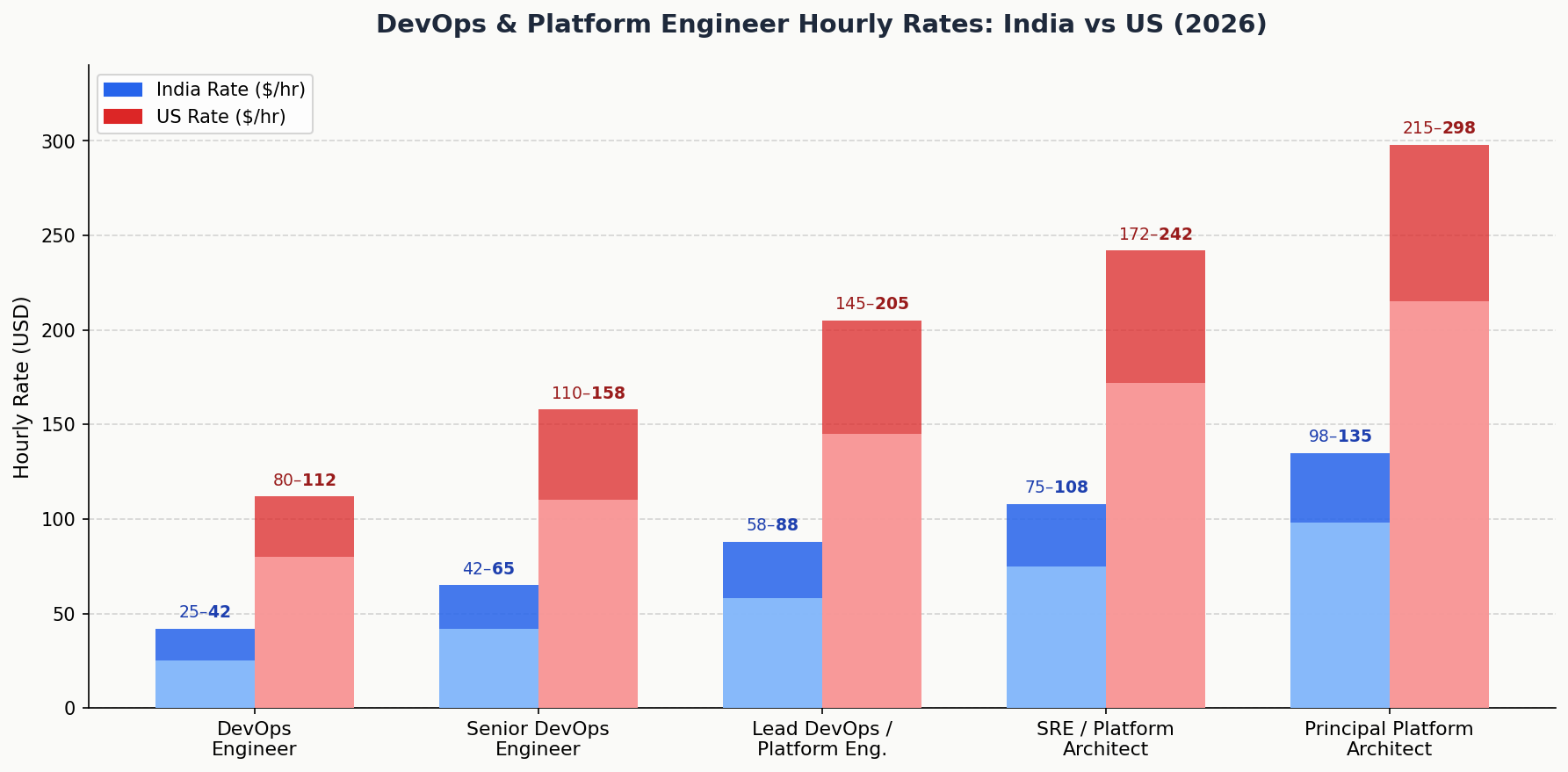
Rate Table by Level
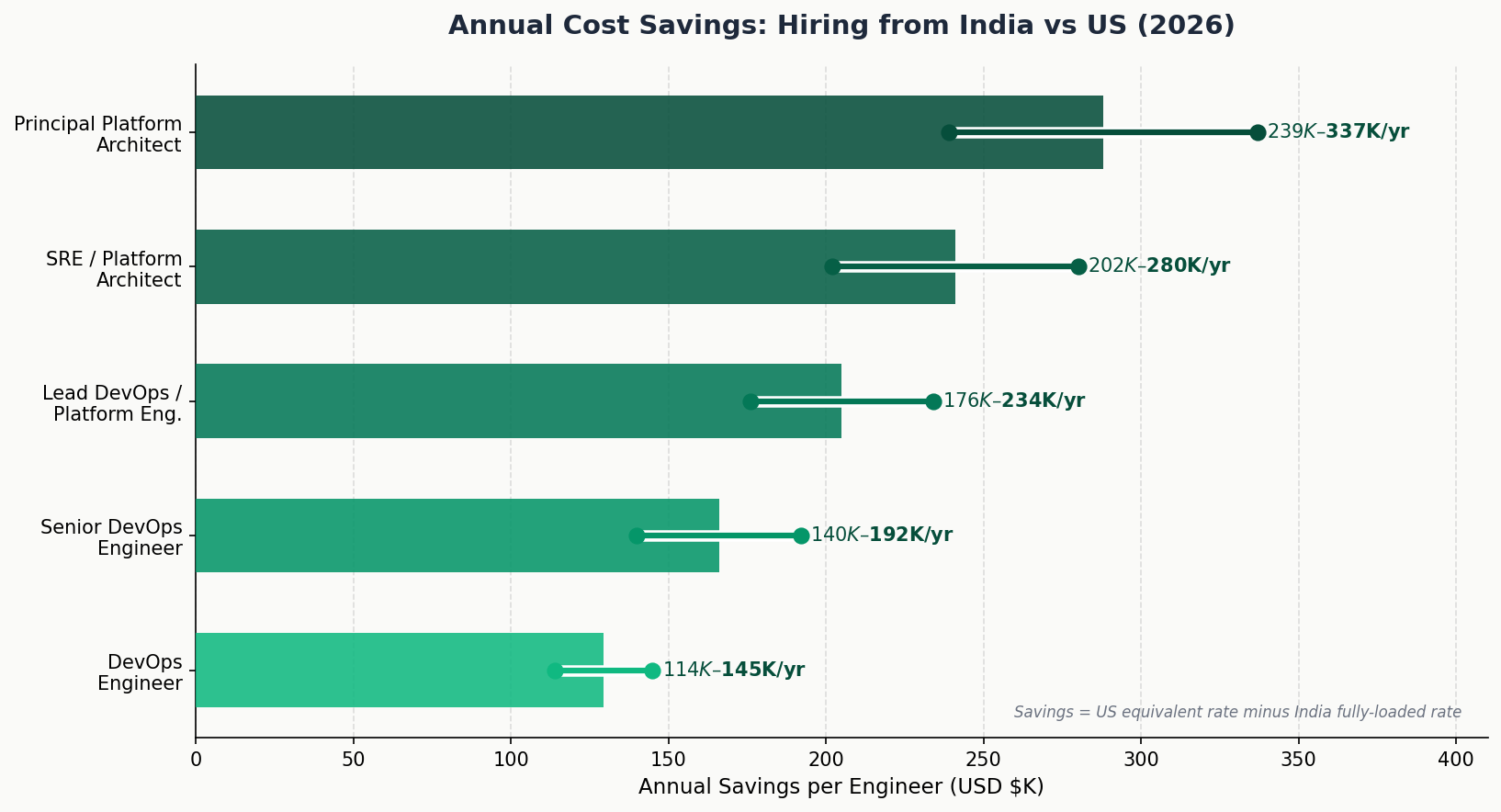
| Level | Experience | India Rate ($/hr) | US Equivalent ($/hr) | Annual Saving ($) |
| DevOps Engineer | 2–4 yr | $25–42 | $80–112 | $114K–$145K |
| Senior DevOps Engineer | 4–7 yr | $42–65 | $110–158 | $140K–$192K |
| Lead DevOps / Platform Engineer | 6–10 yr | $58–88 | $145–205 | $176K–$234K |
| SRE / Platform Architect | 8–12 yr | $75–108 | $172–242 | $202K–$280K |
| Principal Platform Architect | 12+ yr | $98–135 | $215–298 | $239K–$337K |
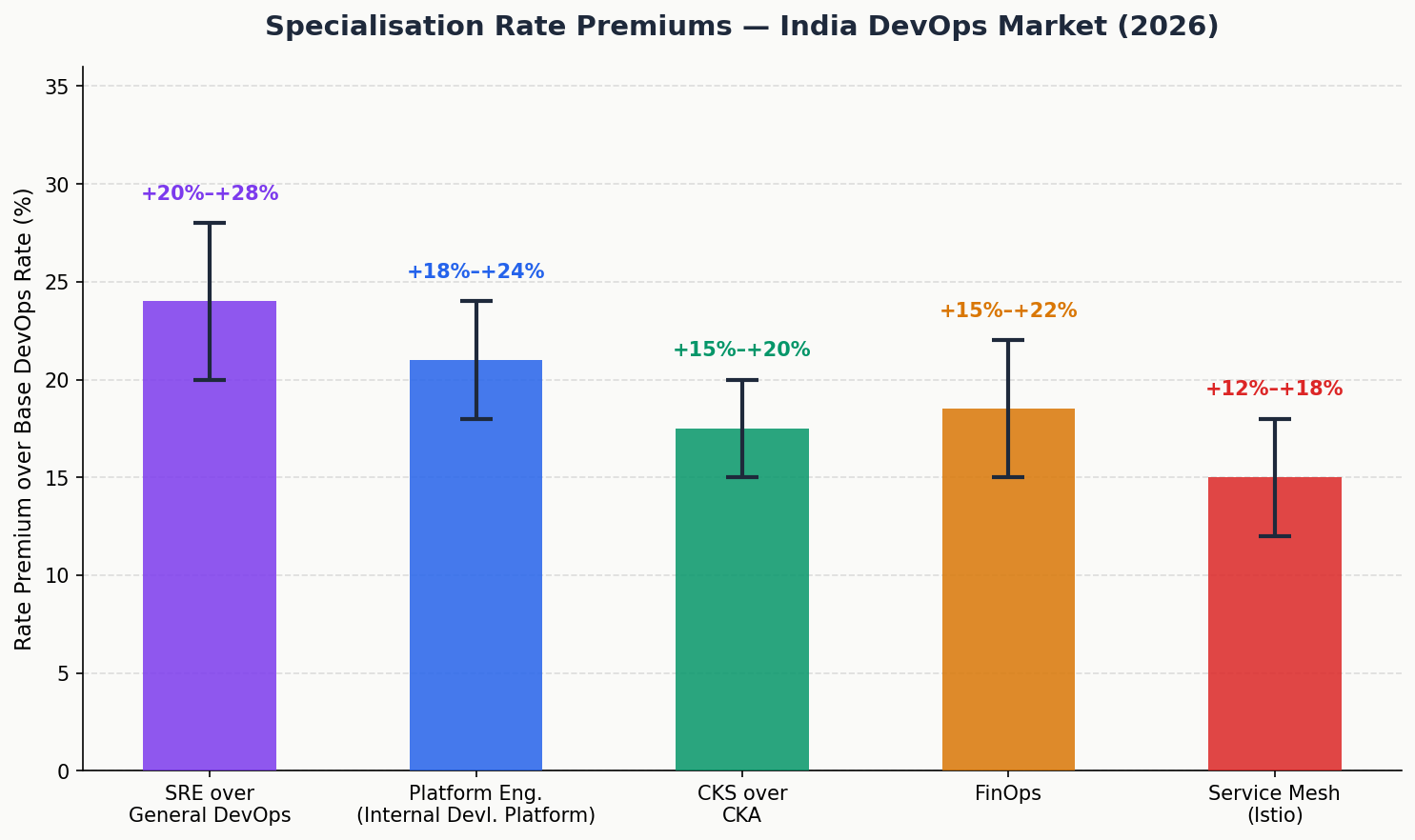
Specialisation premiums:
- SRE over general DevOps: 20–28% premium. SRE SLO design, error budget management, production reliability engineering is a scarcer and more senior discipline.
- Platform Engineering (internal developer platforms): 18–24% premium. Building Backstage portals, golden paths, and self-service infrastructure abstractions requires architectural depth beyond standard DevOps tooling.
- CKS (Kubernetes Security Specialist) over CKS: 15–20% premium. Security-focused Kubernetes is a specialisation within a specialisation.
- FinOps: 15–22% premium. Cloud cost optimization at enterprise scale is increasingly valuable as cloud bills grow.
- Service Mesh (Istio): 12–18% premium. Production Istio at scale is genuinely complex and poorly understood.
The 4 Cost Layers
- Layer 1 Gross CTC Senior DevOps Engineer: ₹26–40 LPA. At ₹96.4/$1: $27K–$41K annually.
- Layer 2 Employer Burden: 22–28%.
- Layer 3 Vendor Margin: 18–23%.
- Layer 4 Invoice Rate: $42–65/hr.
At 2,000 hours/year, a 6-engineer DevOps team at blended $55/hr costs $660K annually. US equivalent: $1.6–1.9M. Annual saving: $940K–$1.2M.
The Skill Hierarchy What Actually Matters
Unlike most stacks in this guide series, DevOps has a publicly verifiable certification ecosystem that provides meaningful signals particularly for Kubernetes and cloud platform roles.
Kubernetes certifications (Linux Foundation / CNCF):
- CKA (Certified Kubernetes Administrator): Performance-based exam candidates administer a live Kubernetes cluster. Tests node management, scheduling, networking, storage, and troubleshooting. The most widely respected Kubernetes credential. Verify at trainingportal.linuxfoundation.org.
- CKAD (Certified Kubernetes Application Developer): Performance-based exam focusing on deploying and managing containerised applications. Developer-focused, less infrastructure-focused than CKA.
- CKS (Certified Kubernetes Security Specialist): Performance-based security-focused exam cluster hardening, security contexts, network policies, audit logging, supply chain security. Requires current CKA. The highest-value Kubernetes credential for security-conscious programs.
All three are performance-based (hands-on in a live cluster) ; they cannot be passed by memorizing answers. They are among the most meaningful technical certifications in this guide series.
Cloud provider certifications:
- AWS: Solutions Architect Professional (SAP) is the senior cloud architecture credential. CKA-equivalent in difficulty and practical relevance. Verify at aws.amazon.com/verification.
- GCP: Professional Cloud Architect is GCP’s senior architecture credential. Verify at cloud.google.com/learn/certification.
- Azure: Solutions Architect Expert (AZ-305) is Azure’s senior architecture credential. Verify at learn.microsoft.com.
Infrastructure-as-Code:
- HashiCorp Certified Terraform Associate: Tests Terraform fundamentals configuration, state, modules, workspaces. Entry to mid-level credential. Verify at www.credly.com (HashiCorp badges).
- HashiCorp Certified Vault Associate / Operations Professional: For secrets management roles.
The tooling vs judgment distinction:
CKA verifies that someone can administer a Kubernetes cluster. It does not verify that they will make the right architecture decisions for your specific production workload namespace design, network policy model, resource quota strategy, node pool architecture, RBAC design. These require production experience and judgment that certification cannot fully assess.
The interview questions in Section 8 test the judgment layer. The certifications verify the foundation layer. Both are required.
The JD That Attracts the Right Candidates
JD 1: Senior DevOps / Platform Engineer Kubernetes + AWS (4–7 years)
Senior DevOps / Platform Engineer Remote from India Engagement: Staff Augmentation | Duration: 12 months, renewable Rate: ₹26–40 LPA CTC equivalent | Billing: $42–65/hr (vendor-facing)
What you’ll own: Build and operate our Kubernetes platform on AWS EKS. You’ll design namespace architecture, configure network policies, build Helm charts for application teams, implement ArgoCD GitOps pipelines, and own Terraform for EKS cluster configuration and supporting AWS infrastructure. Measured on platform reliability (SLO adherence), deployment frequency, and change failure rate.
What we require:
- CKA certification (verified at trainingportal.linuxfoundation.org before interview)
- AWS Solutions Architect Associate or Professional (verified at aws.amazon.com/verification)
- 4–7 years DevOps/platform experience, minimum 2 years running production Kubernetes clusters (not local or development clusters)
- Kubernetes architecture depth: namespace design, RBAC, network policies, resource quotas, HPA/VPA can describe production decisions for each
- Terraform: remote state with locking (S3 + DynamoDB), module design, workspace strategy for multi-environment
- GitOps with ArgoCD: application definition, sync strategies, health checks, rollback
- Observability: Prometheus alerting rules connected to SLOs, not just metric collection
What disqualifies you:
- Kubernetes experience limited to local clusters (minikube/kind) or development environments
- Terraform experience limited to writing Terraform without managing state or modules
- CI/CD pipeline building only (GitHub Actions/Jenkins) without infrastructure engineering
- No production incident experience SRE-like operational experience is required
Interview process: Architecture design exercise (pre-send, 60 min) → Live Kubernetes scenario (90 min, live cluster access) → Production incident walkthrough (45 min)
JD 2: Principal Platform Architect / SRE (10+ years)
Principal Platform Architect / SRE India GCC or BOT Engagement: GCC Build or BOT | Duration: 24+ months CTC: ₹82–118 LPA | Billing: $85–115/hr (vendor-facing)
What you’ll own: Design and build the internal developer platform for our engineering organisation Kubernetes multi-cluster architecture on AWS, Backstage developer portal, golden path templates, SLO framework with error budgets, service mesh with Istio, secrets management with Vault, and the platform engineering standards for a team of 8–12 engineers.
What we require:
- CKA + CKS certifications (both verified before interview)
- AWS Solutions Architect Professional (verified)
- 10+ years infrastructure/platform engineering, minimum 3 internal developer platform or SRE programs as architect of record
- Platform engineering depth Backstage or similar developer portal, golden paths, platform abstractions for application teams
- SRE practice SLO definition methodology, error budget policy, toil reduction framework
- Service mesh at scale Istio production deployment, mTLS configuration, traffic management, observability integration
- Secrets management HashiCorp Vault architecture, dynamic secrets, PKI, integration with Kubernetes
- FinOps experience cloud cost allocation, rightsizing, Reserved Instance / Savings Plan strategy
Interview process: Platform design scenario (60 min) → SLO design exercise (45 min) → FinOps and cost governance discussion (30 min) → Reference call with prior CTO or VP Platform
What most enterprise JDs get wrong for DevOps:
They list every possible tool “Kubernetes, Docker, Jenkins, GitHub Actions, Terraform, Ansible, Prometheus, Grafana, AWS, Azure, GCP, Helm, ArgoCD, Vault, Istio” which signals they don’t know what they need and returns an unfiltered pool. They don’t specify production vs development experience “Kubernetes experience” covers a minikube tutorial and a 1000-node production cluster. They don’t mention SLOs or error budgets which tells SRE-capable engineers the company doesn’t practice SRE. And they don’t specify which cloud AWS EKS is different from GCP GKE is different from Azure AKS in significant ways.
How to Verify Experience Not Just Credentials
The 3 verification steps before any DevOps interview:
Step 1: CKA and cloud certification verification
- CKA: trainingportal.linuxfoundation.org search by candidate name or certification ID
- AWS: aws.amazon.com/verification enter certification validation number
- GCP: cloud.google.com/learn/certification/faq Google credential verification
- HashiCorp: credly.com search for HashiCorp badge
All are publicly verifiable. Do it before scheduling.
Step 2: Production cluster specificity
Ask before scheduling: “What is the largest Kubernetes cluster you’ve run in production node count, pod count, and what cloud provider and Kubernetes version?” Real production engineers answer immediately with specific numbers. Development or learning environment engineers describe clusters conceptually without specific numbers. “48 nodes across 3 node pools on EKS 1.29, approximately 400 pods across 12 namespaces” is a specific answer.
Step 3: Production incident experience
Ask: “Describe the most significant production incident you’ve been involved in, what broke, how you diagnosed it, and what architectural change resulted from it.” Real production engineers have incident stories. They remember specific incidents because they were stressful. Engineers without production experience describe hypothetical incident scenarios or training exercises. The incident story is the single most differentiating pre-screening question for DevOps roles.
The 5 interview questions that expose fake seniority:
Q1: Kubernetes Namespace and Network Policy Architecture “For a multi-team microservices platform on Kubernetes with 8 application teams, 3 environments (dev/staging/prod), and HIPAA compliance requirements design your namespace strategy, RBAC model, and network policy approach.”
Real answer: describes the namespace design decision team-per-namespace vs environment-per-namespace vs hybrid (team-environment combination like payments-prod, payments-staging) with reasoning based on the HIPAA isolation requirements. RBAC: team-scoped ServiceAccounts, team-specific ClusterRoleBindings scoped to their namespaces, separate namespaces for each environment to enforce env-level access control. Network policies: default-deny-all ingress/egress in each namespace, explicit allow rules for required service communication, namespace-level isolation for HIPAA data services. They describe specific Kubernetes resource types NetworkPolicy, RoleBinding, Namespace, LimitRange for resource quotas.
Engineer without production Kubernetes architecture experience describes namespaces conceptually as “logical groupings.” Cannot describe the RBAC model, network policy design, or the HIPAA isolation rationale.
Q2: Terraform State Management “Your team has 3 engineers working on the same Terraform codebase for a production AWS environment. Walk me through your state management architecture and what happens when two engineers apply simultaneously.”
Real answer: describes remote state with S3 bucket + DynamoDB table for state locking. S3 versioning enabled for state history. The DynamoDB lock table prevents concurrent applications; the second engineer’s application is blocked until the first completes. Workspace strategy for environment separation (dev/staging/prod in separate state files). State organisation monorepo vs split repos, module structure, and why they split state (blast radius control infrastructure changes in one module don’t risk state corruption in unrelated modules). Terraform Cloud or Atlantis for PR-based plan/apply workflow in team environments.
Engineer without production Terraform state experience says “we use remote state.” Cannot describe DynamoDB locking mechanics, workspace strategy, or the PR-based workflow for team environments.
Q3: SLO Design and Error Budget “For a payment processing API with a 99.9% availability SLO walk me through how you’d define the SLI, calculate the error budget, and what happens when 50% of the error budget is consumed in week one of a four-week period.”
Real answer: describes the SLI definition availability as measured by successful HTTP responses (2xx and 3xx) divided by total requests, excluding health check traffic. 99.9% availability SLO gives 0.1% error budget 43.8 minutes/month downtime. Error budget consumption rate: 50% in week 1 means 21.9 minutes consumed, 21.9 minutes remaining for the rest of the month.
Response: error budget alert fires at 50% consumption triggering incident review, feature freeze consideration, increased deployment caution, and root cause analysis before further changes. They describe the Prometheus recording rules and Grafana dashboard for error budget tracking.
Engineers without SRE practice describe SLOs as “uptime targets.” Cannot describe SLI measurement methodology, error budget calculation, or the error budget policy response.
Q4: GitOps Deployment Architecture “Describe how you’ve implemented GitOps with ArgoCD for a 20-service microservices application, the repository structure, the sync strategy for production deployments, and how you handle secrets without storing them in Git.”
Real answer: describes the repository structure app-of-apps pattern (one ArgoCD Application per service, a parent Application managing all children) or monorepo with Helm charts per service. Sync strategy for production: manual sync (requires human approval) vs automated sync with auto-prune and self-heal disabled (prevent accidental deletions in prod). Secrets management: External Secrets Operator with secrets stored in AWS Secrets Manager or HashiCorp Vault, synced to Kubernetes Secrets by the operator secrets never stored in Git. Or Sealed Secrets for encrypted secrets safe to commit to Git. They describe specific ArgoCD resource types Application, ApplicationSet and the sync options.
An engineer without ArgoCD production experience describes GitOps as “deploying from Git.” Cannot describe the app-of-apps pattern, production sync strategy considerations, or the secrets management approach.
Q5: Production Incident Diagnosis “You receive an alert: P95 latency for the checkout service has spiked from 200ms to 4 seconds over the last 10 minutes. Walk me through your diagnostic process.”
Real answer: a structured incident diagnosis check the service’s pod health (kubectl get pods, kubectl describe pod for events), check recent deployments (ArgoCD history, Kubernetes rollout history), check resource consumption (kubectl top pods is the service CPU or memory constrained?)check the service’s dependency health (is the database, cache, or downstream service causing the latency?)check Prometheus for the specific latency increase (P95 vs P50 is it all requests or tail latency?), check distributed traces (Jaeger/Zipkin) to identify which component in the request path is slow. They have a systematic process, use specific tools, and can articulate where they’d look first based on the symptom pattern.
Engineer without production incident experience describes a generic “check the logs” approach. Cannot describe a systematic diagnosis process using specific Kubernetes, Prometheus, and tracing tooling.
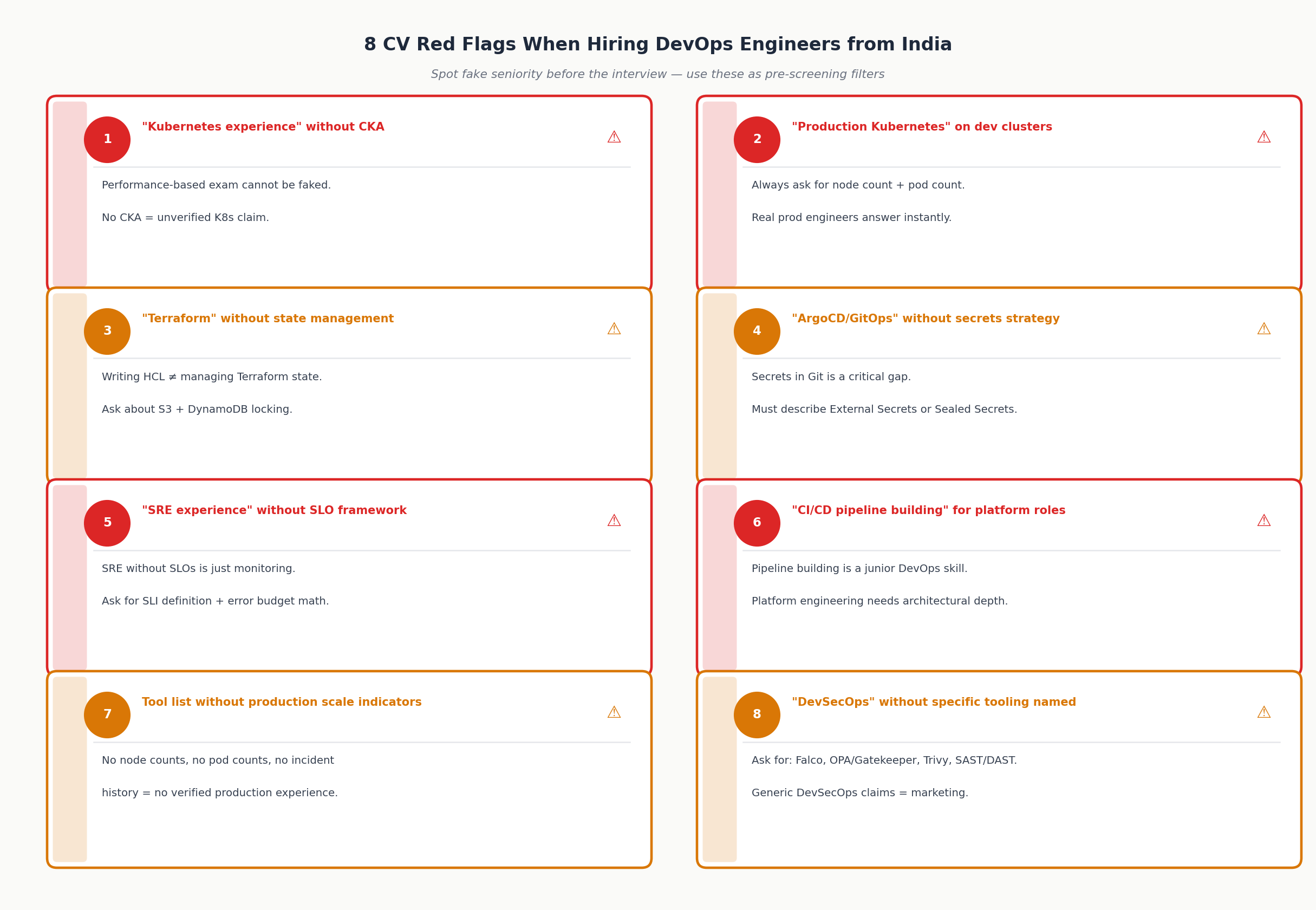
8 CV red flags:
- “Kubernetes experience” without CKA the performance-based exam is the meaningful filter
- “Production Kubernetes” that was actually a development or staging cluster ask for node count
- “Terraform experience” that is limited to writing HCL without state management knowledge
- “ArgoCD/GitOps” experience without being able to describe secrets management in Git the most common GitOps gap
- “SRE experience” without being able to define their SLI/SLO/error budget framework SRE without SLOs is just monitoring
- “CI/CD pipeline building” for a platform engineering role pipeline building is one component, not the whole discipline
- Tool list without production scale indicators no node counts, no pod counts, no team size, no incident history
- “DevSecOps” claimed without specific security tooling Falco, OPA/Gatekeeper, Trivy, SAST/DAST generic DevSecOps claims are usually marketing
How to Source What’s Working, What Isn’t
What’s working:
CNCF (Cloud Native Computing Foundation) community.
India has a strong CNCF community KubeCon India, Cloud Native India meetups, and the CNCF Ambassador program. Indian CNCF Ambassadors are identifiable senior practitioners with verifiable community contributions. The KubeCon India attendee and speaker community is the highest-quality DevOps sourcing channel in the country.
GitHub contributions.
Senior platform engineers in India contribute to open-source projects Kubernetes operators, Terraform providers, Helm charts, or CNCF-graduated projects. GitHub profiles with meaningful contributions to infrastructure projects are a strong signal of genuine depth.
3 ready-to-use LinkedIn boolean search strings:
- String 1 (Senior Platform Engineer): “Kubernetes” AND (“CKA” OR “platform engineering” OR “SRE”) AND (“production” OR “EKS” OR “GKE”) AND (“Senior” OR “Lead”) AND “Bangalore”
- String 2 (SRE / Reliability): “SRE” AND (“SLO” OR “error budget” OR “reliability”) AND (“Kubernetes” OR “AWS”) AND “India”
- String 3 (IaC / Terraform): “Terraform” AND (“HashiCorp” OR “remote state” OR “modules”) AND (“AWS” OR “GCP” OR “Azure”) AND (“Lead” OR “Senior”) AND (“Bangalore” OR “Hyderabad”)
Product company alumni networks.
Engineers who have worked at Indian product companies at scale: Flipkart, Swiggy, Zepto, Razorpay, Zerodha, Meesho have operated production systems at volumes that most enterprises don’t reach. Their DevOps and platform engineering experience is inherently production-validated.
Supersourcing pre-vetted bench. Senior DevOps Engineers (CKA + cloud cert, production cluster experience): 20-day median fill. Platform Architects (SRE + platform engineering): 30 days.
What isn’t working:
“DevOps engineer” postings listing 15+ tools.
Returns the broadest possible pool. Every junior engineer who has completed a DevOps bootcamp lists every tool on the list. Specificity which cloud, which orchestration, which observability stack, production scale requirement reduces pool size and dramatically increases quality.
Treating CI/CD pipeline builders as platform engineers.
Building GitHub Actions pipelines is a valuable but relatively junior DevOps skill. Platform engineering designing the Kubernetes platform, the service mesh, the developer portal, the SLO framework is a senior discipline. These require different sourcing and different interview processes.
Kubernetes certifications as the only filter.
CKA verifies cluster administration competence. It does not verify production architecture judgment. The interview questions in Section 8 are required alongside certification verification.
The Contract Stack for DevOps Engagements
Clause 1: Individual Resource Approval with Certification Verification and Production Experience Declaration
SOW schedule: name, CKA/CKS/cloud cert verification links, production cluster specificity (cloud provider, node count, team size), and primary specialisation (Kubernetes/IaC/SRE/Platform). Production experience declaration not just certification as a contractual specification.
Clause 2: IP Assignment Terraform Modules, Helm Charts, ArgoCD Applications, Pipeline Templates
Must cover: Terraform module code and state configuration, Helm chart definitions, ArgoCD Application manifests, GitHub Actions/GitLab CI pipeline templates, Prometheus alerting rules and recording rules, Grafana dashboard definitions (JSON), and Backstage catalog definitions if in scope. All are valuable platform IP.
Clause 3: Infrastructure Documentation as Delivery Requirement
Every infrastructure component built must be documented architecture decision records (ADRs) for major decisions, runbooks for operational procedures, and README files for all Terraform modules and Helm charts. Undocumented infrastructure is a knowledge risk at engagement end. Require documentation as a per-sprint acceptance criterion.
Clause 4: Production Credentials Access Controls
Define which production credentials the offshore team can access cloud provider IAM roles with least-privilege permissions, Kubernetes service accounts scoped to their operational needs, and secrets management access limited to their required secrets paths. Require a credentials audit at engagement and all offshore engineer credentials revoked, IAM roles reviewed, Kubernetes RBAC cleaned up.
Clause 5: SLO Definition as Early Milestone
For SRE programs, require SLO definitions for all critical services as a Month 1 milestone not a Month 12 deliverable. SLOs without error budgets and error budgets without alert policies are not complete SLO implementations. Define the acceptance criteria for SLO completeness (SLI definition, SLO target, error budget calculation, Prometheus rules, Grafana dashboard, alert to on-call) before the engagement starts.
Running a DevOps Team at Scale
Infrastructure as code from day one.
No manually created infrastructure. Every AWS/GCP/Azure resource created by the engagement team must be defined in Terraform and applied through a CI/CD pipeline not through the console. Manual console changes are technical debt that becomes invisible and unmanageable. Enforce this as a policy, not a preference.
Runbook culture.
Every operational procedure cluster upgrades, certificate rotation, incident response for specific alert types, node draining and replacement must have a runbook. Runbooks written during the engagement are institutional knowledge that remains when the offshore team’s engagement ends. Without runbooks, the knowledge leaves with the team.
On-call knowledge transfer.
If the offshore team will be involved in on-call rotation, require structured on-call knowledge transfer before any offshore engineer takes on-call shadowing existing on-call for two weeks, reviewing all existing runbooks, and conducting a simulated incident response exercise. On-call without preparation is how incidents become outages.
Cost review cadence.
Monthly cloud cost review against budget, with attribution to teams and services. Use cloud-native cost allocation (AWS Cost Explorer tags, GCP labels, Azure tags) and require the offshore team to maintain tag compliance every resource tagged with team, environment, and service owner. Cost accountability without attribution is impossible.
Early warning signals:
- Manually created infrastructure appearing in cloud console (CloudTrail/Audit Logs show manual changes)
- Terraform state drift detected (terraform plan showing unexpected changes)
- Prometheus alerts firing but not connected to runbooks or on-call
- Error budget consumption not being tracked or reviewed
- LinkedIn activity cloud certifications updated, connections from FAANG companies increasing
Retention levers: Kubernetes version and feature currency engineers working on the latest EKS/GKE version with new Kubernetes features (Gateway API, KEP implementations) are building current market credentials. CNCF certification progression CKA to CKS sponsorship, then potentially KCNA (Kubernetes and Cloud Native Associate) for the broader ecosystem. Open-source contribution support engineers who contribute to CNCF projects on company time have a public professional identity that anchors them to the organisation that enabled it.
When Things Go Wrong
Pattern 1: The Wrong Architecture
Described in Section 1. Correct tooling, wrong architectural decisions. Network policies missing, Terraform state without locking, Recreate deployment strategy causing downtime, metrics without SLOs. The architecture judgment questions in Section 8 (Q1 through Q5) assess the decision-making layer that certification alone doesn’t verify.
Pattern 2: The Terraform State Corruption
A UK financial services company’s offshore DevOps team ran Terraform from individual laptops without remote state locking. Two engineers applied simultaneously, one running a plan that modified security group rules, another running a plan that modified EC2 instance configurations. The concurrent application corrupted the Terraform state. Recovery required 6 hours of state file reconstruction from AWS CloudTrail logs.
The fix: Terraform Cloud for state management with locking, enforced policy requiring CI/CD-only Terraform applies, no manual applies from laptops in any environment above development. The Terraform state management question (Q2 in Section 8) and the “no manual infrastructure” policy in Section 11 would have prevented this.
Pattern 3: The SLO Theater
A US media company’s SRE program produced 48 Prometheus alerts and 12 Grafana dashboards. None of them were connected to SLOs. The alerts fired based on metric thresholds that had no relationship to user experience. Alert fatigue set in engineers stopped responding to alerts because most were noise. A critical database replication lag that would have caused data loss went undetected for 4 hours because the relevant alert had been silenced two weeks earlier as part of reducing alert noise.
The SLO design question (Q3 in Section 8) and the SLO definition as Month 1 milestone in the contract would have established user-impact-connected alerting from the start.
When India Is the Wrong Call
Scenario 1: On-call programs requiring sub-1-hour response during US business hours.
For production systems where on-call incidents require a response within 30–60 minutes during US afternoon hours (3pm–6pm EST = India midnight–3am IST), India-based engineers are operationally impractical without structured late-shift arrangements (which add 20–30% to the rate). For US West Coast programs requiring real-time incident response, consider EMEA or Americas-based SRE for the on-call rotation with India-based engineers for the development and automation work.
Scenario 2: US federal cloud infrastructure programs.
US federal infrastructure (FedRAMP, DoD IL4/IL5) requires US citizen engineers with specific security clearances. India-based engineers cannot hold US security clearances. For federal cloud programs, the DevOps and platform engineering work must be done by cleared US-based engineers.
Scenario 3: Extremely early-stage startup platform work.
For a 10-person startup where the “DevOps program” is setting up a basic CI/CD pipeline, one Kubernetes cluster, and Terraform for 20 AWS resources the economics and governance overhead of enterprise offshore staffing don’t apply. A single senior DevOps contractor with a day rate is more appropriate than a staffing engagement.
The Supersourcing Vendor Scorecard™ DevOps Edition
Score your vendor before signing. Maximum 100 points. Minimum threshold: 65.
Category 1: Production Verification (0–20 pts)
| Criterion | 0 | 10 | 20 |
| CKA + cloud cert verified for all claimed senior engineers within 24 hours | Cannot | Some | All, all certs verified |
| Production cluster specificity confirmed (node count, cloud, version) | Not verified | Claimed | Specific numbers confirmed |
| Incident experience verified (specific incident described) | Not asked | Claimed | Named incident and architectural outcome |
Category 2: Technical Vetting (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Architecture judgment tested (not tool knowledge only) | Tool knowledge only | Some architecture | Production design scenario required |
| Production incident walkthrough required | Not required | Optional | Mandatory for senior+ |
| SLO/SRE knowledge tested for reliability roles | Not tested | Conceptual | Error budget calculation required |
Category 3: Contract Readiness (0–20 pts)
| Criterion | 0 | 10 | 20 |
| IP Assignment covering Terraform modules, Helm charts, ArgoCD manifests | Not available | On request | Standard, items named |
| Infrastructure documentation as acceptance criteria | Not required | Best effort | Per-sprint ADR and runbook requirement |
| SLO definition as Month 1 milestone for SRE programs | Not present | Best effort | Contractual milestone with acceptance criteria |
Category 4: DevOps Delivery Track Record (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Named production platform programs with scale indicators | None | Logo only | Named contact + node count + team size |
| SRE / SLO programs verified | None | Claimed | SLO framework and error budget confirmed |
| Attrition on DevOps programs | Unknown / >25% | 18–25% | <18% |
Category 5: Commercial Structure (0–20 pts)
| Criterion | 0 | 10 | 20 |
| Rate card by specialisation (Kubernetes vs SRE vs Platform Eng vs IaC) | Single DevOps rate | Senior/junior distinction | Full specialisation matrix |
| Substitution clause with certification equivalence | Not present | Available | Standard, CKA equivalence specified |
| SLA on replacement 14 days | None | Best effort | Contractual 14-day SLA |
Score interpretation: 85–100 shortlist; 65–84 proceed with conditions; 45–64 significant risk; below 45 walk.
15 Questions Buyers Actually Ask
Q: What is the difference between DevOps and Platform Engineering?
DevOps is a philosophy and practice of unifying development and operations, automating deployments, shortening release cycles, and improving feedback loops. DevOps engineers typically focus on CI/CD pipelines, deployment automation, and infrastructure management. Platform Engineering is a more recent discipline that treats the internal developer platform as a product building the Kubernetes clusters, service meshes, developer portals (Backstage), golden path templates, and self-service infrastructure abstractions that application teams consume. Platform engineers build what DevOps engineers use. Platform engineering is the senior career path. For enterprise programs, define which you need: deployment automation (DevOps) or internal platform products (Platform Engineering).
Q: What is SRE and when do I need it?
Site Reliability Engineering (SRE) is Google’s approach to managing production reliability through software engineering. SREs define Service Level Objectives (SLOs) the reliability targets for each service and manage error budgets (the allowed downtime within the SLO). When the error budget is consumed, SREs prioritise reliability work over feature work. SRE practice requires: SLI/SLO definition, error budget calculation, Prometheus-based error budget tracking, and an error budget policy defining what happens at different consumption thresholds. You need SRE when: your services have meaningful uptime requirements for users, you want an objective mechanism for balancing feature velocity against reliability, and you have enough engineering maturity to define and measure service reliability. For early-stage teams, basic alerting and on-call is sufficient before SRE formalism.
Q: What is Kubernetes and why is it so widely required?
Kubernetes is the dominant container orchestration platform that manages the deployment, scaling, and operation of containerised applications across a cluster of machines. It handles service discovery, load balancing, storage provisioning, secret management, and automated rollouts and rollbacks. Kubernetes is widely required because containerisation has become standard for microservices architectures, and Kubernetes is the de facto orchestrator for containers at enterprise scale. The CKA exam (performance-based, hands-on in a live cluster) is the most meaningful Kubernetes credential for verifying genuine competence.
Q: What is GitOps and how is it different from traditional CI/CD?
GitOps is an operational model where Git is the single source of truth for infrastructure and application configuration. A GitOps tool (ArgoCD, Flux) continuously reconciles the live cluster state to match the desired state defined in Git. If someone manually changes a Kubernetes resource, the GitOps tool reverts it to the Git-defined state. Traditional CI/CD pushes changes to the cluster (push model). GitOps pulls changes from Git into the cluster (pull model). GitOps provides stronger auditability (every change is a Git commit), easier rollback (revert the Git commit), and better drift detection (the GitOps tool alerts when live state diverges from Git).
Q: How do I control cloud infrastructure costs for an offshore DevOps team?
Four mechanisms: tagging enforcement (every resource tagged with team, environment, service no tags, no deploy), resource monitor alerts (AWS Budgets, GCP Budget Alerts alert at 80% of monthly budget, stop at 110%), rightsizing automation (AWS Compute Optimizer, GCP Recommender identify over-provisioned resources), and Reserved Instance/Savings Plan coverage (1-year or 3-year commitments for stable workloads reduce cost by 30–72%). Require the offshore team to maintain >95% tagging compliance and produce a monthly cost attribution report. Cost accountability without attribution is impossible.
Q: What is Terraform and why is it important?
Terraform is HashiCorp’s infrastructure-as-code tool that defines cloud infrastructure (AWS EC2 instances, S3 buckets, VPCs, Kubernetes clusters) as code that can be version-controlled, reviewed, and applied consistently. Terraform state tracks what infrastructure has been created. Remote state with locking (S3 + DynamoDB for AWS) prevents concurrent applications from corrupting the state. Terraform modules enable reusable infrastructure components. For any serious infrastructure program, Terraform (or an equivalent IaC tool) is the standard manual console-based infrastructure management that is not scalable, auditable, or reproducible.
Q: What is the realistic timeline to build a 8-person DevOps team in India?
For a team covering Kubernetes, IaC, CI/CD, and observability 1 platform architect, 3 senior DevOps engineers, 3 mid-level engineers, 1 SRE expect 35–50 days from JD sign-off to full team assembled. The platform architect (30-day median fill) is the critical path. Senior DevOps engineers (20-day median fill) can be sourced in parallel. Production experience verification adds 3–4 days to the standard sourcing timeline.
Q: What is a service mesh and do I need one?
A service mesh (Istio, Linkerd, Cilium) provides network-level control between microservices mutual TLS (mTLS) for service-to-service encryption, traffic management (canary deployments, A/B testing, circuit breaking), and distributed tracing. You need a service mesh when: you have 20+ microservices and need consistent mTLS without application code changes, you need fine-grained traffic management for canary deployments, or you have compliance requirements for encrypted service-to-service communication. For smaller deployments, the operational complexity of Istio (the most common service mesh) exceeds the benefit. Service mesh is a senior platform engineering topic requiring production Istio experience in the interview for any service mesh program.
Q: Is India-based DevOps talent comparable to US talent?
For CI/CD automation, Kubernetes cluster administration, Terraform infrastructure management, and observability setup: functionally equivalent at senior level. India’s product company ecosystem: Flipkart, Swiggy, Razorpay, Zerodha has produced a generation of platform engineers who have operated systems at genuine scale. For bleeding-edge platform engineering Kubernetes Gateway API, eBPF-based networking (Cilium), Wasm-based serverless on Kubernetes the US-based CNCF community has earlier adoption and more production experience. For standard enterprise platform engineering: India talent delivers at global quality standards.
Q: What’s the hardest DevOps profile to hire in India?
A Principal Platform Architect with CKA + CKS, production Backstage internal developer platform delivery, Istio service mesh at scale (100+ services), HashiCorp Vault architecture, SLO framework design with error budget policy, and FinOps practice at enterprise scale. This combination narrows the India pool to under 300 active practitioners. Median fill time: 42+ days. Competition from FAANG and unicorn GCCs in Bangalore for the same profiles.
Q: Is Supersourcing the right partner for a 3-engineer DevOps program?
Not our ideal engagement. For 3 engineers on a defined DevOps scope, a platform engineering specialist or direct contract hires with CKA and cloud certifications are a better fit. We’d rather tell you that.
Closing
DevOps and platform engineering hiring from India works. The production-capable engineers exist CKA-certified, cloud-architecture-certified, incident-experienced, SLO-aware. The savings versus US hiring are real $114K to $337K per engineer per year.
The failure mode is not India. It is “DevOps engineer required” without defining the specific production problem being solved and the architecture judgment required to solve it. The CKA exam takes 2 hours in a live cluster; it cannot be faked. The production cluster specificity question takes 30 seconds. The incident walkthrough takes 15 minutes. These three filters eliminate the tool-aware-but-inexperienced pool before a single interview is scheduled.
Every enterprise program needs platform engineering. Almost none of them write a guide for it. Now you have one.
Book a 30-minute Platform Engineering Talent Discovery Call → No deck. Just the numbers and the bench.
